Category: Global
How AI can help save lives in emergencies
The post How AI can help save lives in emergencies appeared first on The AI Blog.
Learning Better Simulation Methods for Partial Differential Equations
The world’s fastest supercomputers were designed for modeling physical phenomena, yet they still are not fast enough to robustly predict the impacts of climate change, to design controls for airplanes based on airflow or to accurately simulate a fusion reactor. All of these phenomena are modeled by partial differential equations (PDEs), the class of equations that describe everything smooth and continuous in the physical world, and the most common class of simulation problems in science and engineering. To solve these equations, we need faster simulations, but in recent years, Moore’s law has been slowing. At the same time, we’ve seen huge breakthroughs in machine learning (ML) along with faster hardware optimized for it. What does this new paradigm offer for scientific computing?
In “Learning Data Driven Discretizations for Partial Differential Equations”, published in Proceedings of the National Academy of Sciences, we explore a potential path for how ML can offer continued improvements in high-performance computing, both for solving PDEs and, more broadly, for solving hard computational problems in every area of science.
For most real-world problems, closed-form solutions to PDEs don’t exist. Instead, one must find discrete equations (“discretizations”) that a computer can solve to approximate the continuous PDE. Typical approaches to solve PDEs represent equations on a grid, e.g., using finite differences. To achieve convergence, the mesh spacing of the grid needs to be smaller than the smallest feature size of the solutions. This often isn’t feasible because of an unfortunate scaling law: achieving 10x higher resolution requires 10,000x more compute, because the grid must be scaled in four dimensions—three spatial dimensions and time. Instead, in our paper we show that ML can be used to learn better representations for PDEs on coarser grids.
 |
| Satellite photo of a hurricane, at both full resolution and simulated resolution in a state of the art weather model. Cumulus clouds (e.g., in the red circle) are responsible for heavy rainfall, but in the weather model the details are entirely blurred out. Instead, models rely on crude approximations for sub-grid physics, a key source of uncertainty in climate models. Image credit: NOAA |
The challenge is to retain the accuracy of high-resolution simulations while still using the coarsest grid possible. In our work we’re able to improve upon existing schemes by replacing heuristics based on deep human insight (e.g., “solutions to a PDE should always be smooth away from discontinuities”) with optimized rules based on machine learning. The rules our ML models recover are complex, and we don’t entirely understand them, but they incorporate sophisticated physical principles like the idea of “upwinding”—to accurately model what’s coming towards you in a fluid flow, you should look upstream in the direction the wind is coming from. An example of our results on a simple model of fluid dynamics are shown below:
 |
| Simulations of Burgers’ equation, a model for shock waves in fluids, solved with either a standard finite volume method (left) or our neural network based method (right). The orange squares represent simulations with each method on low resolution grids. These points are fed back into the model at each time step, which then predicts how they should change. Blue lines show the exact simulations used for training. The neural network solution is much better, even on a 4x coarser grid, as indicated by the orange squares smoothly tracing the blue line. |
Our research also illustrates a broader lesson about how to effectively combine machine learning and physics. Rather than attempting to learn physics from scratch, we combined neural networks with components from traditional simulation methods, including the known form of the equations we’re solving and finite volume methods. This means that laws such as conservation of momentum are exactly satisfied, by construction, and allows our machine learning models to focus on what they do best, learning optimal rules for interpolation in complex, high-dimensional spaces.
Next Steps
We are focused on scaling up the techniques outlined in our paper to solve larger scale simulation problems with real-world impacts, such as weather and climate prediction. We’re excited about the broad potential of blending machine learning into the complex algorithms of scientific computing.
Acknowledgments
Thanks to co-authors Yohai Bar-Sinari, Jason Hickey and Michael Brenner; and Google collaborators Peyman Milanfar, Pascal Getreur, Ignacio Garcia Dorado, Dmitrii Kochkov, Jiawei Zhuang and Anton Geraschenko.

Life Imitating Art: AI Startup Resembles Pied Piper in HBO’s Silicon Valley
Like Silicon Valley’s plot on fictional startup Pied Piper, Compression AI is a scrappy team of developers working on media-compression technology in a tech incubator.
Except instead of being characters in a Hollywood-scripted startup, founders Francis Doumet and Migel Tissera met at a Vancouver coworking space, hired two employees and pulled late nighters to release their first beta software, dubbed PixelDrive.
Founded in 2018, Compression AI aims to enable faster transmission of media files over the web, even on low-quality internet networks.
It reduces image file sizes up to 80 percent using the company’s neural compression technology, the product of the team’s custom work on convolutional neural networks trained on NVIDIA GPUs.
Doumet and Tissera initially launched PixelDrive as a consumer product. But they soon figured out that the underlying technology is much more valuable to developers because image compression enables faster web page load times and increases search engine rankings. They have since made the technology available as an API for developers.
Doumet and Tissera’s ultimate goal is to bring their technology to video compression. That’s because Tissera — a fan of watching UFC mixed martial arts fights but frustrated with choppy broadcasts — sees a need for improvement in video compression, especially where the internet quality is suboptimal.
Compression AI is a member of NVIDIA Inception, a virtual accelerator program that helps startups get to market faster.
Compressed Launch Date
The neural networks that run the developer API and PixelDrive were trained on the entire ImageNet set of images and many more that were collected from the web, totaling more than 10 million images, Doumet said.
The Compression AI team designed the neural networks, which focused on the part of CNNs known as auto-encoders, he said. The development allowed Compression AI to come up with the optimal image compression for each individual image down to the pixel, according to the company.
The deployed service is powered by NVIDIA P4 GPUs performing inference in the cloud. “We’re best in class in terms of image compression,” said Doumet.
Neural network training was also fast on desktop PCs running NVIDIA GPUs.
Online Business Applications
Improved image compression has potentially big implications for businesses. The startup has multiple pilot tests with companies exploring the benefits.
One is with a major online real estate site. Sites like these rank higher in Google searches if they load faster from better compression of images, said Doumet.
Another is video game apps because lighter file sizes from image compression get lower bounce rates at the time of download.
And online retailers are exploring pilots to get better sales results from fast load times of pages, according to Doumet.
Coming Attraction: Video
Compression AI is focused on launching compression for video next.
Doumet and Tissera say that even with advances in 4G and the promise of 5G, mobile internet remains bandwidth constrained. For instance, a four-minute video shot in 4K on a mobile device takes roughly 13 minutes to transmit over the average U.S. internet connection.
“Advances in AI create an opportunity to develop more intelligent kinds of codecs that can adapt and optimize for any image to offer a reduced footprint in file size,” said Doumet.
Image license and credit: Creative Commons; photo by @noisytoy.net
The post Life Imitating Art: AI Startup Resembles Pied Piper in HBO’s Silicon Valley appeared first on The Official NVIDIA Blog.
Digging deep and solving problems: Well Data Labs applies machine learning to oil and gas challenges
When CEO Josh Churlik co-founded Well Data Labs in 2014, he was acutely aware of a bizarre dichotomy in his industry: For oil and gas companies, “downhole” innovation (that is, what happens underground) far exceeds the pace of data and analysis innovation. The data systems used then were relics of the 1990s – more homages to history than helpful to the people who needed them.
Like many others in the industry, Josh and the Well Data Labs team were frustrated with the inability to access information that would have made frontline engineers’ jobs much easier. While the industry plodded along with spreadsheets, Churlik and his team saw an opportunity to build a modern software company around the rapid advancements in cloud computing.
The resulting company, Well Data Labs, describes itself as “a modern web application built to give operators the fastest and simplest way to manage, analyze, and report on their internal data.” In other words, Well Data Labs efficiently handles the messy time-series data created during operations—capturing, normalizing, structuring, and enabling analysis on that data—all within a web-based app.
With what Well Data Labs offers, engineers can make faster, more informed decisions—decisions that have a direct and immediate impact on the cost and success of the operations. The company has replaced manual front-end data collection and analysis with custom-developed machine learning (ML) models running on AWS, so that Well Data Labs’ customers can monitor field operations in real-time.
The AWS tech stack powers this solution. Churlik explained, “When we were getting started, we did a bakeoff between other cloud providers and AWS. Even though we’re a .NET stack and SQL database, AWS was significantly more performant.” So, AWS was their choice; to this day, Well Data Labs uses AWS for all their cloud needs. “What we’ve liked about AWS is we can always scale. We’ve been able to continuously build and grow,” Churlik added. “AWS was and still is ahead of its industry peers on technology services.”
Well Data Labs leverages the seamless integration between AWS services to power their robust solution. Currently, the Well Data Labs architecture includes Amazon Elastic Compute Cloud (Amazon EC2) for all of their managed servers (to power their applications), Amazon S3 to store the various data artifacts without worrying about storage limitations, Amazon Simple Queue Service (Amazon SQS) to create a distributed system, and Amazon Virtual Private Cloud (VPC) and AWS Identity and Access Management (IAM) to keep its infrastructure secure. In addition to all of those core services, Well Data Labs uses Amazon SageMaker in their Machine Learning (ML) workloads.
Churlik recalls that he started a data science team to begin exploratory R&D with ML about a year ago. “We asked ourselves, ‘what is the value that it [ML] could be providing to our customers?’ And then we started experimenting.”
Now, the team uses Amazon SageMaker to deploy trained models on custom Docker containers via their proprietary SaaS application. The Amazon SageMaker models and SageMaker endpoint features enable Well Data Labs to integrate ML into the SaaS application and thereby bring frontline engineering workers real-time data for event detection and notification during operations. Well Data Labs set the precedent by bringing ML to the oil and gas market in this way.
Using AWS to build and host many of their solutions means the Well Data Labs team can focus on R&D and developing new product features, rather than on managing infrastructure. Well Data Labs data scientists can deploy new prediction models as soon as they are ready and iterate on new versions rapidly. The quick integration and deployment of ML functionality into the SaaS application in turn enables frontline users to benefit from data science advances right away. The first set of models that Well Data Labs built immediately saved their customers up to an hour a day of manual data entry.
Achieving that kind of success right out of the gates is exciting, and this is only the beginning. Well Data Labs pioneered the “digital oilfield” (where technology, data, automation, and people in the oil and gas industry all intersect), and their customers affirm that this small but mighty Denver-based company is ushering in a new era for the oil and gas industry.
About the Author
 Marisa Messina is on the AWS ML marketing team, where her job includes identifying the most innovative AWS-using customers and showcasing their inspiring stories. Prior to AWS, she worked on consumer-facing hardware and then university-facing cloud offerings at Microsoft. Outside of work, she enjoys exploring the Pacific Northwest hiking trails, cooking without recipes, and dancing in the rain.
Marisa Messina is on the AWS ML marketing team, where her job includes identifying the most innovative AWS-using customers and showcasing their inspiring stories. Prior to AWS, she worked on consumer-facing hardware and then university-facing cloud offerings at Microsoft. Outside of work, she enjoys exploring the Pacific Northwest hiking trails, cooking without recipes, and dancing in the rain.
Building SMILY, a Human-Centric, Similar-Image Search Tool for Pathology
Advances in machine learning (ML) have shown great promise for assisting in the work of healthcare professionals, such as aiding the detection of diabetic eye disease and metastatic breast cancer. Though high-performing algorithms are necessary to gain the trust and adoption of clinicians, they are not always sufficient—what information is presented to doctors and how doctors interact with that information can be crucial determinants in the utility that ML technology ultimately has for users.
The medical specialty of anatomic pathology, which is the gold standard for the diagnosis of cancer and many other diseases through microscopic analysis of tissue samples, can greatly benefit from applications of ML. Though diagnosis through pathology is traditionally done on physical microscopes, there has been a growing adoption of “digital pathology,” where high-resolution images of pathology samples can be examined on a computer. With this movement comes the potential to much more easily look up information, as is needed when pathologists tackle the diagnosis of difficult cases or rare diseases, when “general” pathologists approach specialist cases, and when trainee pathologists are learning. In these situations, a common question arises, “What is this feature that I’m seeing?” The traditional solution is for doctors to ask colleagues, or to laboriously browse reference textbooks or online resources, hoping to find an image with similar visual characteristics. The general computer vision solution to problems like this is termed content-based image retrieval (CBIR), one example of which is the “reverse image search” feature in Google Images, in which users can search for similar images by using another image as input.
Today, we are excited to share two research papers describing further progress in human-computer interaction research for similar image search in medicine. In “Similar Image Search for Histopathology: SMILY” published in Nature Partner Journal (npj) Digital Medicine, we report on our ML-based tool for reverse image search for pathology. In our second paper, “Human-Centered Tools for Coping with Imperfect Algorithms During Medical Decision-Making” (preprint available here), which received an honorable mention at the 2019 ACM CHI Conference on Human Factors in Computing Systems, we explored different modes of refinement for image-based search, and evaluated their effects on doctor interaction with SMILY.
SMILY Design
The first step in developing SMILY was to apply a deep learning model, trained using 5 billion natural, non-pathology images (e.g., dogs, trees, man-made objects, etc.), to compress images into a “summary” numerical vector, called an embedding. The network learned during the training process to distinguish similar images from dissimilar ones by computing and comparing their embeddings. This model is then used to create a database of image patches and their associated embeddings using a corpus of de-identified slides from The Cancer Genome Atlas. When a query image patch is selected in the SMILY tool, the query patch’s embedding is similarly computed and compared with the database to retrieve the image patches with the most similar embeddings.
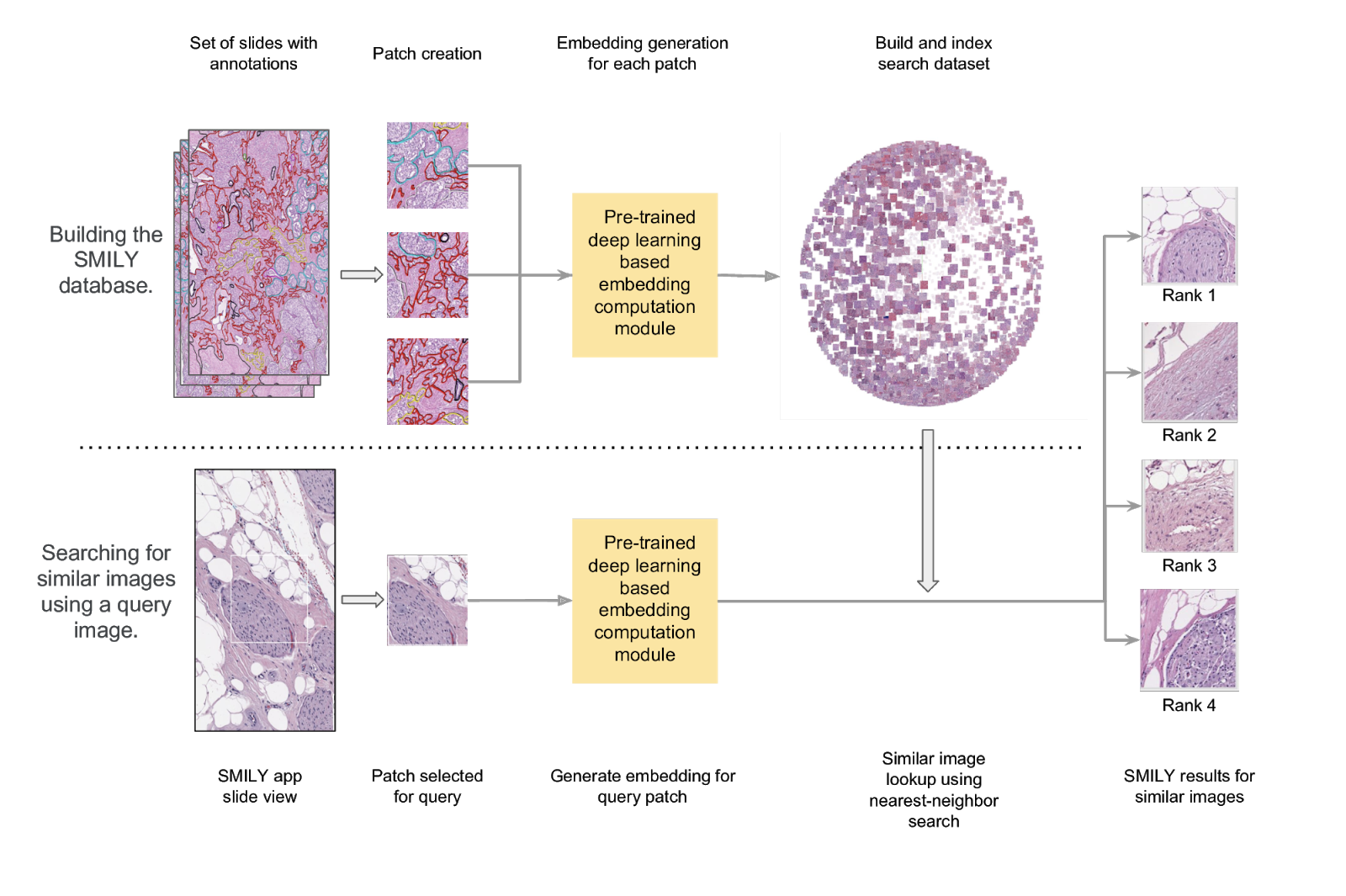 |
| Schematic of the steps in building the SMILY database and the process by which input image patches are used to perform the similar image search. |
The tool allows a user to select a region of interest, and obtain visually-similar matches. We tested SMILY’s ability to retrieve images along a pre-specified axis of similarity (e.g. histologic feature or tumor grade), using images of tissue from the breast, colon, and prostate (3 of the most common cancer sites). We found that SMILY demonstrated promising results despite not being trained specifically on pathology images or using any labeled examples of histologic features or tumor grades.
 |
| Example of selecting a small region in a slide and using SMILY to retrieve similar images. SMILY efficiently searches a database of billions of cropped images in a few seconds. Because pathology images can be viewed at different magnifications (zoom levels), SMILY automatically searches images at the same magnification as the input image. |
| Second example of using SMILY, this time searching for a lobular carcinoma, a specific subtype of breast cancer. |
Refinement tools for SMILY
However, a problem emerged when we observed how pathologists interacted with SMILY. Specifically, users were trying to answer the nebulous question of “What looks similar to this image?” so that they could learn from past cases containing similar images. Yet, there was no way for the tool to understand the intent of the search: Was the user trying to find images that have a similar histologic feature, glandular morphology, overall architecture, or something else? In other words, users needed the ability to guide and refine the search results on a case-by-case basis in order to actually find what they were looking for. Furthermore, we observed that this need for iterative search refinement was rooted in how doctors often perform “iterative diagnosis”—by generating hypotheses, collecting data to test these hypotheses, exploring alternative hypotheses, and revisiting or retesting previous hypotheses in an iterative fashion. It became clear that, for SMILY to meet real user needs, it would need to support a different approach to user interaction.
Through careful human-centered research described in our second paper, we designed and augmented SMILY with a suite of interactive refinement tools that enable end-users to express what similarity means on-the-fly: 1) refine-by-region allows pathologists to crop a region of interest within the image, limiting the search to just that region; 2) refine-by-example gives users the ability to pick a subset of the search results and retrieve more results like those; and 3) refine-by-concept sliders can be used to specify that more or less of a clinical concept be present in the search results (e.g., fused glands). Rather than requiring that these concepts be built into the machine learning model, we instead developed a method that enables end-users to create new concepts post-hoc, customizing the search algorithm towards concepts they find important for each specific use case. This enables new explorations via post-hoc tools after a machine learning model has already been trained, without needing to re-train the original model for each concept or application of interest.

Through our user study with pathologists, we found that the tool-based SMILY not only increased the clinical usefulness of search results, but also significantly increased users’ trust and likelihood of adoption, compared to a conventional version of SMILY without these tools. Interestingly, these refinement tools appeared to have supported pathologists’ decision-making process in ways beyond simply performing better on similarity searches. For example, pathologists used the observed changes to their results from iterative searches as a means of progressively tracking the likelihood of a hypothesis. When search results were surprising, many re-purposed the tools to test and understand the underlying algorithm, for example, by cropping out regions they thought were interfering with the search or by adjusting the concept sliders to increase the presence of concepts they suspected were being ignored. Beyond being passive recipients of ML results, doctors were empowered with the agency to actively test hypotheses and apply their expert domain knowledge, while simultaneously leveraging the benefits of automation.

With these interactive tools enabling users to tailor each search experience to their desired intent, we are excited for SMILY’s potential to assist with searching large databases of digitized pathology images. One potential application of this technology is to index textbooks of pathology images with descriptive captions, and enable medical students or pathologists in training to search these textbooks using visual search, speeding up the educational process. Another application is for cancer researchers interested in studying the correlation of tumor morphologies with patient outcomes, to accelerate the search for similar cases. Finally, pathologists may be able to leverage tools like SMILY to locate all occurrences of a feature (e.g. signs of active cell division, or mitosis) in the same patient’s tissue sample to better understand the severity of the disease to inform cancer therapy decisions. Importantly, our findings add to the body of evidence that sophisticated machine learning algorithms need to be paired with human-centered design and interactive tooling in order to be most useful.
Acknowledgements
This work would not have been possible without Jason D. Hipp, Yun Liu, Emily Reif, Daniel Smilkov, Michael Terry, Craig H. Mermel, Martin C. Stumpe and members of Google Health and PAIR. Preprints of the two papers are available here and here.
Meaningful innovation: Human ingenuity, powered by AI
The post Meaningful innovation: Human ingenuity, powered by AI appeared first on The AI Blog.
Spotting Clouds on the Horizon: AI Resolves Uncertainties in Climate Projections
Climate researchers look into the future to project how much the planet will warm in coming decades — but they often rely on decades-old software to conduct their analyses.
This legacy software architecture is difficult to update with new methodologies that have emerged in recent years. So a consortium of researchers is starting from scratch, writing a new climate model that leverages AI, new software tools and NVIDIA GPUs.
Scientists from Caltech, MIT, the Naval Postgraduate School and NASA’s Jet Propulsion Laboratory are part of the initiative, named the Climate Modeling Alliance — or CliMA.
“Computing has advanced quite a bit since the ‘60s,” said Raffaele Ferrari, oceanography professor at MIT and principal investigator on the project. “We know much more than we did at that time, but a lot was hard-coded into climate models when they were first developed.”
Building a new climate model from the ground up allows climate researchers to better account for small-scale environmental features, including cloud cover, rainfall, sea ice and ocean turbulence.
These variables are too geographically miniscule to be precisely captured in climate models, but can be better approximated using AI. Incorporating the AI’s projections into the new climate model could reduce uncertainties by half compared to existing models.
The team is developing the new model using Julia, an MIT-developed programming language that was designed for parallelism and distributed computation, allowing the scientists to accelerate their climate model calculations using NVIDIA V100 Tensor Core GPUs onsite and on Google Cloud.
As the project progresses, the researchers plan to use supercomputers like the GPU-powered Summit system at Oak Ridge National Labs as well as commercial cloud resources to run the new climate model — which they hope to have running within the next five years.
AI Turns the Tide
Climate scientists use physics and thermodynamics equations to calculate the evolution of environmental variables like air temperature, sea level and rainfall. But it’s incredibly computationally intensive to run these calculations for the entire planet. So in existing models, researchers divide the globe into a grid of 100-square-kilometer sections.
They calculate every 100 km block independently, using mathematical approximations for smaller features like turbulent eddies in the ocean and low-lying clouds in the sky — which can measure less than one kilometer across. As a result, when stringing the grid back together into a global model, there’s a margin of uncertainty introduced in the output.
Small uncertainties can make a significant difference, especially when climate scientists are estimating for policymakers how many years it will take for average global temperature to rise by more than two degrees Celcius. Due to the current levels of uncertainty, researchers project that, with current emission levels, this threshold could be crossed as soon as 2040 — or as late as 2100.
“That’s a huge margin of uncertainty,” said Ferrari. “Anything to reduce that margin can provide a societal benefit estimated in trillions of dollars. If one knows better the likelihood of changes in rainfall patterns, for example, then everyone from civil engineers to farmers can decide what infrastructure and practices they may need to plan for.”
A Deep Dive into Ocean Data
The MIT researchers are focusing on building the ocean elements of CliMA’s new climate model. Covering around 70 percent of the planet’s surface, oceans are a major heat and carbon dioxide reservoir. To make ocean-related climate projections, scientists look at such variables as water temperature, salinity and velocity of ocean currents.
One such dynamic is turbulent streams of water that flow around in the ocean like “a lot of little storms,” Ferrari said. “If you don’t account for all that swirling motion, you strongly underestimate how the ocean is absorbing heat and carbon.”
Using GPUs, researchers can narrow the resolution of their high-resolution simulations from 100 square kilometers down to one square kilometer, dramatically reducing uncertainties. But these simulations are too expensive to directly incorporate into a climate model that looks decades into the future.
That’s where an AI model that learns from fine-resolution ocean and cloud simulations can help.
“Our goal is to run thousands of high-resolution simulations, one for each 100-by-100 kilometer block, that will resolve the small-scale physics presently not captured by climate models,” said Chris Hill, principal research engineer at MIT’s earth, atmospheric and planetary sciences department.
These high-resolution simulations produce abundant synthetic data. That data can be combined with sparser real-world measurements, creating a robust training dataset for an AI model that estimates the impact of small-scale physics like ocean turbulence and cloud patterns on large-scale climate variables.
CliMA researchers can then plug these AI tools into the new climate model software, improving the accuracy of long-term projections.
“We’re betting a lot on GPU technology to provide a boost in compute performance,” Hill said.
MIT hosted in June a weeklong GPU hackathon, where developers — including Hill’s team as well as research groups from other universities — used the CUDA parallel computing platform and the Julia programming language for projects such as ocean modeling, plasma fusion and astrophysics.
For more on how AI and GPUs accelerate scientific research, see the NVIDIA higher education page. Find the latest NVIDIA hardware discounts for academia on our educational pricing page.
Image by Tiago Fioreze, licensed from Wikimedia Commons under Creative Commons 3.0 license.
The post Spotting Clouds on the Horizon: AI Resolves Uncertainties in Climate Projections appeared first on The Official NVIDIA Blog.
Full ML Engineer scholarships from Udacity and the AWS DeepRacer Scholarship Challenge
The growth of artificial intelligence could create 58 million net new jobs in the next few years, states the World Economic Forum [1]. Yet, according to the Tencent Research Institute, it’s estimated that currently there are 300,000 AI engineers worldwide, but millions are needed [2]. As you can tell, there is a unique and immediate opportunity to develop creative experiences and introduce you—no matter what your developer skill levels are—to essential ML concepts. These experiences in fields of ML like deep learning, reinforcement learning, and so on, will expand your skills and help close the talent gap.
To help you advance your AI/ML capabilities with hands-on and fun ML learning experiences, I am thrilled to announce the AWS DeepRacer Scholarship Challenge.

What is AWS DeepRacer?
In November 2018, Jeff Barr announced the launch of AWS DeepRacer on the AWS News Blog as a new way to learn ML. With AWS DeepRacer, you have an opportunity to get hands-on with a fully autonomous 1/18th-scale race car driven by reinforcement learning, a 3D racing simulator, and a global racing league.
What is the AWS DeepRacer Scholarship Challenge?
AWS and Udacity are collaborating to educate developers of all skill levels on ML concepts. Those skills are reinforced by putting them to the test through the world’s first autonomous racing league—the AWS DeepRacer League.
Students enrolled in the AWS DeepRacer Scholarship Challenge who have the top lap times can win full scholarships to the Machine Learning Engineer nanodegree program. The Udacity Nanodegree program is a unique online educational offering designed to bridge the gap between learning and career goals.

How does the AWS DeepRacer Scholarship Challenge work?
The program begins August 1, 2019 and runs through October 31, 2019. You can join the scholarship community at any point during these three months and immediately enroll in Udacity’s specialized AWS DeepRacer course. Register now to be in pole position for the start of the race.
After enrollment, you go through the AWS DeepRacer course, which consists of short, step-by-step modules (90 minutes in total). The modules prepare you to create, train, and fine-tune a reinforcement learning model in the AWS DeepRacer 3D racing simulator. Throughout the program and during each race, you have access to a custom scholarship student community to get pro tips from experts and exchange ideas with your classmates.
Each month, you can pit your skills against others in virtual races in the AWS DeepRacer console. Students compete for top spots in each month’s unique race course. Students that record the top lap times in August, September, and October 2019 qualify for one of 200 full scholarships to the Udacity Machine Learning Engineer nanodegree program, sponsored by Udacity.
Next steps
To get notified about the scholarship program and enrollment dates, register now. For a program FAQ, see AWS DeepRacer Scholarship Challenge.
Developers, start your engines! The first challenge starts August 1, 2019!
[1] Artificial Intelligence To Create 58 Million New Jobs By 2022, Says Report (Forbes)
[2] Tencent says there are only 300,000 AI engineers worldwide, but millions are needed (The Verge)
About the Author
 Tara Shankar Jana is a Senior Product Marketing Manager for AWS Machine Learning. Currently he is working on building unique and scalable educational offerings for the aspiring ML developer communities- to help them expand their skills on ML. Outside of work he loves reading books, travelling and spending time with his family.
Tara Shankar Jana is a Senior Product Marketing Manager for AWS Machine Learning. Currently he is working on building unique and scalable educational offerings for the aspiring ML developer communities- to help them expand their skills on ML. Outside of work he loves reading books, travelling and spending time with his family.