This neighborhood has shopping, cafes, even a place to go to school. But it happens to fit nearly inside a 2,000 square-foot trade show booth, showing off smart city technology.
With a miniature town erected on the show floor, NVIDIA welcomed more than 22,000 telecom industry professionals attending the Mobile World Congress in Los Angeles.
Crowds jammed into the booth to see how pervasive AI and connectivity can elevate experiences in the world around us. While most cities are powered by elaborate power and water grids, this one’s infrastructure is built on NVIDIA AI technologies.
Front and center, a huge display at the front of the booth monitoring the heart of our virtual city told the stories of a diverse array of NVIDIA EGX-powered technologies.
Qwake Technologies, for example, creates augmented reality maps to guide firefighters. Volvo Trucks has built Vera, the first cabin-less autonomous truck to move cargo. Blue River Technologies is using AI to apply tiny doses of pesticides with incredible precision.
Shopping Spree
Steps away, showgoers could stroll into a convenience store stocked with everything from Fuji spring water to KitKats to Chex Mix. Thanks to startup AIFi’s EGX-powered systems, customers could simply grab what they needed and go, and get invisibly charged to the sale.
Another startup, AnyVision, showed how it’s using EGX to do real-time analytics of customer’s shopping behaviors, giving real-world stores the same kind of insights into shopping behavior long enjoyed by online ones.
Nearby, Malong Technologies showed how its GPU-powered system allows shoppers to grab a bunch of grapes or a banana, and have the checkout system instantly recognize it — no bar codes needed.
Around the corner, food delivery service Postmates showed off what it describes as the first socially aware food delivery robot. Its diminutive yellow robot, equipped with powerful lidar sensors and a playful digital face, is powered by NVIDIA EGX servers running in a data center, Xavier, and NVIDIA JetPack software developer kit.
No modern city is complete without a gaming café. The NVIDIA Edge Cafe’s games, however, are hosted on a data center miles away and beamed to devices over Wi-Fi and Verizon’s 5G network.
The result: cheap, light laptops and smartphones equipped with game controllers were able to play the latest games in stunning high-definition quality at 60 frames per second.
Gawking at an Invisible Car
Of course no great street scene — or trade show booth — is complete without a car. In a witty twist, this car’s invisible until you pick up an ordinary smartphone.
Looking through the phone’s screen, you can check out a million-dollar, cherry-red McLaren Senna sports coupe mounted on a pedestal at the front of the booth.
“Okay, so that was pretty cool,” said Danny Miller, a car aficionado who works in sales and marketing for a media company after taking a long look at the curvaceous virtual coupe.
The demo relied on the NVIDIA CloudXR software developer kit, which lets enterprises deliver virtual and augmented reality experiences across 5G networks to let showgoers see a virtual car created out of 28 million polygons and running an NVIDIA Quadro RTX 8000 GPU.
No City’s Complete Without Top-Rated Schools
This city is even equipped with not one, but two places where you can go to school to learn more.
The NVIDIA theater features speakers from around the industry — like Kundana Palagiri, principal program manager for Microsoft Azure; and Usman Sadiq, deep learning product manager at Cisco — who shared their real-world experience with scores of listeners.
Around the corner, NVIDIA’s Deep Learning Institute had set up a bank of 15 laptops for hands-on training in AI and accelerated computing to solve real-world problems to developers, data scientists, researchers and students led by expert instructors.
Attendees from marketing, security and customer service companies — among others — inspired by what they’ve heard at the show, signed up for hands-on training.
Join the Crowd
This tiny city, in short, has almost anything you could need. The only downside: like any bustling city, there’s plenty of traffic. All of it, in this case, on foot.
Scores of attendees crowded into the booth to gawk, snap photos and grab black-shirted NVIDIA employees to ask questions and exchange business cards.
In town? Stop by our town at booth 1745 in the South Hall of the Los Angeles Convention Center.
There are an estimated 59.8 million Hispanic people in the United States. (This figure comes from the US Census annual estimate as of July 1, 2018.) Companies that provide engaging online content to their Hispanic audience set themselves up for success. The new US Spanish voice, Lupe, joins this trend. After Miguel and Penelope, it is the third US Spanish TTS voice in the Amazon Polly portfolio. Lupe offers a human-like quality with enhanced intonation, especially when listening to the neural version of the voice. Lupe not only speaks Spanish but also handles English very well; it provides a fully bilingual Spanish-English experience. All this thanks to an extended phoneme coverage, comprised of 72 English and Spanish phoneme variants. In contrast, the phone set for Penélope and Miguel contains only 29 Spanish phonemes.
Camila, the new Brazilian Portuguese TTS voice, supports customers whose priority is to provide best-in-class TTS voices for their Brazilian Portuguese-speaking audience. Similar to Lupe, Camila is a natural-sounding TTS voice that demonstrates a high prosodic quality. The synthesis generated by this voice is smooth and clear, which makes Camila a pleasant voice to listen to. Amazon Polly customers can now enjoy a selection of three Brazilian Portuguese voices: Ricardo, Vitória, and Camila.
The neural versions of Camila and Lupe are the first two non-English NTTS voices that Amazon Polly offers, and are available in US East (N. Virginia), US West (Oregon), and EU (Ireland) Regions. Standard versions of these voices are also available across 18 AWS Regions.
Amazon Polly now offers a selection of 61 voices across 29 languages. Of these, thirteen voices in four languages are available in both standard and neural technology.
Try these new voices and experience for yourself the natural-sounding NTTS technology powering Camila and Lupe.
About the Author
Marta Smolarek is a Program Manager in the Amazon Text-to-Speech team. At work she connects the dots. In her spare time, she loves to go camping with her family.
There’s a maxim in stroke treatment: “time is brain.”
It’s a reminder that during a stroke, human nervous tissue is lost at an alarming rate. From the onset of a brain injury and the start of medical treatment, every moment matters.
Researchers at UC Berkeley and UCSF School of Medicine are working on a deep learning model to reduce the time it takes to diagnose intracranial hemorrhage (bleeding in the skull) on a CT scan. With more than 80 million CT scans performed annually in the United States alone, AI could increase radiologists’ efficiency amidst an overwhelming volume of images.
“When someone gets into a car accident, or there’s a fall or other trauma that involves the head — a doctor will order a head CT scan,” said Weicheng Kuo, lead author on the paper, published this week in the leading scientific journal PNAS.
It’s critical to detect hemorrhages, even tiny ones. The analysis requires a high degree of focus by specially trained radiologists.
A neural network that assesses CT scans could reduce the burden on these specialists. Kuo and his collaborators expect a significant increase in radiologists’ productivity with their deep learning system, PatchFCN.
The researchers used NVIDIA V100 Tensor Core GPUs through Amazon Web Services for both the training and inference of their AI model, which segments the hemorrhage area, and identifies brain hemorrhages with 99 percent accuracy. The neural network also performs automated measurements of abnormalities on the CT scans, a time-consuming step that radiologists manually perform today.
Every Minute Matters
Radiologists often have a large stack of sans to go through. Depending on how busy the day is, the turnaround time for reading a scan and reporting results to the emergency department can be half an hour or more.
If an abnormal case is at the bottom of the stack, the delay in diagnosis can adversely affect patients. AI can close this gap, processing a scan within a second, on average, using a single NVIDIA GPU for inference.
Trained on a dataset of more than 4,000 head CT scans from UCSF-affiliated hospitals, the PatchFCN performance rivals that of experienced radiologists, the study showed.
The volume of medical imaging studies is on the rise. Tools like PatchFCN could help radiologists manage larger workloads and boost their efficiency, Kuo says.
Looking Patch by Patch
Many convolutional neural networks analyze a whole image at once to come up with a result. And that makes sense: in the world of digital data, it’s often assumed that more information is better.
But, instead, the team found that splitting a CT scan into smaller patches improved the neural network’s results. They experimented with the patch size to achieve the best performance.
Neural networks can be set at different levels of recall, or sensitivity. The researchers believe that for this clinical application, the system should operate at the highest possible recall level, since the consequences of missing a brain hemorrhage could be catastrophic.
With this high-recall setting, the model had an average precision of 99 percent for detecting hemorrhages, the highest classification accuracy to date.
Rather than providing only a “yes” or “no” result, the neural network also provides a detailed tracing of each hemorrhage. The ability to highlight abnormalities directly on the image is essential for clinical use, because neurosurgeons must visually confirm the locations of hemorrhages on a head CT exam to judge the need and approach for surgical intervention.
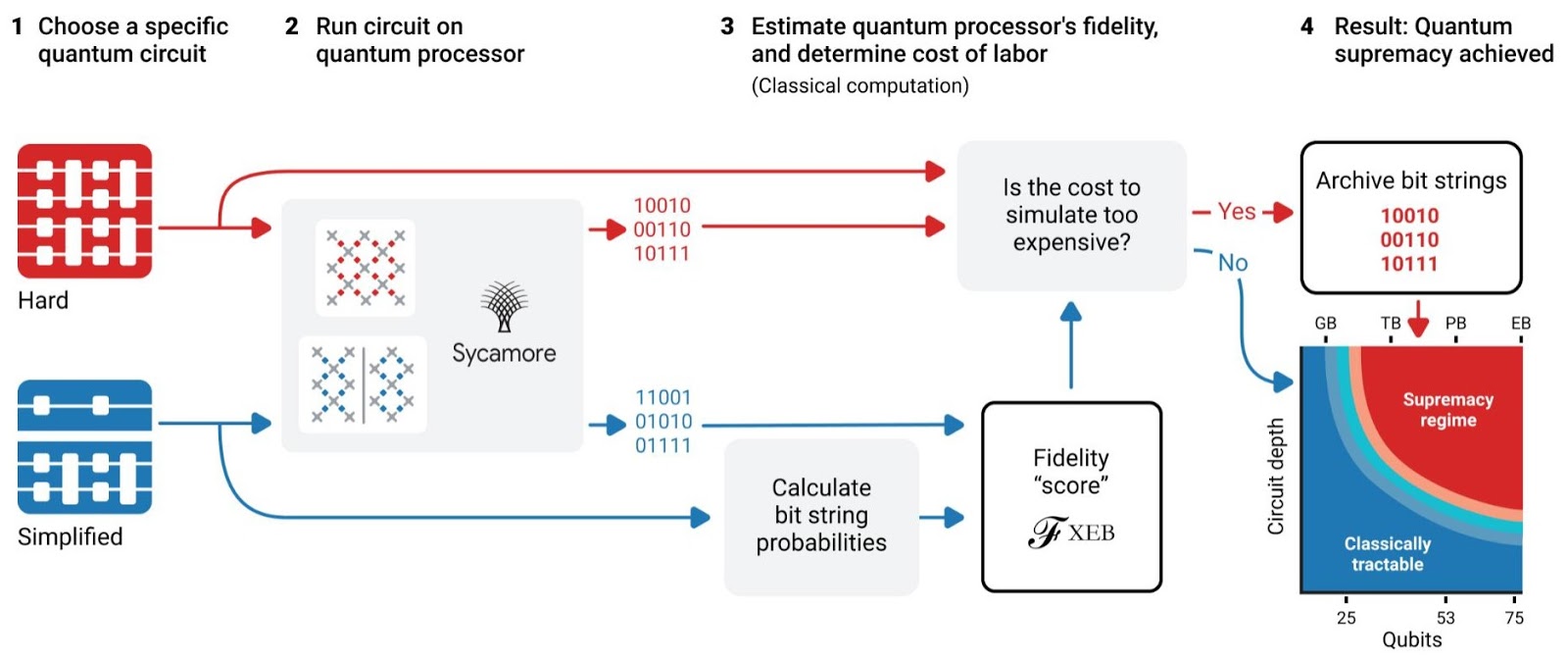
Posted by John Martinis, Chief Scientist Quantum Hardware and Sergio Boixo, Chief Scientist Quantum Computing Theory, Google AI Quantum Physicists have been talking about the power of quantum computing for over 30 years, but the questions have always been: will it ever do something useful and is it worth investing in? For such large-scale endeavors it is good engineering practice to formulate decisive short-term goals that demonstrate whether the designs are going in the right direction. So, we devised an experiment as an important milestone to help answer these questions. This experiment, referred to as a quantum supremacy experiment, provided direction for our team to overcome the many technical challenges inherent in quantum systems engineering to make a computer that is both programmable and powerful. To test the total system performance we selected a sensitive computational benchmark that fails if just a single component of the computer is not good enough.
Today we published the results of this quantum supremacy experiment in the Nature article, “Quantum Supremacy Using a Programmable Superconducting Processor”. We developed a new 54-qubit processor, named “Sycamore”, that is comprised of fast, high-fidelity quantum logic gates, in order to perform the benchmark testing. Our machine performed the target computation in 200 seconds, and from measurements in our experiment we determined that it would take the world’s fastest supercomputer 10,000 years to produce a similar output.
Left: Artist’s rendition of the Sycamore processor mounted in the cryostat. (Full Res Version; Forest Stearns, Google AI Quantum Artist in Residence) Right: Photograph of the Sycamore processor. (Full Res Version; Erik Lucero, Research Scientist and Lead Production Quantum Hardware)
The Experiment To get a sense of how this benchmark works, imagine enthusiastic quantum computing neophytes visiting our lab in order to run a quantum algorithm on our new processor. They can compose algorithms from a small dictionary of elementary gate operations. Since each gate has a probability of error, our guests would want to limit themselves to a modest sequence with about a thousand total gates. Assuming these programmers have no prior experience, they might create what essentially looks like a random sequence of gates, which one could think of as the “hello world” program for a quantum computer. Because there is no structure in random circuits that classical algorithms can exploit, emulating such quantum circuits typically takes an enormous amount of classical supercomputer effort.
Each run of a random quantum circuit on a quantum computer produces a bitstring, for example 0000101. Owing to quantum interference, some bitstrings are much more likely to occur than others when we repeat the experiment many times. However, finding the most likely bitstrings for a random quantum circuit on a classical computer becomes exponentially more difficult as the number of qubits (width) and number of gate cycles (depth) grow.
Process for demonstrating quantum supremacy.
In the experiment, we first ran random simplified circuits from 12 up to 53 qubits, keeping the circuit depth constant. We checked the performance of the quantum computer using classical simulations and compared with a theoretical model. Once we verified that the system was working, we ran random hard circuits with 53 qubits and increasing depth, until reaching the point where classical simulation became infeasible.
Estimate of the equivalent classical computation time assuming 1M CPU cores for quantum supremacy circuits as a function of the number of qubits and number of cycles for the Schrödinger-Feynmanalgorithm. The star shows the estimated computation time for the largest experimental circuits.
This result is the first experimental challenge against the extended Church-Turing thesis, which states that classical computers can efficiently implement any “reasonable” model of computation. With the first quantum computation that cannot reasonably be emulated on a classical computer, we have opened up a new realm of computing to be explored.
The Sycamore Processor The quantum supremacy experiment was run on a fully programmable 54-qubit processor named “Sycamore.” It’s comprised of a two-dimensional grid where each qubit is connected to four other qubits. As a consequence, the chip has enough connectivity that the qubit states quickly interact throughout the entire processor, making the overall state impossible to emulate efficiently with a classical computer.
The success of the quantum supremacy experiment was due to our improved two-qubit gates with enhanced parallelism that reliably achieve record performance, even when operating many gates simultaneously. We achieved this performance using a new type of control knob that is able to turn off interactions between neighboring qubits. This greatly reduces the errors in such a multi-connected qubit system. We made further performance gains by optimizing the chip design to lower crosstalk, and by developing new control calibrations that avoid qubit defects.
We designed the circuit in a two-dimensional square grid, with each qubit connected to four other qubits. This architecture is also forward compatible for the implementation of quantum error-correction. We see our 54-qubit Sycamore processor as the first in a series of ever more powerful quantum processors.
Heat map showing single- (e1; crosses) and two-qubit (e2; bars) Pauli errors for all qubits operating simultaneously. The layout shown follows the distribution of the qubits on the processor. (Courtesy of Nature magazine.)
Testing Quantum Physics To ensure the future utility of quantum computers, we also needed to verify that there are no fundamental roadblocks coming from quantum mechanics. Physics has a long history of testing the limits of theory through experiments, since new phenomena often emerge when one starts to explore new regimes characterized by very different physical parameters. Prior experiments showed that quantum mechanics works as expected up to a state-space dimension of about 1000. Here, we expanded this test to a size of 10 quadrillion and find that everything still works as expected. We also tested fundamental quantum theory by measuring the errors of two-qubit gates and finding that this accurately predicts the benchmarking results of the full quantum supremacy circuits. This shows that there is no unexpected physics that might degrade the performance of our quantum computer. Our experiment therefore provides evidence that more complex quantum computers should work according to theory, and makes us feel confident in continuing our efforts to scale up.
Applications The Sycamore quantum computer is fully programmable and can run general-purpose quantum algorithms. Since achieving quantum supremacy results last spring, our team has already been working on near-term applications, including quantum physics simulation and quantum chemistry, as well as new applications in generative machine learning, among other areas.
We also now have the first widely useful quantum algorithm for computer science applications: certifiable quantum randomness. Randomness is an important resource in computer science, and quantum randomness is the gold standard, especially if the numbers can be self-checked (certified) to come from a quantum computer. Testing of this algorithm is ongoing, and in the coming months we plan to implement it in a prototype that can provide certifiable random numbers.
What’s Next? Our team has two main objectives going forward, both towards finding valuable applications in quantum computing. First, in the future we will make our supremacy-class processors available to collaborators and academic researchers, as well as companies that are interested in developing algorithms and searching for applications for today’s NISQ processors. Creative researchers are the most important resource for innovation — now that we have a new computational resource, we hope more researchers will enter the field motivated by trying to invent something useful.
Second, we’re investing in our team and technology to build a fault-tolerant quantum computer as quickly as possible. Such a device promises a number of valuable applications. For example, we can envision quantum computing helping to design new materials — lightweight batteries for cars and airplanes, new catalysts that can produce fertilizer more efficiently (a process that today produces over 2% of the world’s carbon emissions), and more effective medicines. Achieving the necessary computational capabilities will still require years of hard engineering and scientific work. But we see a path clearly now, and we’re eager to move ahead.
Acknowledgements We’d like to thank our collaborators and contributors — University of California Santa Barbara, NASA Ames Research Center, Oak Ridge National Laboratory, Forschungszentrum Jülich, and many others who helped along the way.
Posted by Kevin Kilgour, Software Engineer and Thomas Unterthiner, Research Software Engineer, Google Research, Zurich
“I often say that when you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meagre and unsatisfactory kind.”
The rate of scientific progress in machine learning has often been determined by the availability of good datasets, and metrics. In deep learning, benchmark datasets such as ImageNet or Penn Treebank were among the driving forces that established deep artificial neural networks for image recognition and language modeling. Yet, while the available “ground-truth” datasets lend themselves nicely as measures of performance on these prediction tasks, determining the “ground-truth” for comparison to generative models is not so straightforward. Imagine a model that generates videos of StarCraft video game sequences — how does one determine which model is best? Clearly some of the videos shown below look more realistic than others, but can the differences between them be quantified? Access to robust metrics for evaluation of generative models is crucial for measuring (and making) progress in the fields of audio and video understanding, but currently no such metrics exist.
Videos generated from various models trained on sequences from the StarCraft Video (SCV) dataset.
General Description of FréchetDistance The goal of a generative model is to learn to produce samples that look similar to the ones on which it has been trained, such that it knows what properties and features are likely to appear in the data, and which ones are unlikely. In other words, a generative model must learn the probability distribution of the training data. In many cases, the target distributions for generative models are very high-dimensional. For example, a single image of 128×128 pixels with 3 color channels has almost 50k dimensions, while a second-long video clip might consist of dozens (or hundreds) of such frames with audio that may have 16,000 samples. Calculating distances between such high dimensional distributions in order to quantify how well a given model succeeds at a task is very difficult. In the case of pictures, one could look at a few samples to gauge visual quality, but doing so for every model trained is not feasible.
In addition, generative adversarial networks (GANs) tend to focus on a few modes of the overall target distribution, while completely ignoring others. For example, they may learn to generate only one type of object or only a select few viewing angles. As a consequence, looking only at a limited number of samples from the model may not indicate whether the network learned the entire distribution successfully. To remedy this, a metric is needed that aligns well with human judgement of quality, while also taking the properties of the target distribution into account.
One common solution for this problem is the so-called Fréchet Inception Distance (FID) metric, which was specifically designed for images. The FID takes a large number of images from both the target distribution and the generative model, and uses the Inception object-recognition network to embed each image into a lower-dimensional space that captures the important features. Then it computes the so-called Fréchet distance between these samples, which is a common way of calculating distances between distributions that provides a quantitative measure of how similar the two distributions actually are.
A key component for both metrics is a pre-trained model that converts the video or audio clip into an N-dimensional embedding.
Fréchet Audio Distance and Fréchet Video Distance Building on the principles of FID that have been successfully applied to the image domain, we propose both Fréchet Video Distance (FVD) and Fréchet Audio Distance (FAD). Unlike popular metrics such as peak signal-to-noise ratio or the structural similarity index, FVD looks at videos in their entirety, and thereby avoids the drawbacks of framewise metrics.
Examples of videos of a robot arm, judged by the new FVD metric. FVD values were found to be approximately 2000, 1000, 600, 400, 300 and 150 (left-to-right; top-to-bottom). A lower FVD clearly correlates with higher video quality.
In the audio domain, existing metrics either require a time-aligned ground truth signal, such as source-to-distortion ratio (SDR), or only target a specific domain, like speech quality. FAD on the other hand is reference-free and can be used on any type of audio.
Below is a 2-D visualization of the audio embedding vectors from which we compute the FAD. Each point corresponds to the embedding of a 5-second audio clip, where the blue points are from clean music and other points represent audio that has been distorted in some way. The estimated multivariate Gaussian distributions are presented as concentric ellipses. As the magnitude of the distortions increase, the overlap between their distributions and that of the clean audio decreases. The separation between these distributions is what the Fréchet distance is measuring.
In the animation, we can see that as the magnitude of the distortions increases, the Gaussian distributions of the distorted audio overlaps less with the clean distribution. The magnitude of this separation is what the Fréchet distance is measuring.
Evaluation It is important for FAD and FVD to closely track human judgement, since that is the gold standard for what looks and sounds “realistic”. So, we performed a large-scale human study to determine how well our new metrics align with qualitative human judgment of generated audio and video. For the study, human raters examined 10,000 video pairs and 69,000 5-second audio clips. For the FAD we asked human raters to compare the effect of two different distortions on the same audio segment, randomizing both the pair of distortions that they compared and the order in which they appeared. The raters were asked “Which audio clip sounds most like a studio-produced recording?” The collected set of pairwise evaluations was then ranked using a Plackett-Luce model, which estimates a worth value for each parameter configuration. Comparison of the worth values to the FAD demonstrates that the FAD correlates quite well with human judgement.
This figure compares the FAD calculated between clean background music and music distorted by a variety of methods (e.g., pitch down, Gaussian noise, etc.) to the associated worth values from human evaluation. Each type of distortion has two data points representing high and low extremes in the distortion applied. The quantization distortion (purple circles), for example, limits the audio to a specific number of bits per sample, where the two data points represent two different bitrates. Both human raters and the FAD assigned higher values (i.e., “less realistic”) to the lower bitrate quantization. Overall log FAD correlates well with human judgement — a perfect correlation between the log FAD and human perception would result in a straight line.
Conclusion We are currently making great strides in generative models. FAD and FVD will help us keeping this progress measurable, and will hopefully lead us to improve our models for audio and video generation.
Acknowledgements There are many people who contributed to this large effort, and we’d like to highlight some of the key contributors: Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, Sylvain Gelly, Mauricio Zuluaga, Dominik Roblek, Matthew Sharifi as well as the extended Google Brain team in Zurich.
Today AWS is pleased to announce that it is working with Facebook, Microsoft, and the Partnership on AI on the first Deepfakes Detection Challenge. The competition, to which we are contributing up to $1 million in AWS credits to researchers and academics over the next two years, is designed to produce technology that can be deployed to better detect when artificial intelligence has been used to alter a video in order to mislead the viewer. We plan to host the full competition dataset when it is made available later this year, and are offering the support of Amazon machine learning experts to help teams get started. We want to ensure access to this data for a diverse set of participants with varied perspectives to help develop the best possible solutions to combat the growing problem of “deepfakes.”
The same technology which has given us delightfully realistic animation effects in movies and video games, has also been used by bad actors to blur the distinction between reality and fiction. “Deepfake” videos manipulate audio and video using artificial intelligence to make it appear as though someone did or said something they didn’t. These techniques can be packaged up in to something as simple as a cell phone app, and are already being used to deliberately mislead audiences by spreading fake viral videos through social media. The fear is that deepfakes may become so realistic that they will be used to the detriment of reputations, to sway popular opinion, and could in time make any piece of information suspicious.
The Deepfakes Detection Challenge invites participants to build new approaches that can detect deepfake audio, video, and other tampered media. The challenge will kick off in December at the NeurIPS Conference with the release of a new dataset generated by Facebook which comprises tens of thousands of example videos, both real and fake. Competitors will use this dataset to design novel algorithms which can detect a real or fake video, and the algorithms will be evaluated against a secret test dataset (which will not be made available to ensure there is a standard, scientific evaluation of entries).
Building deepfake detectors will require novel algorithms which can process this vast library of data (more than 4 petabytes). AWS will work with DFDC partners to explore options for hosting the data set, including the use of Amazon S3, and we will make $1 million in AWS credits available to develop and test these sophisticated new algorithms. All participants will be able to request a minimum of $1,000 in AWS credits to get started, with additional awards granted in quantities of up to $10,000 as entries demonstrate viability or success in detecting deepfakes. Participants can visit www.aws.amazon.com/aws-ml-research-awards to learn more and request AWS credits.
The Deepfakes Detection Challenge steering committee is sharing the first 5,000 videos of the dataset with researchers working in this field. The group will collect feedback and host a targeted technical working session at the International Conference on Computer Vision (ICCV) in Seoul beginning on October 27, 2019. Following this due diligence, the full data set release and the launch of the Deepfakes Detection Challenge will coincide with the Conference on Neural Information Processing Systems (NeurIPS) this December.
To support participants in this endeavor, AWS will also be providing access to Amazon ML Solutions Lab experts and solutions architects to help provide technical support and guidance to contestants to help teams get started in the challenge. The Amazon ML Solutions Lab is a dedicated service offering for AWS customers that provides access to the same talent that built many of Amazon’s machine learning-powered products and services. These Amazon experts help AWS customers utilize machine learning technology to build intelligent solutions that to address some of the world’s toughest challenges like predicting famine, identifying cancer faster, and expediting assistance to areas hard hit by natural disasters. Amazon ML Solutions Lab experts will be paired with Challenge participants to provide assistance throughout the competition.
In addition to serving as a founding member of the Partnership on AI, AWS is also joining the non-profit’s Steering Committee on AI and Media Integrity. The goal, as with sponsorship of the Deepfakes Deception Challenge, is to coordinate the activities of media, tech companies, governments, and academia to promote technologies and policies that strengthen trust in media and help audiences differentiate fact from fiction.
To learn more about the Deepfakes Detection Challenge and receive updates on how to register and participate, visit www.Deepfakedetectionchallenge.ai. Stay tuned for more updates as we get closer to kick-off!
About the Author
Michelle Lee is vice president of the Machine Learning Solutions Lab at AWS.
The smartphone revolution that’s swept the globe over the past decade is just the start, NVIDIA CEO Jensen Huang declared Monday.
Next up: the “smart everything revolution,” Huang told a crowd of hundreds from telcos, device manufacturers, developers, and press at his keynote ahead of the Mobile World Congress gathering in Los Angeles this week.
“The smartphone revolution is the first of what people will realize someday is the IoT revolution, where everything is intelligent, where everything is smart,” Huang said. He squarely positioned NVIDIA to power AI at the edge of enterprise networks and in the virtual radio access networks – or vRANs – powering next-generation 5G wireless services.
Among the dozens of leading companies joining NVIDIA as customers and partners cited during Huang’s 90 minute address are WalMart — which is already building NVIDIA’s latest technologies into its showcase Intelligent Retail Lab — BMW, Ericsson, Microsoft, NTT, Procter & Gamble, Red Hat, and Samsung Electronics.
Anchoring NVIDIA’s story: the NVIDIA EGX edge supercomputing platform, a high-performance cloud-native edge computing platform optimized to take advantage of three key revolutions – AI, IoT and 5G – providing the world’s leading companies the ability to build next-generation services.
“The smartphone moment for edge computing is here and a new type of computer has to be created to provision these applications,” said Huang speaking at the LA Convention Center. He noted that if the global economy can be made just a little more efficient with such pervasive technology, the opportunity can be measured in “trillions of dollars per year.”
Ericsson Exec Joins on Stage Marking Collaboration
Ericsson’s Fredrik Jejdling, executive vice president and head of business area networks joined NVIDIA CEO Jensen Huang on stage to announce Ericsson and NVIDIA’s collaboration on 5G radio.
Joining Jensen on stage was Ericsson’s Fredrik Jejdling, executive vice president and head of business area networks. The company is a leader in the radio access network industry, one of the key building blocks for high-speed wireless networks.
“As an industry we’ve, in all honesty, been struggling to find alternatives that are better and higher performance than our current bespoke environment,” Jejdling said. “Our collaboration is figuring out an efficient way of providing that, combining your GPUs with our heritage.”
The collaboration brings Ericsson’s expertise in radio access network technology together with NVIDIA’s leadership in high-performance computing to fully virtualize the 5G Radio, giving telcos unprecedented flexibility.
Together NVIDIA and Ericsson are innovating to fuse 5G, supercomputing and AI for a revolutionary communications platform that will someday support trillions of always-on devices.
Red Hat, NVIDIA to Create Carrier-Grade Telecommunications Infrastructure
Red Hat, NVIDIA to create carrier-grade telecommunications infrastructure.
Huang also announced a new collaboration with Red Hat to building carrier-grade cloud native telecom infrastructure with EGX for AI, 5G RAN and other workloads. The enterprise software provider already serves 120 telcos around the world, powering every member of the Fortune 500.
Together, NVIDIA and Red Hat will bring carrier-grade Kubernetes — which automates the deployment, scaling, and management of applications – to telcos so they can orchestrate and manage 5G RANs in a truly-software defined mobile edge.
“Red Hat is joining us to integrate everything we’re working on and make it a carrier grade stack,” Huang said. “The rest of the industry has joined us as well, every single data center computer maker, the world’s leading enterprise software makers, have all joined us to take this platform to market.”
Introducing the NVIDIA EGX edge supercomputing platform, a high-performance cloud-native edge computing platform optimized to take advantage of three key revolutions – AI, IoT and 5G.
Aerial allows telecommunications companies to build completely virtualized 5G radio access networks that are highly programmable, scalable and energy efficient — enabling telcos to offer new AI services such as smart cities, smart factories, AR/VR and cloud gaming.
Technology for the Enterprise Edge
In addition to telcos, enterprises will also increasingly need high performance edge servers to make decisions from large amounts of data in real-time using AI.
EGX combines NVIDIA CUDA-X software, a collection of NVIDIA libraries that provide a flexible and high-performance programing language to developers, with NVIDIA-certified GPU servers and devices.
The result enables companies to harness rapidly streaming data — from factory floors to manufacturing inspection lines to city streets — delivering AI and other next-generation services.
Other top technology companies collaborating with NVIDIA on the EGX platform include Cisco, Dell Technologies, Hewlett Packard Enterprise, Mellanox and VMware.
Walmart Adopts EGX to Create Store of the Future
Huang cited Walmart as an example of EGX’s power.
The retail giant is deploying it in its Levittown, New York, Intelligent Retail Lab. It’s a unique, fully operating grocery store where the retail giant explores the ways AI can further improve in-store shopping experiences.
Walmart is deploying EGX in its Levittown, New York, Intelligent Retail Lab.
Using EGX’s advanced AI and edge capabilities, Walmart can compute in real time more than 1.6 terabytes of data generated per second. This helps it use to automatically alert associates to restock shelves, open up new checkout lanes, retrieve shopping carts and ensure product freshness in meat and produce departments.
Just squeezing out a half a percent of efficiencies in the $30 trillion retail opportunity represents an enormous opportunity, Huang noted. “The opportunity for using automation to improve efficiency in retail is extraordinary,” Huang said.
BMW, Procter & Gamble, Samsung, Among Leaders Adopting EGX
That power is already being harnessed for a dizzying array of real-world applications across the world:
Korea’s Samsung Electronics, in another early EGX deployment, is using AI at the edge for highly complex semiconductor design and manufacturing processes.
Germany’s BMW is using intelligent video analytics and EGX edge servers in its South Carolina manufacturing facility to automate inspection.
Japan’s NTT East uses EGX in its data centers to develop new AI-powered services in remote areas through its broadband access network.
The U.S.’s Procter & Gamble the world’s top consumer goods company, is working with NVIDIA to develop AI-enabled applications on top of the EGX platform for the inspection of products and packaging.
Cities, too, are grasping the opportunity. Las Vegas uses EGX to capture vehicle and pedestrian data to ensure safer streets and expand economic opportunity. And San Francisco’s prime shopping area, the Union Square Business Improvement District, uses EGX to capture real-time pedestrian counts for local retailers.
Stunning New Possibilities
To demonstrate the possibilities, Huang punctuated his keynote with demos showing what AI can unleash in the world around us.
In a flourish that stunned the crowd, Huang made a red McLaren Senna prototype — which carries a price of a hair under $1 million — materialize on stage in augmented reality. It could be viewed from any angle — including from the inside — on a smartphone streaming data over Verizon’s 5G network from a Verizon data center in Los Angeles
The technology behind the demo: Autodesk VRED running in a virtual machine on a Quadro RTX 8000 server. On the phone: a 5G client build with NVIDIA’s CloudXR client application software development kit for mobile devices and head mounted displays.
And, in a video, Huang showed how the Jarvis multi-modal AI was able to to follow queries from two different speakers conversing on different topics, the weather and restaurants, as they drove down the road – reacting to what the computer sees as well as what is said.
In another video, Jarvis guided a shopper through a purchase in a real-world store.
“In the future these kind of multi-modal AIs will make the conversation and the engagement you have with the AI much much better,” Huang said.
Cloud Gaming Goes Global
Huang also detailed how NVIDIA is expanding its cloud gaming network through partnerships with global telecommunications companies.
GeForce NOW, NVIDIA’s cloud gaming service, transforms underpowered or incompatible devices into a powerful GeForce gaming PC with access to popular online game stores.
Taiwan Mobile joins industry leaders rolling out GeForce NOW, including Korea’s LG U+, Japan’s Softbank, and Russia’s Rostelecom in partnership with GFN.RU. Additionally, Telefonica will kick-off a cloud gaming proof-of-concept in Spain.
Huang showed what’s now possible with a real-time demo of a gamer playing Assetto Corsa Competizione on GeForce Now — as a cameraman watched over his shoulder — on a smartphone over a 5G network. The gamer navigated through the demanding racing game’s action with no noticeable lag.
The mobile version of GeForce NOW for Android devices is available in Korea and will be available widely later this year, with a preview on display at Mobile World Congress Los Angeles.
“These servers are going to be the same servers that run intelligent agriculture and intelligent retail,” Huang said. “The future is software defined and these low latency services that need to be deployed at the edge can now be provisioned at the edge with these servers.”
A Trillion New Devices
The opportunities for AI, IoT, cloud gaming, augmented reality and 5G network acceleration are huge — with a trillion new IoT devices to be produced between now and 2035, according to industry estimates.
And GPUs are up to the challenge, with GPU computing power growing 300,000x from 2013, driving down the cost per teraflop of computing power, even as gains in CPU performance level off, Huang said.
NVIDIA is well positioned to help telcos and enterprises make the most of this by helping customers combine AI algorithms, powerful GPUs, smart NICs — or network interface cards, cloud native technologies, the NVIDIA EGX accelerated edge computing platform, and 5G high-speed wireless networks.
Huang compared all these elements to the powerful “infinity stones” featured in Marvel’s movies and comic books.
“What you’re looking at are the six miracles that will make it possible to put 5G at the edge, to virtualize the 5G data center and create a world of smart everything,” Huang said, and that, in turn, will add intelligence to everything in the world around us.
“This will be a pillar, a foundation for the smart everything revolution,” Huang said.
Deep learning applications are data hungry. The more high-quality labeled data a developer feeds an AI model, the more accurate its inferences.
But creating robust datasets is the biggest obstacle for data scientists and developers building machine learning models, says Gaurav Gupta, CEO of TrainingData.io, a member of the NVIDIA Inception virtual accelerator program.
The startup has created a web platform to help researchers and companies manage their data labeling workflow and use AI-assisted segmentation tools to improve the quality of their training datasets.
“When the labels are accurate, then the AI models learn faster and they reach higher accuracy faster,” said Gupta.
The company’s web interface, which runs on NVIDIA T4 GPUs for inference in Google Cloud, helped one healthcare radiology customer speed up labeling by 10x and decrease its labeling error rate by more than 15 percent.
The Devil Is in the Details
The higher the data quality, the less data needed to achieve accurate results. A machine learning model can produce the same results after training on a million images with low-accuracy labels, Gupta says, or just 100,000 images with high-accuracy labels.
Getting data labeling right the first time is no easy task. Many developers outsource data labeling to companies or crowdsourced workers. It may take weeks to get back the annotated datasets, and the quality of the labels is often poor.
A rough annotated image of a car on the street, for example, may have a segmentation polygon around it that also includes part of the pavement, or doesn’t reach all the way to the roof of the car. Since neural networks parse images pixel by pixel, every mislabeled pixel makes the model less precise.
That margin of error is unacceptable for training a neural network that will eventually interact with people and objects in the real world — for example, identifying tumors from an MRI scan of the brain or controlling an autonomous vehicle.
Developers can manage their data labeling through TrainingData.io’s web interface, while administrators can assign image labeling tasks to annotators, view metrics about individual data labelers’ performance and review the actual image annotations.
Using AI to Train Better AI
When a data scientist first runs a machine learning model, it may only be 60 percent accurate. The developer then iterates several times to improve the performance of the neural network, each time adding new training data.
TrainingData.io is helping AI developers across industries use their early-stage machine learning models to ease the process of labeling new training data for future versions of the neural networks — a process known as active learning.
With this technique, the developer’s initial machine learning model can take the first pass at annotating the next set of training data. Instead of starting from scratch, annotators can just go through and tweak the AI-generated labels, saving valuable time and resources.
The startup offers active learning for data labeling across multiple industries. For healthcare data labeling, its platform integrates with the NVIDIA Clara Deploy SDK, allowing customers to use the software toolkit for AI-assisted segmentation of healthcare datasets.
Choose Your Own Annotation Adventure
TrainingData.io chose to deploy its platform on cloud-based GPUs to easily scale usage up and down based on customer demand. Researchers and companies using the tool can choose whether to use the interface online, connected to the cloud backend, or instead use a containerized application running on their own on-premises GPU system.
“It’s important for AI teams in healthcare to be able to protect patient information,” Gupta said. “Sometimes it’s necessary for them to manage the workflow of annotating data and training their machine learning models within the security of their private network. That’s why we provide Docker images to support on-premises annotation on local datasets.”
Balzano, a Swiss startup building deep learning models for radiologists, is using TrainingData.io’s platform linked to an on-premises server of NVIDIA V100 Tensor Core GPUs. To develop training datasets for its musculoskeletal orthopedics AI tools, the company labels a few hundred radiology images each month. Adopting TrainingData.io’s interface saved the company a year’s worth of engineering effort compared to building a similar solution from scratch.
“TrainingData.io’s features allow us to annotate and segment anatomical features of the knee and cartilage more efficiently,” said Stefan Voser, chief operating officer and product manager at Balzano, which is also an Inception program member. “As we ramp up the annotation process, this platform will allow us to leverage AI capabilities and ensure the segmented images are high quality.”
Balzano and TrainingData.io will showcase their latest demos in NVIDIA booth 10939 at the annual meeting of the Radiological Society of North America, Dec. 1-6 in Chicago.
Posted by Michael S. Ryoo, Research Scientist and AJ Piergiovanni, Student Researcher, Robotics at Google
Video understanding is a challenging problem. Because a video contains spatio-temporal data, its feature representation is required to abstract both appearance and motion information. This is not only essential for automated understanding of the semantic content of videos, such as web-video classification or sport activity recognition, but is also crucial for robot perception and learning. Just like humans, an input from a robot’s camera is seldom a static snapshot of the world, but takes the form of a continuous video.
The abilities of today’s deep learning models are greatly dependent on their neural architectures. Convolutional neural networks (CNNs) for videos are normally built by manually extending known 2D architectures such as Inception and ResNet to 3D or by carefully designing two-stream CNN architectures that fuse together both appearance and motion information. However, designing an optimal video architecture to best take advantage of spatio-temporal information in videos still remains an open problem. Although neural architecture search (e.g., Zoph et al, Real et al) to discover good architectures has been widely explored for images, machine-optimized neural architectures for videos have not yet been developed. Video CNNs are typically computation- and memory-intensive, and designing an approach to efficiently search for them while capturing their unique properties has been difficult.
In response to these challenges, we have conducted a series of studies into automatic searches for more optimal network architectures for video understanding. We showcase three different neural architecture evolution algorithms: learning layers and their module configuration (EvaNet); learning multi-stream connectivity (AssembleNet); and building computationally efficient and compact networks (TinyVideoNet). The video architectures we developed outperform existing hand-made models on multiple public datasets by a significant margin, and demonstrate a 10x~100x improvement in network runtime.
EvaNet: The first evolved video architectures EvaNet, which we introduce in “Evolving Space-Time Neural Architectures for Videos” at ICCV 2019, is the very first attempt to design neural architecture search for video architectures. EvaNet is a module-level architecture search that focuses on finding types of spatio-temporal convolutional layers as well as their optimal sequential or parallel configurations. An evolutionary algorithm with mutation operators is used for the search, iteratively updating a population of architectures. This allows for parallel and more efficient exploration of the search space, which is necessary for video architecture search to consider diverse spatio-temporal layers and their combinations. EvaNet evolves multiple modules (at different locations within the network) to generate different architectures.
Our experimental results confirm the benefits of such video CNN architectures obtained by evolving heterogeneous modules. The approach often finds that non-trivial modules composed of multiple parallel layers are most effective as they are faster and exhibit superior performance to hand-designed modules. Another interesting aspect is that we obtain a number of similarly well-performing, but diverse architectures as a result of the evolution, without extra computation. Forming an ensemble with them further improves performance. Due to their parallel nature, even an ensemble of models is computationally more efficient than the other standard video networks, such as (2+1)D ResNet. We have open sourced the code.
Examples of various EvaNet architectures. Each colored box (large or small) represents a layer with the color of the box indicating its type: 3D conv. (blue), (2+1)D conv. (orange), iTGM (green), max pooling (grey), averaging (purple), and 1×1 conv. (pink). Layers are often grouped to form modules (large boxes). Digits within each box indicate the filter size.
AssembleNet: Building stronger and better (multi-stream) models In “AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures”, we look into a new method of fusing different sub-networks with different input modalities (e.g., RGB and optical flow) and temporal resolutions. AssembleNet is a “family” of learnable architectures that provide a generic approach to learn the “connectivity” among feature representations across input modalities, while being optimized for the target task. We introduce a general formulation that allows representation of various forms of multi-stream CNNs as directed graphs, coupled with an efficient evolutionary algorithm to explore the high-level network connectivity. The objective is to learn better feature representations across appearance and motion visual clues in videos. Unlike previous hand-designed two-stream models that use late fusion or fixed intermediate fusion, AssembleNet evolves a population of overly-connected, multi-stream, multi-resolution architectures while guiding their mutations by connection weight learning. We are looking at four-stream architectures with various intermediate connections for the first time — 2 streams per RGB and optical flow, each one at different temporal resolutions.
The figure below shows an example of an AssembleNet architecture, found by evolving a pool of random initial multi-stream architectures over 50~150 rounds. We tested AssembleNet on two very popular video recognition datasets: Charades and Moments-in-Time (MiT). Its performance on MiT is the first above 34%. The performances on Charades is even more impressive at 58.6% mean Average Precision (mAP), whereas previous best known results are 42.5 and 45.2.
The representative AssembleNet model evolved using the Moments-in-Time dataset. A node corresponds to a block of spatio-temporal convolutional layers, and each edge specifies their connectivity. Darker edges mean stronger connections. AssembleNet is a family of learnable multi-stream architectures, optimized for the target task.
A figure comparing AssembleNet with state-of-the-art, hand-designed models on Charades (left) and Moments-in-Time (right) datasets. AssembleNet-50 or AssembleNet-101 has an equivalent number of parameters to a two-stream ResNet-50 or ResNet-101.
Tiny Video Networks: The fastest video understanding networks In order for a video CNN model to be useful for devices operating in a real-world environment, such as that needed by robots, real-time, efficient computation is necessary. However, achieving state-of-the-art results on video recognition tasks currently requires extremely large networks, often with tens to hundreds of convolutional layers, that are applied to many input frames. As a result, these networks often suffer from very slow runtimes, requiring at least 500+ ms per 1-second video snippet on a contemporary GPU and 2000+ ms on a CPU. In Tiny Video Networks, we address this by automatically designing networks that provide comparable performance at a fraction of the computational cost. Our Tiny Video Networks (TinyVideoNets) achieve competitive accuracy and run efficiently, at real-time or better speeds, within 37 to 100 ms on a CPU and 10 ms on a GPU per ~1 second video clip, achieving hundreds of times faster speeds than the other human-designed contemporary models.
These performance gains are achieved by explicitly considering the model run-time during the architecture evolution and forcing the algorithm to explore the search space while including spatial or temporal resolution and channel size to reduce computations. The below figure illustrates two simple, but very effective architectures, found by TinyVideoNet. Interestingly the learned model architectures have fewer convolutional layers than typical video architectures: Tiny Video Networks prefers lightweight elements, such as 2D pooling, gating layers, and squeeze-and-excitation layers. Further, TinyVideoNet is able to jointly optimize parameters and runtime to provide efficient networks that can be used by future network exploration.
TinyVideoNet (TVN) architectures evolved to maximize the recognition performance while keeping its computation time within the desired limit. For instance, TVN-1 (top) runs at 37 ms on a CPU and 10ms on a GPU. TVN-2 (bottom) runs at 65ms on a CPU and 13ms on a GPU.
CPU runtime of TinyVideoNet models compared to prior models (left) and runtime vs. model accuracy of TinyVideoNets compared to (2+1)D ResNet models (right). Note that TinyVideoNets take a part of this time-accuracy space where no other models exist, i.e., extremely fast but still accurate.
Conclusion To our knowledge, this is the very first work on neural architecture search for video understanding. The video architectures we generate with our new evolutionary algorithms outperform the best known hand-designed CNN architectures on public datasets, by a significant margin. We also show that learning computationally efficient video models, TinyVideoNets, is possible with architecture evolution. This research opens new directions and demonstrates the promise of machine-evolved CNNs for video understanding.
Acknowledgements This research was conducted by Michael S. Ryoo, AJ Piergiovanni, and Anelia Angelova. Alex Toshev and Mingxing Tan also contributed to this work. We thank Vincent Vanhoucke, Juhana Kangaspunta, Esteban Real, Ping Yu, Sarah Sirajuddin, and the Robotics at Google team for discussion and support.
Imagine a visit to your doctor’s office in which your physician asks you how you’ve been feeling, whether your medication is working or if the shoulder pain from an old fall is still bothering you — and his or her focus is entirely on you and that conversation.
The doctor is looking at you, not at a computer screen. He or she isn’t moving a mouse around hunting for an old record or pecking on the keyboard to enter a diagnosis code.
This sounds like an ideal scenario, but as most people know from their own visits to the doctor, it’s far from the norm today.
But experts say that in an exam room of the future enhanced by artificial intelligence, the doctor would be able to call up a lab result or prescribe a new medicine with a simple voice command. She or he wouldn’t be distracted by entering symptoms into your electronic health record (EHR). And at the end of the visit, the essential elements of the conversation would have been securely captured and distilled into concise documentation that can be shared with nurses, specialists, insurance companies or anyone else you’ve entrusted with your care.
A new strategic partnership between Microsoft and Nuance Communications Inc. announced today will work to accelerate and deliver this level of ambient clinical intelligence to exam rooms, allowing ambient sensing and conversational AI to take care of some of the more burdensome administrative tasks and to provide clinical documentation that writes itself. That, in turn, will allow doctors to turn their attention fully to taking care of patients.
Of course, there are still immense technical challenges to getting to that ideal scenario of the future. But the companies say they believe that they already have a strong foundation in features from Nuance’s ambient clinical intelligence (ACI) technology unveiled earlier this year and Microsoft’s Project EmpowerMD Intelligent Scribe Service. Both are using AI technologies to learn how to convert doctor-patient conversations into useful clinical documentation, potentially reducing errors, saving doctors’ time and improving the overall physician experience.
“Physicians got into medicine because they wanted to help and heal people, but they are spending a lot of their time today outside of the care process,” said Joe Petro, Nuance executive vice president and chief technology officer. “They’re entering in data to make sure the appropriate bill can be generated. They’re capturing insights for population health and quality measures. And although this data is all important, it’s really outside a physician’s core focus on treating that patient.”
YouTube Video
Primary care doctors spend two hours on administrative tasks for every hour they’re involved in direct patient care, studies have shown. If they don’t capture a patient’s complaint or treatment plan during or shortly after an exam, that documentation burden will snowball as the day goes on. In another recent study, physicians reported one to two hours of after-hours work each night, mostly related to administrative tasks.
This shift to digital medical record keeping and so-called ‘meaningful use’ regulations is well-intentioned and has provided some important benefits, said Dr. Ranjani Ramamurthy, senior director at Microsoft Healthcare who leads the company’s EmpowerMD research.
People no longer have to worry about not being able to read a doctor’s handwriting or information that never makes it into the right paper file. But the unintended consequence has been that doctors are sometimes forced to focus on their computers and administrative tasks instead of their patients, she said.
After starting her career in computer science, Ramamurthy went back to school to get a medical degree and pursue cancer research. But as she walked the halls of the hospital every day, she couldn’t help thinking that she was missing an opportunity to use her background to create tech solutions that could reinvigorate the doctor-patient relationship.
Ramamurthy noted that most physicians got into healthcare because they want to use their skills and expertise to treat patients, not to feel tethered to their keyboards.
“We need to work on building frictionless systems that take care of the doctors so they can do what they do best, which is take care of patients,” she said.
Built on Microsoft Azure — and working in tandem with the EHR — this new technology will marry the two companies’ strengths in developing ambient sensing and conversational AI solutions. Those include ambient listening with patient consent, wake-up word, voice biometrics, signal enhancement, document summarization, natural language understanding, clinical intelligence and text-to-speech.
Nuance is a leading provider of AI-powered clinical documentation and decision-making support for physicians. Leveraging deep strategic partnerships with the major providers of EHRs, the company has spent decades developing medically relevant speech recognition and processing solutions such as its Dragon Medical One platform, which allows doctors to easily and naturally enter a patient’s story and relevant information into an EHR using dictation. Nuance conversational AI technologies are already used by more than 500,000 physicians worldwide, as well as in 90 percent of U.S. hospitals.
Microsoft brings deep research investments in AI and partner-driven healthcare technologies, commercial relationships with nearly 170,000 healthcare organizations, and enterprise-focused cloud and AI services that accelerate and enable scalable commercial solutions. Earlier this month, for instance, Microsoft announced a strategic collaboration to combine its AI technology with Novartis’ deep life sciences expertise to address challenges in developing new drugs.
In other areas, Azure Cognitive Services offers easy-to-deploy AI tools for speech recognition, computer vision and language understanding, and trusted Azure cloud services can support the user’s compliance with privacy and regulatory requirements for healthcare organizations.
As part of the agreement, Nuance will migrate the majority of its current on-site internal infrastructure and hosted products to Microsoft Azure. Nuance already is a Microsoft Office 365 customer for its more than 8,500 employees worldwide, empowering them with the latest in collaboration and communications tools, including Microsoft Teams.
“We need to work on building frictionless systems that take care of the doctors so they can do what they do best, which is take care of patients.”
~ Dr. Ranjani Ramamurthy, senior director at Microsoft Healthcare
“Just capturing a conversation between two people has been a thorny technical problem for a long time, and a lot of companies have attempted to crack it,” Petro said. “This partnership brings two trusted healthcare superpowers together to solve some of the most difficult challenges and also to leverage the most innovative advances we’ve made in AI, speech and natural language processing.”
The companies will expand upon Nuance’s early success with ACI and expect the technology to be introduced to an initial set of physician specialties in early 2020, and then it will be expanded to numerous other medical specialties over the next few years, Petro said. Initially, the ACI output may be checked by a remote reviewer with medical expertise to provide an important quality check and produce additional training data for the AI models. Once the system has proven its accuracy for a given physician, the ACI documentation will go directly to that physician, who can review it, make any necessary revisions and sign off on a treatment plan all in real-time, Petro said.
With a patient’s consent, ACI is designed to securely ingest and synthesize patient-doctor conversations, integrate that data with information from an EHR, populate a patient’s chart and also help the EHR deliver intelligent recommendations to the doctor.
With innovations in multi-party speech recognition, language understanding and computer vision, these tools can listen to the encounter between the doctor and a patient who grants consent, sense whether they’re pointing to a left knee or right knee when verbally describing a particular pain, extract medically relevant details and translate what just occurred in the exam room into actionable clinical documentation and care suggestions.
“Moving forward, we recognize that reducing the burden of clinical documentation is just the beginning,” said Dr. Greg Moore, Microsoft’s corporate vice president for health technology and alliances. “As the core AI improves and becomes more capable, it will be able to understand much more deeply what is going on by observing doctors and nurses in their day to day work. Ambient clinical intelligence will be able to work in tandem with the EHR to help convert those observations into supportive, augmenting actions.”
For instance, an AI-enabled system can learn to recognize when a doctor is talking to a patient about a new medication, and it can automatically review past conversations as well as the patient’s history to reduce the risk of a drug interaction or allergic reaction. Or it can mine a patient’s complicated medical history with new reported symptoms and offer suggestions for potential diagnoses for the doctor to consider.
In addition, the two companies will open up the ACI platform to an ecosystem of partners than can bring other highly valuable AI innovations to the exam room or at the bedside where the ambient sensing device will be present.
“We want ambient clinical intelligence to assist the EHR in delivering recommendations at the time when it matters — not three days later on your patient portal or when a nurse follows up, but when the doctor and patient are face to face and when that information can actually inform care,” Ramamurthy said.





 Marta Smolarek is a Program Manager in the Amazon Text-to-Speech team. At work she connects the dots. In her spare time, she loves to go camping with her family.
Marta Smolarek is a Program Manager in the Amazon Text-to-Speech team. At work she connects the dots. In her spare time, she loves to go camping with her family.



















{kind=link}
{kind=link}