Japan’s Fastest Supercomputer Adopts NGC, Enabling Easy Access to Deep Learning Frameworks
From discovering drugs, to locating black holes, to finding safer nuclear energy sources, high performance computing systems around the world have enabled breakthroughs across all scientific domains.
Japan’s fastest supercomputer, ABCI, powered by NVIDIA Tensor Core GPUs, enables similar breakthroughs by taking advantage of AI. The system is the world’s first large-scale, open AI infrastructure serving researchers, engineers and industrial users to advance their science.
The software used to drive these advances is as critical as the servers the software runs on. However, installing an application on an HPC cluster is complex and time consuming. Researchers and engineers are unproductive as they wait to access the software, and their requests to have applications installed distract system admins from completing mission-critical tasks.
Containers — packages that contain software and relevant dependencies — allow users to pull and run the software on a system without actually installing the software. They’re a win-win for users and system admins.
NGC: Driving Ease of Use of AI, Machine Learning and HPC Software
NGC offers over 50 GPU-optimized containers for deep learning frameworks, machine learning algorithms and HPC applications that run on both Docker and Singularity.
The HPC applications provide scalable performance on GPUs within and across nodes. NVIDIA continuously optimizes key deep learning frameworks and libraries, with updates released monthly. This provides users access to top performance for training and inference for all their AI projects.
ABCI Runs NGC Containers
Researchers and industrial users are taking advantage of ABCI to run AI-powered scientific workloads across domains, from nuclear physics to manufacturing. Others are taking advantage of the system’s distributed computing to push the limits on speeding AI training.
To achieve this, the right set of software and hardware tools must be in place, which is why ABCI has adopted NGC.
“Installing deep learning frameworks from the source is complicated and upgrading the software to keep up with the frequent releases is a resource drain,” said Hirotaka Ogawa, team leader of the Artificial Intelligence Research Center at AIST. “NGC allows us to support our users with the latest AI frameworks and the users enjoy the best performance they can achieve on NVIDIA GPUs.”
ABCI has turned to containers to address another user need — portability.
“Most of our users are from industrial segments who are looking for portability between their on-prem systems and ABCI,” said Ogawa. “Thanks to NGC and Singularity, the users can develop, test, and deploy at scale across different platforms. Our sampling data showed that NGC containers were used by 80 percent of the over 100,000 jobs that ran on Singularity.”
NGC Container Replicator Simplifies Ease of Use for System Admins and Users
System admins managing HPC systems at supercomputing centers and universities can now download and save NGC containers on their clusters. This gives users faster access to the software, alleviates their network traffic, and saves storage space.
NVIDIA offers NGC Container Replicator, which automatically checks and downloads the latest versions of NGC containers.
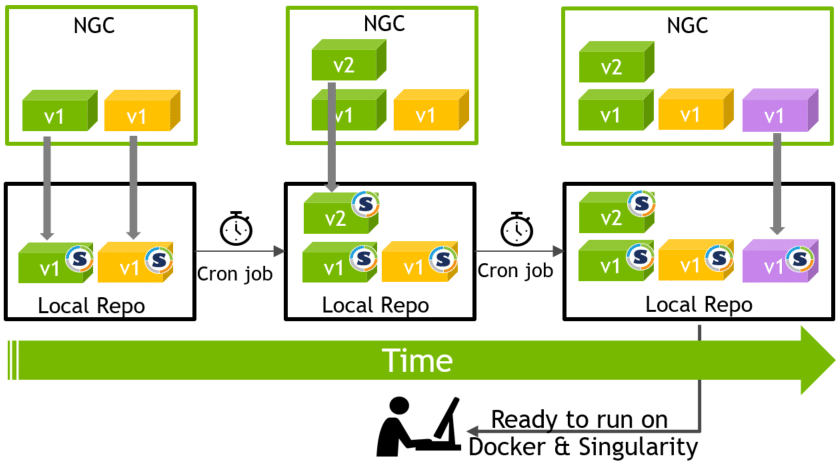
Without lifting a finger, system admins can ensure that their users benefit from the superior performance and newest features from the latest software.
More Than Application Containers
In addition to deep learning containers, NGC hosts 60 pre-trained models and 17 model scripts for popular use cases like object detection, natural language processing and text to speech.
It’s much faster to tune a pre-trained model for a use case than to start from scratch. The pre-trained models allow researchers to quickly fine-tune a neural network or build on top of an already optimized network for specific use-case needs.
The model training scripts follow best practices, have state-of-the-art accuracy and deliver superior performance. They’re ideal for researchers and data scientists planning to build a network from scratch and customize it to their liking.
The models and scripts take advantage of mixed precision powered by NVIDIA Tensor Core GPUs to deliver up to 3x deep learning performance speedups over previous generations.
Take NGC for a Spin
NGC containers are built and tested to run on-prem and in the cloud. They also support hybrid as well as multi-cloud deployments. Visit ngc.nvidia.com, pull your application container on any GPU-powered system or major cloud instance, and see how easy it is to get up and running for your next scientific research.
The post Japan’s Fastest Supercomputer Adopts NGC, Enabling Easy Access to Deep Learning Frameworks appeared first on The Official NVIDIA Blog.




 Tomasz Stachlewski is a Solutions Architect at AWS, where he helps companies of all sizes (from startups to enterprises) in their cloud journey. He is a big believer in innovative technology, such as serverless architecture, which allows companies to accelerate their digital transformation.
Tomasz Stachlewski is a Solutions Architect at AWS, where he helps companies of all sizes (from startups to enterprises) in their cloud journey. He is a big believer in innovative technology, such as serverless architecture, which allows companies to accelerate their digital transformation. Rick Mitchell is a Senior Product Marketing Manager with AWS AI. His goal is to help aspiring developers to get started with Artificial Intelligence. For fun outside of work, Rick likes to travel with his wife and two children, barbecue, and run outdoors.
Rick Mitchell is a Senior Product Marketing Manager with AWS AI. His goal is to help aspiring developers to get started with Artificial Intelligence. For fun outside of work, Rick likes to travel with his wife and two children, barbecue, and run outdoors.

 Satadal Bhattacharjee is Principal Product Manager with AWS AI. He leads the Machine Learning Engine PM team working on projects such as SageMaker Neo, AWS Deep Learning AMIs, and AWS Elastic Inference. For fun outside work, Satadal loves to hike, coach robotics teams, and spend time with his family and friends.
Satadal Bhattacharjee is Principal Product Manager with AWS AI. He leads the Machine Learning Engine PM team working on projects such as SageMaker Neo, AWS Deep Learning AMIs, and AWS Elastic Inference. For fun outside work, Satadal loves to hike, coach robotics teams, and spend time with his family and friends. Kimberly Madia is a Principal Product Marketing Manager with AWS Machine Learning. Her goal is to make it easy for customers to build, train, and deploy machine learning models using Amazon SageMaker. For fun outside work, Kimberly likes to cook, read, and run on the San Francisco Bay Trail.
Kimberly Madia is a Principal Product Marketing Manager with AWS Machine Learning. Her goal is to make it easy for customers to build, train, and deploy machine learning models using Amazon SageMaker. For fun outside work, Kimberly likes to cook, read, and run on the San Francisco Bay Trail.