Take Your Best Selfie Automatically, with Photobooth on Pixel 3
Taking a good group selfie can be tricky—you need to hover your finger above the shutter, keep everyone’s faces in the frame, look at the camera, make good expressions, try not to shake the camera and hope no one blinks when you finally press the shutter! After building the technology behind automatic photography with Google Clips, we asked ourselves: can we bring some of the magic of this automatic picture experience to the Pixel phone?
With Photobooth, a new shutter-free mode in the Pixel 3 Camera app, it’s now easier to shoot selfies—solo, couples, or even groups—that capture you at your best. Once you enter Photobooth mode and click the shutter button, it will automatically take a photo when the camera is steady and it sees that the subjects have good expressions with their eyes open. And in the newest release of Pixel Camera, we’ve added kiss detection to Photobooth! Kiss a loved one, and the camera will automatically capture it.
 |
| Photobooth automatically captures group shots, when everyone in the photo looks their best. |
Photobooth joins Top Shot and Portrait mode in a suite of exciting Pixel camera features that enable you to take the best pictures possible. However, unlike Portrait mode, which takes advantage of specialized hardware in the back-facing camera to provide its most accurate results, Photobooth is optimized for the front-facing camera. To build Photobooth, we had to solve for three challenges: how to identify good content for a wide range of user groups; how to time the shutter to capture the best moment; and how to animate a visual element that helps users understand what Photobooth sees and captures.
Models for Understanding Good Content
In developing Photobooth, a main challenge was to determine when there was good content in either a typical selfie, in which the subjects are all looking at the camera, or in a shot that includes people kissing and not necessarily facing the camera. To accomplish this, Photobooth relies on two distinct models to capture good selfies—a model for facial expressions and a model to detect when people kiss.
We worked with photographers to identify five key expressions that should trigger capture: smiles, tongue-out, kissy/duck face, puffy-cheeks, and surprise. We then trained a neural network to classify these expressions. The kiss detection model used by Photobooth is a variation of the Image Content Model (ICM) trained for Google Clips, fine tuned specifically to focus on kissing. Both of these models use MobileNets in order to run efficiently on-device while continuously processing the images at high frame rate. The outputs of the models are used to evaluate the quality of each frame for the shutter control algorithm.
Shutter Control
Once you click the shutter button in Photobooth mode, a basic quality assessment based on the content score from the models above is performed. This first stage is used as a filter that avoids moments that either contain closed eyes, talking, or motion blur, or fail to detect the facial expressions or kissing actions learned by the models. Photobooth temporally analyzes the expression confidence values to detect their presence in the photo, making it robust to variations in the output of machine learning (ML) models. Once the first stage is successfully passed, each frame is subjected to a more fine-grained analysis, which outputs an overall frame score.
The frame score considers both facial expression quality and the kiss score. As the kiss detection model operates on the entire frame, its output can be used directly as a full-frame score value for kissing. The face expressions model outputs a score for each identified expression. Since a variable number of faces may be present in each frame, Photobooth applies an attention model using the detected expressions to iteratively compute an expression quality representation and weight for each face. The weighting is important, for example, to emphasize the expressions in the foreground, rather than the background. The model then calculates a single, global score for the quality of expressions in the frame.
The final image quality score used for triggering the shutter is computed by a weighted combination of the attention based facial expression score and the kiss score. In order to detect the peak quality, the shutter control algorithm maintains a short buffer of observed frames and only saves a shot if its frame score is higher than the frames that come after it in the buffer. The length of the buffer is short enough to give users a sense of real time feedback.
Intelligence Indicator
Since Photobooth uses the front-facing camera, the user can see and interact with the display while taking a photo. Photobooth mode includes a visual indicator, a bar at the top of the screen that grows in size when photo quality scores increase, to help users understand what the ML algorithms see and capture. The length of the bar is divided into four distinct ranges: (1) no faces clearly seen, (2) faces seen but not paying attention to the camera, (3) faces paying attention but not making key expressions, and (4) faces paying attention with key expressions.
In order to make this indicator more interpretable, we forced the bar into these ranges, which prevented the bar scaling from being too rapid. This resulted in smooth variability of the bar length as the quality score changes and improved the utility. When the indicator bar reaches a length representative of a high quality score, the screen flashes to signify that a photo was captured and saved.
 |
| Using ML outputs directly as intelligence feedback results in rapid variation (left), whereas specifying explicit ranges creates a smooth signal (right). |
Conclusion
We’re excited by the possibilities of automatic photography on camera phones. As computer vision continues to improve, in the future we may generally trust smart cameras to select a great moment to capture. Photobooth is an example of how we can carve out a useful corner of this space—selfies and group selfies of smiles, funny faces, and kisses—and deliver a fun and useful experience.
Acknowledgments
Photobooth was a collaboration of several teams at Google. Key contributors to the project include: Kojo Acquah, Chris Breithaupt, Chun-Te Chu, Geoff Clark, Laura Culp, Aaron Donsbach, Relja Ivanovic, Pooja Jhunjhunwala, Xuhui Jia, Ting Liu, Arjun Narayanan, Eric Penner, Arushan Raj, Divya Tyam, Raviteja Vemulapalli, Julian Walker, Jun Xie, Li Zhang, Andrey Zhmoginov, Yukun Zhu.




 Sally Revell is a Principal Product Marketing Manager for AWS DeepLens. She loves to work on innovative products that have the potential to impact people’s lives in a positive way. In her spare time, she loves to do yoga, horseback riding and being outdoors in the beauty of the Pacific Northwest.
Sally Revell is a Principal Product Marketing Manager for AWS DeepLens. She loves to work on innovative products that have the potential to impact people’s lives in a positive way. In her spare time, she loves to do yoga, horseback riding and being outdoors in the beauty of the Pacific Northwest.

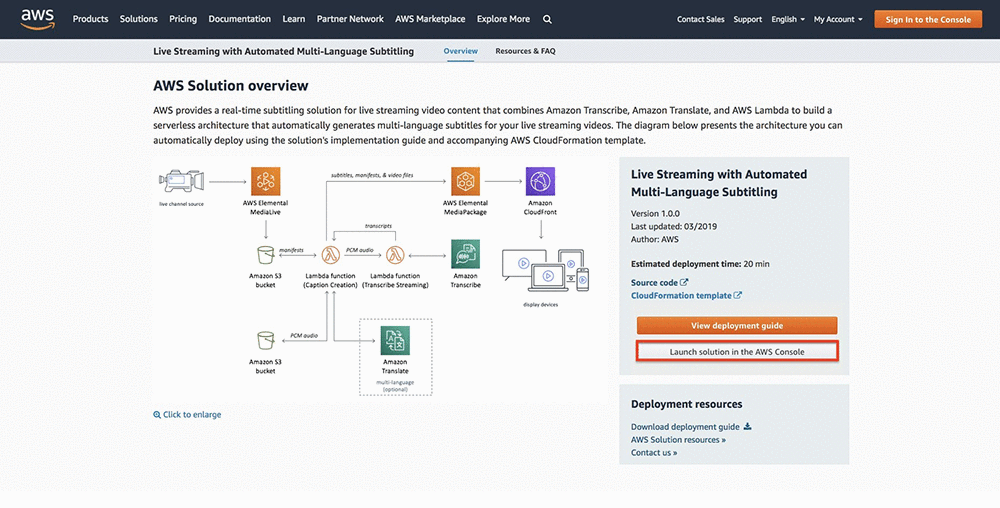


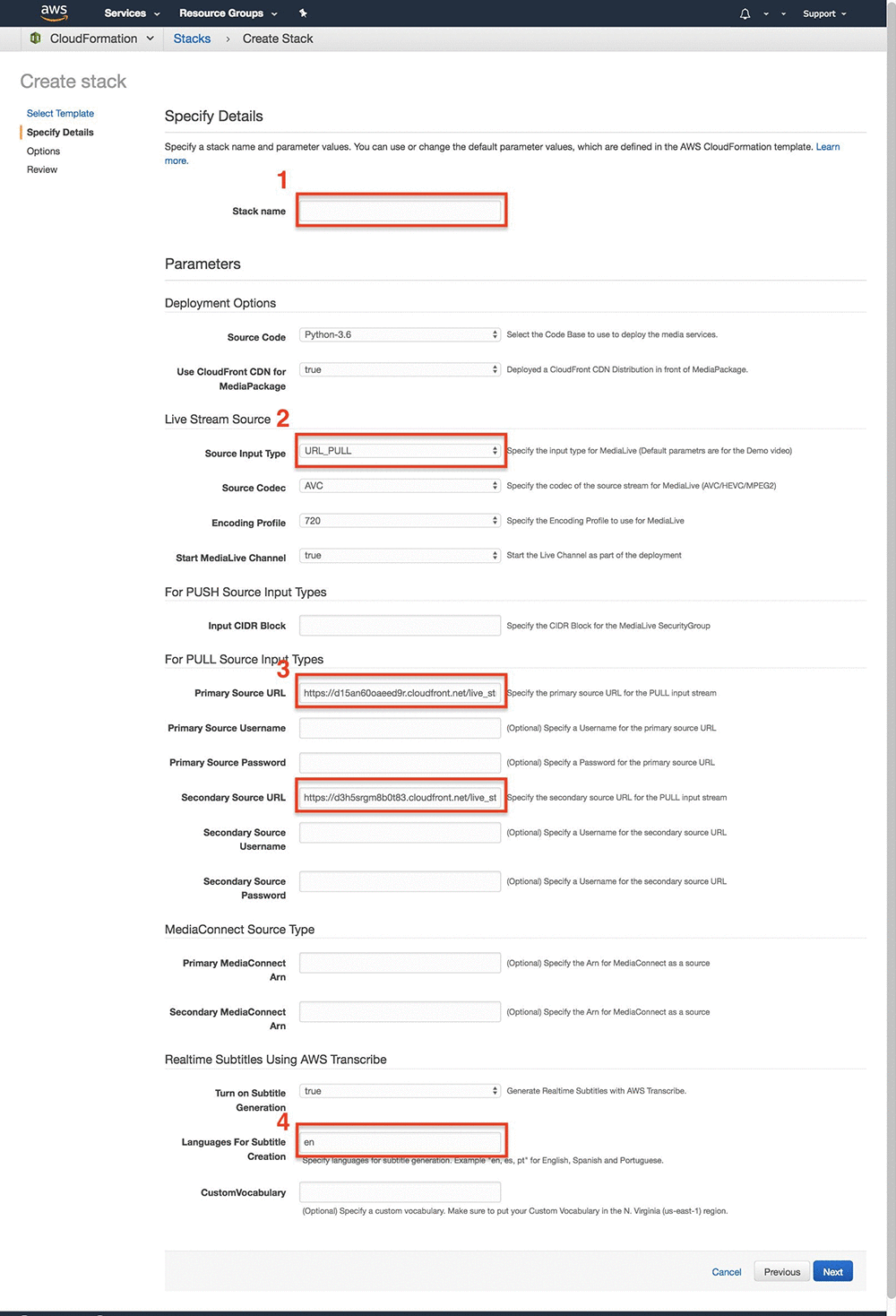

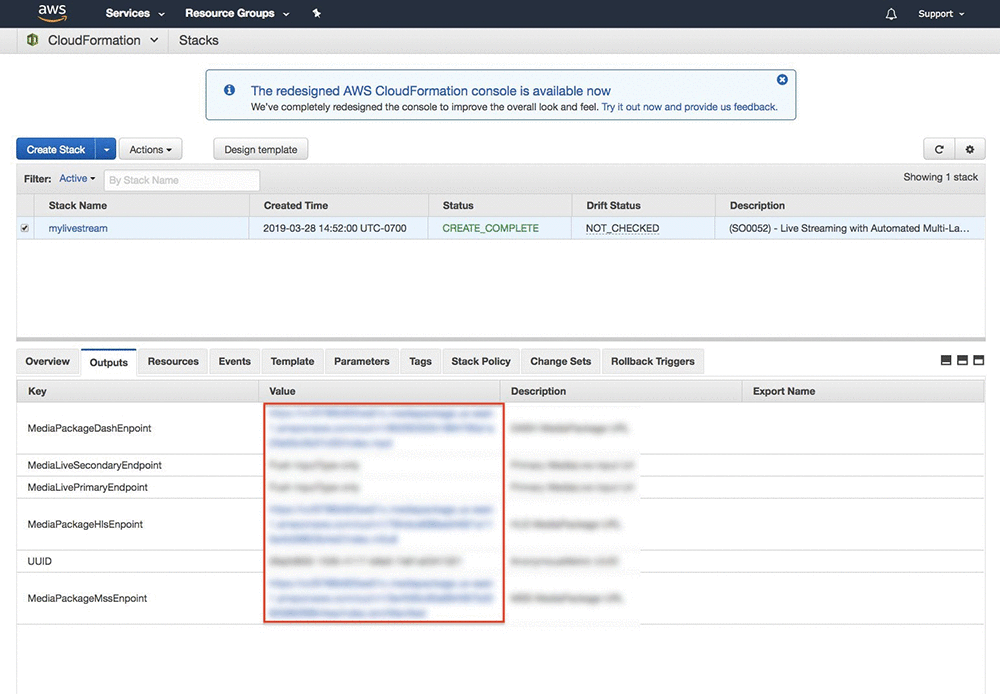

 Eddie Goynes is a Technical Marketing Engineer for AWS Elemental. He is an AWS Cloud and Live Video Streaming technical expert.
Eddie Goynes is a Technical Marketing Engineer for AWS Elemental. He is an AWS Cloud and Live Video Streaming technical expert.