Author: torontoai
[D] Why is unsupervised pre-training successful in NLP ?
For examples, BERT and GPT-2, both achieve sota across several NLP tasks.
submitted by /u/stopwind
[link] [comments]
[D] The gradient descent renaissance
The field of machine learning underwent massive changes in the 2010’s. At the beginning, the field saw diverse approaches applied to a variety of topics and data structures. Then Alexnet blew away the competition for the Imagenet challenge with his CNN, and the field was forever changed. However, there was a warming up phase. Caffe’s first release was in 2013. Tensorflow and Keras were first released in 2015. Pytorch in 2017. Before Caffe’s first release, groups were largely ill-equipped to do convolutional neural network research as they did not possess the resources to develop an efficient library that would run on the GPU. Research continued mostly the same from 2010 – 2014 while these libraries were being developed. Then the real explosion happened from 2014-2016, where paper submissions (and subsequent accepted papers) exploded at various conferences. And of course, as more people explored CNN based machine learning, the better the community got at designing them, so naturally, the scores on ILSVRC get better and better. Various other empirical benchmarks have been used in a standardized test fashion to explicitly compare methods (models).
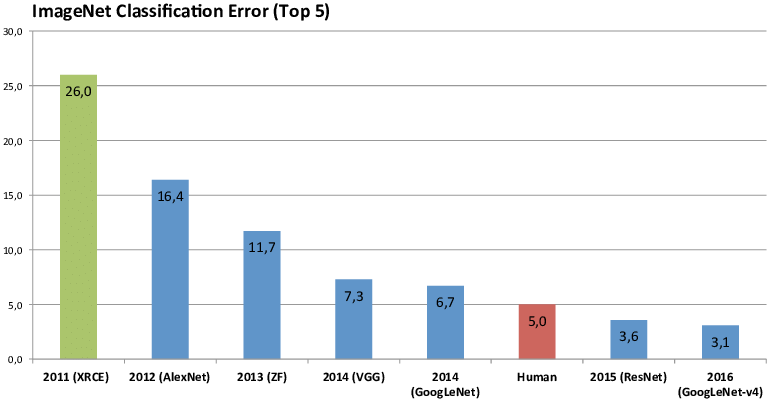{kind=link}
Prior to the neural network revolution, and even a little after its beginning, it was still believed that there were some problems that are still unsolvable for learning machines, namely Go. The anomaly to these statistics is of course Deepmind and the like. They showed approximating the value function via a CNN is able to master seven classic Atari games. This was in 2013. In March of 2016, they beat the world champion of Go with a match score of 4-1. AlphaGo showcased the power of combining neural networks with traditional algorithms, which largely went against the tide of end-to-end approaches. In April of 2019, OpenAI 5 stomped the world champions in Dota 2. Deepmind showcased their StarCraft II AI at Blizzcon in November 2019, beating everyone, including the last world champion 4-0.
As the 2010’s wrap up, I encourage you to take a step back from your work and appreciate how far we’ve come. What was your favorite moment of this decade?
submitted by /u/Turings_Ego
[link] [comments]
[P] How to get rid of boilerplate if-statements and switches
TL;DR I wrote this package and I find it useful in my projects
The problem
It’s common to specify script parameters in yaml config files. For example:
models: modelA: densenet121: pretrained: True memory_efficient: True modelB: resnext50_32x4d: pretrained: True Usually, the config file is loaded and then various if-statements or switches are used to instantiate objects etc:
if args.models["modelA"] == "densenet121": modelA = torchvision.models.densenet121(pretrained = args.pretrained) elif args.models["modelA"] == "googlenet": modelA = torchvision.models.googlenet(pretrained = args.pretrained) elif args.models["modelA"] == "resnet50": modelA = torchvision.models.resnet50(pretrained = args.pretrained) elif args.models["modelA"] == "inception_v3": modelA = torchvision.models.inception_v3(pretrained = args.pretrained) ... This is kind of annoying to do, and every time PyTorch adds new classes or functions that you want access to, you need to add new cases to your giant if-statement.
Use this package and get rid of those if-statements
So I wrote easy_module_attribute_getter.
With this package, the above if-statements get reduced to this:
from easy_module_attribute_getter import PytorchGetter pytorch_getter = PytorchGetter() models = pytorch_getter.get_multiple("model", args.models) “models” is a dictionary that maps from strings to the desired objects.
Automatically have yaml access to new classes when you upgrade PyTorch
The nice thing about this package is that if you upgrade to a new version of PyTorch which has 20 new classes, you don’t have to change anything. You automatically have access to all the new classes, and you can specify them in your yaml file.
Merge or override options at the command line
You can also merge or override complex config options (i.e. nested dictionaries) at the command line.
For example, if we want a modelC in addition to the 2 models specified in the yaml file:
python example.py --models {modelC: {googlenet: {pretrained: True, aux_logits: True}}} Now the models dictionary will contain modelA, modelB, and modelC. Or if we want to override the models option in the config file:
python example.py --models~OVERRIDE~ {modelC: {googlenet: {pretrained: True, aux_logits: True}}} Now the models dictionary will contain only modelC.
Transforms and optimizers
There are also some nice features specifically for transforms and optimizers which you can read about here.
Register your own modules
You can register your own modules so that you have direct yaml access to them as well.
Also note that the base class EasyModuleAttributeGetter, isn’t specific to PyTorch, but I wrote the child class PyTorchGetter since that’s what I’m using this package for.
I hope someone finds this useful!
submitted by /u/VanillaCashew
[link] [comments]
Developing Deep Learning Models for Chest X-rays with Adjudicated Image Labels
With millions of diagnostic examinations performed annually, chest X-rays are an important and accessible clinical imaging tool for the detection of many diseases. However, their usefulness can be limited by challenges in interpretation, which requires rapid and thorough evaluation of a two-dimensional image depicting complex, three-dimensional organs and disease processes. Indeed, early-stage lung cancers or pneumothoraces (collapsed lungs) can be missed on chest X-rays, leading to serious adverse outcomes for patients.
Advances in machine learning (ML) present an exciting opportunity to create new tools to help experts interpret medical images. Recent efforts have shown promise in improving lung cancer detection in radiology, prostate cancer grading in pathology, and differential diagnoses in dermatology. For chest X-ray images in particular, large, de-identified public image sets are available to researchers across disciplines, and have facilitated several valuable efforts to develop deep learning models for X-ray interpretation. However, obtaining accurate clinical labels for the very large image sets needed for deep learning can be difficult. Most efforts have either applied rule-based natural language processing (NLP) to radiology reports or relied on image review by individual readers, both of which may introduce inconsistencies or errors that can be especially problematic during model evaluation. Another challenge involves assembling datasets that represent an adequately diverse spectrum of cases (i.e., ensuring inclusion of both “hard” cases and “easy” cases that represent the full spectrum of disease presentation). Finally, some chest X-ray findings are non-specific and depend on clinical information about the patient to fully understand their significance. As such, establishing labels that are clinically meaningful and have consistent definitions can be a challenging component of developing machine learning models that use only the image as input. Without standardized and clinically meaningful datasets as well as rigorous reference standard methods, successful application of ML to interpretation of chest X-rays will be hindered.
To help address these issues, we recently published “Chest Radiograph Interpretation with Deep Learning Models: Assessment with Radiologist-adjudicated Reference Standards and Population-adjusted Evaluation” in the journal Radiology. In this study we developed deep learning models to classify four clinically important findings on chest X-rays — pneumothorax, nodules and masses, fractures, and airspace opacities. These target findings were selected in consultation with radiologists and clinical colleagues, so as to focus on conditions that are both critical for patient care and for which chest X-ray images alone are an important and accessible first-line imaging study. Selection of these findings also allowed model evaluation using only de-identified images without additional clinical data.
Models were evaluated using thousands of held-out images from each dataset for which we collected high-quality labels using a panel-based adjudication process among board-certified radiologists. Four separate radiologists also independently reviewed the held-out images in order to compare radiologist accuracy to that of the deep learning models (using the panel-based image labels as the reference standard). For all four findings and across both datasets, the deep learning models demonstrated radiologist-level performance. We are sharing the adjudicated labels for the publicly available data here to facilitate additional research.
Data Overview
This work leveraged over 600,000 images sourced from two de-identified datasets. The first dataset was developed in collaboration with co-authors at the Apollo Hospitals, and consists of a diverse set of chest X-rays obtained over several years from multiple locations across the Apollo Hospitals network. The second dataset is the publicly available ChestX-ray14 image set released by the National Institutes of Health (NIH). This second dataset has served as an important resource for many machine learning efforts, yet has limitations stemming from issues with the accuracy and clinical interpretation of the currently available labels.
 |
| Chest X-ray depicting an upper left lobe pneumothorax identified by the model and the adjudication panel, but missed by the individual radiologist readers. Left: The original image. Right: The same image with the most important regions for the model prediction highlighted in orange. |
Training Set Labels Using Deep Learning and Visual Image Review
For very large datasets consisting of hundreds of thousands of images, such as those needed to train highly accurate deep learning models, it is impractical to manually assign image labels. As such, we developed a separate, text-based deep learning model to extract image labels using the de-identified radiology reports associated with each X-ray. This NLP model was then applied to provide labels for over 560,000 images from the Apollo Hospitals dataset used for training the computer vision models.
To reduce noise from any errors introduced by the text-based label extraction and also to provide the relevant labels for a substantial number of the ChestX-ray14 images, approximately 37,000 images across the two datasets were visually reviewed by radiologists. These were separate from the NLP-based labels and helped to ensure high quality labels across such a large, diverse set of training images.
Creating and Sharing Improved Reference Standard Labels
To generate high-quality reference standard labels for model evaluation, we utilized a panel-based adjudication process, whereby three radiologists reviewed all final tune and test set images and resolved disagreements through discussion. This often allowed difficult findings that were initially only detected by a single radiologist to be identified and documented appropriately. To reduce the risk of bias based on any individual radiologist’s personality or seniority, the discussions took place anonymously via an online discussion and adjudication system.
Because the lack of available adjudicated labels was a significant initial barrier to our work, we are sharing with the research community all of the adjudicated labels for the publicly available ChestX-ray14 dataset, including 2,412 training/validation set images and 1,962 test set images (4,374 images in total). We hope that these labels will facilitate future machine learning efforts and enable better apples-to-apples comparisons between machine learning models for chest X-ray interpretation.
Future Outlook
This work presents several contributions: (1) releasing adjudicated labels for images from a publicly available dataset; (2) a method to scale accurate labeling of training data using a text-based deep learning model; (3) evaluation using a diverse set of images with expert-adjudicated reference standard labels; and ultimately (4) radiologist-level performance of deep learning models for clinically important findings on chest X-rays.
However, in regards to model performance, achieving expert-level accuracy on average is just a part of the story. Even though overall accuracy for the deep learning models was consistently similar to that of radiologists for any given finding, performance for both varied across datasets. For example, the sensitivity for detecting pneumothorax among radiologists was approximately 79% for the ChestX-ray14 images, but was only 52% for the same radiologists on the other dataset, suggesting a more difficult collection cases in the latter. This highlights the importance of validating deep learning tools on multiple, diverse datasets and eventually across the patient populations and clinical settings in which any model is intended to be used.
The performance differences between datasets also emphasize the need for standardized evaluation image sets with accurate reference standards in order to allow comparison across studies. For example, if two different models for the same finding were evaluated using different datasets, comparing performance would be of minimal value without knowing additional details such as the case mix, model error modes, or radiologist performance on the same cases.
Finally, the model often identified findings that were consistently missed by radiologists, and vice versa. As such, strategies that combine the unique “skills” of both the deep learning systems and human experts are likely to hold the most promise for realizing the potential of AI applications in medical image interpretation.
Acknowledgements
Key contributors to this project at Google include Sid Mittal, Gavin Duggan, Anna Majkowska, Scott McKinney, Andrew Sellergren, David Steiner, Krish Eswaran, Po-Hsuan Cameron Chen, Yun Liu, Shravya Shetty, and Daniel Tse. Significant contributions and input were also made by radiologist collaborators Joshua Reicher, Alexander Ding, and Sreenivasa Raju Kalidindi. The authors would also like to acknowledge many members of the Google Health radiology team including Jonny Wong, Diego Ardila, Zvika Ben-Haim, Rory Sayres, Shahar Jamshy, Shabir Adeel, Mikhail Fomitchev, Akinori Mitani, Quang Duong, William Chen and Sahar Kazemzadeh. Sincere appreciation also goes to the many radiologists who enabled this work through their expert image interpretation efforts throughout the project.

Introducing medical speech-to-text with Amazon Transcribe Medical
We are excited to announce Amazon Transcribe Medical, a new HIPAA-eligible, machine learning automatic speech recognition (ASR) service that allows developers to add medical speech-to-text capabilities to their applications. Transcribe Medical provides accurate and affordable medical transcription, enabling healthcare providers, IT vendors, insurers, and pharmaceutical companies to build services that help physicians, nurses, researchers, and claims agents improve the efficiency of medical note-taking. With this new service, you can complete clinical documentation faster, more accurately, securely, and with less effort, whether in a clinician’s office, research lab, or on the phone with an insurance claim agent.
The challenge in healthcare and life sciences
Following the implementation of the HITECH Act (Health Information Technology for Economic and Clinical Health), physicians are required to conduct detailed data entry into electronic health record (EHR) systems. However, clinicians can spend up to an average of six additional hours per day, on top of existing medical tasks, just writing notes for EHR data entry. Not only is the process time consuming and exhausting for physicians, it is a leading factor of workplace burnout and stress that distracts physicians from engaging patients attentively, resulting in poorer patient care and rushed visits. While medical scribes have been employed to assist with manual note taking, the solution is expensive, difficult to scale across thousands of medical facilities, and some patients find the presence of a scribe uncomfortable, leading to less candid discussions about symptoms. Existing front-end dictation software also requires physicians to take training or speak unnaturally, such as explicitly calling out punctuation, which is disruptive and inefficient. Additionally, to help alleviate the burden of note taking, many healthcare providers send physicians’ voice notes to manual transcription services, which can have turnaround times between one and three business days. Additionally, as the life sciences industry moves toward precision medicine, pharmaceutical companies increasingly need to collect real-world evidence (RWE) of their medications’ efficacy or cause potential side effects. However, RWE is often acquired during phone calls that then need to be transcribed.
Transcribe Medical helps address these challenges by enabling an accurate, affordable, and easy-to-use medical speech recognition service.
Improving medical transcription with machine learning
Transcribe Medical offers an easy-to-use streaming API that integrates into any voice-enabled application and works with virtually any device that has a microphone. The service is designed to transcribe medical speech for primary care and can be deployed at scale across thousands of healthcare providers to provide affordable, consistent, secure, and accurate note-taking for clinical staff and facilities. Additional features like automatic punctuation and intelligent punctuation enable you to speak naturally, without having to vocalize awkward and explicit punctuation commands as part of the discussion, such as “add comma” or “exclamation point.” Moreover, the service supports both medical dictation and conversational transcription.
Transcribe Medical is a fully managed ASR service and therefore requires no provisioning or management of servers. You need only to call the public API and start passing an audio stream to the service over a secure WebSocket connection. Transcribe Medical sends back a stream of text in real time. Experience in machine learning isn’t required to use Transcribe Medical, and the service is covered under AWS’s HIPAA eligibility and BAA. Any customer that enters into a BAA with AWS can use AWS HIPAA-eligible services to process and store PHI. AWS does not use PHI to develop or improve AWS services, and the AWS standard BAA language also requires BAA customers to encrypt all PHI at rest and in transit when using AWS services.
Bringing the focus back to patients
Cerner is a healthcare IT leader whose EHR systems are deployed in thousands of medical centers across the world. Using Amazon Transcribe Medical, Cerner’s voice scribe application can automatically and securely transcribe physicians’ conversations with patients. They can analyze and summarize the transcripts for important health information, and physicians can enter the information into the EHR system. The result is increased note-taking efficiency, lower physician burnout, and ultimately improved patient care and satisfaction.
“Extreme accuracy in clinical documentation is critical to workflows and overall caregiver satisfaction. By leveraging Amazon Transcribe Medical’s transcription API, Cerner is in initial development of a digital voice scribe that automatically listens to clinician-patient interactions and unobtrusively captures the dialogue in text form. From there, our solution will intelligently translate the concepts for entry into the codified component in the Cerner EHR system,” said Jacob Geers, solutions strategist at Cerner Corporation.
We’ve also heard from other customers using Transcribe Medical. For example, George Seegan, senior data scientist at Amgen, said, “In pharmacovigilance, we want to accurately review recorded calls from patients or Health Care Providers, in order to identify any reported potential side effects associated with medicinal products. Amazon Transcribe Medical produces text transcripts from recorded calls that allow us to extract meaningful insights about medicines and any reported side effects. In this way, we can quickly detect, collect, assess, report, and monitor adverse effects to the benefit of patients globally.”
Vadim Khazan, president of technology at SoundLines, said, “SoundLines supports HealthChannels’ skilled labor force at the point of care by incorporating meaningful and impact focused technology such as Amazon’s medically accurate speech-to-text solution, Amazon Transcribe Medical, into the workflows of our network of Care Team Assistants, Medical Scribes, and Navigators. This allows the clinicians we serve to focus on patients instead of spending extra cycles on manual note-taking. Amazon Transcribe Medical easily integrates into the HealthChannels platform, feeding its transcripts directly into downstream analytics. For the 3,500 healthcare partners relying on our care team optimization strategies for the past 15 years, we’ve significantly decreased the time and effort required to get to insightful data.”
Improving patient care and satisfaction is a passion that AWS shares with our healthcare and life science customers. We’re incredibly excited about the role that Transcribe Medical can play in supporting that mission.
About the author
 Vasi Philomin is the GM for Machine Learning & AI at AWS, responsible for Amazon Lex, Polly, Transcribe, Translate and Comprehend.
Vasi Philomin is the GM for Machine Learning & AI at AWS, responsible for Amazon Lex, Polly, Transcribe, Translate and Comprehend.
[R] Inteligent decision support system with explainable techniques
Hello everyone,
we are researchers from TU-Berlin and UL FRI, and we are doing a research on how people interact with certain explainable AI techniques. We are currently in the process of gathering data and we need people to take part in our survey. If you have 15-20 minutes to spare to participate that would be extremely helpfull. All the details about the survey are explained in the survey itself.
The survey is reachable at this link: https://dss.vicos.si/. It is meant to be solved on a computer.
After we analyze the data we will obviously share the paper 🙂 Thank you in advance!
submitted by /u/the_juan_1
[link] [comments]
Sr. IoT Software Engineer or Sr. Embedded Software Engineer – Splunk – Toronto, ON
From Splunk – Tue, 03 Dec 2019 12:11:53 GMT – View all Toronto, ON jobs
[P] Anyfig – configuration manager. Argparse alternative. Great if you have complex configurations
Hi everyone!
In my own ML projects, I’ve been using Python classes to define my settings such as batch size and learning rate. In many ways, it has been more powerful than Argparse, so I thought I’d make it into a package. Without any more fuzz, introducing Anyfig!! (Gihub repo)
Anyfig is a Python library for creating configurations (settings) at runtime. Anyfig utilizes Python classes which empowers the developer to put anything, from strings to custom objects in the config. Hence the name Any(con)fig.
The basics
- Decorate a class with ‘@anyfig.config_class’.
- Add config-parameters as attributes in the class
- Call the ‘setup_config’ function to instantiate the config object
import anyfig import random @anyfig.config_class class FooConfig(): def __init__(self): # Config-parameters goes as attributes self.experiment_note = 'Changed some stuff' self.seed = random.randint(0, 80085) config = anyfig.setup_config(default_config='FooConfig') print(config) print(config.seed) At the moment, Anyfig supports inheritance, command line inputs, saving & loading and more ideas in the pipeline. Check the github for some more info or reach out to me.
The benefits might not be obvious at first glance so let me try to sell this.
- Defining config-parameters at runtime offers dynamic settings. Leverage the power of Python. Also cleans up the code
{"loss_fn": "l1loss"} # Lives inside a .json file config = ~parse_jsonfile~ if config.loss_fn = 'l1loss': loss_fn = torch.nn.L1Loss() elif config.loss_fn = 'mse' loss_fn = torch.nn.MSELoss() Skip the if else statements. You can do those kinds of operations directly in the config
@anyfig.config_class class Train(): def __init__(self): self.loss_fn = torch.nn.L1Loss() - Class inheritance avoids duplicated code. Good for biiig projects. How often have you started training with the wrong settings? Anyfig can help mitigate that problem.
A typical use case for Anyfig would be to have one config-class for training, one for laptop-debugging and one for prediction. Since many of the config-parameters are the same, you can choose one class as the parent class and have the other two inherit from the parent and overwrite selected config-parameters.
import anyfig @anyfig.config_class class Train(): def __init__(self): self.batch_size = 32 self.seed = random.randint(0, 80085) @anyfig.config_class class DebugTrain(Train): def __init__(self): super().__init__() self.seed = 0 @anyfig.config_class class Predict(Train): def __init__(self): super().__init__() self.batch_size = 1 I’m currently looking for people who are willing to try this out / give feedback 🙂
submitted by /u/machinemask
[link] [comments]
[D] Paper Summary of ICCV 2019 Best paper awardee ‘SinGAN’
Vision and Language Group, a deep learning group at IIT Roorkee, has written a summary of the ICCV 2019 best paper awardee ‘SinGAN’ which can be found here:
https://github.com/vlgiitr/papers_we_read/blob/master/summaries/singan.md
Feedback on the same is appreciated and do star the repo if you found it useful.
submitted by /u/aniket_agarwal
[link] [comments]