Using Global Localization to Improve Navigation
One of the consistent challenges when navigating with Google Maps is figuring out the right direction to go: sure, the app tells you to go north – but many times you’re left wondering, “Where exactly am I, and which way is north?” Over the years, we’ve attempted to improve the accuracy of the blue dot with tools like GPS and compass, but found that both have physical limitations that make solving this challenge difficult, especially in urban environments.
We’re experimenting with a way to solve this problem using a technique we call global localization, which combines Visual Positioning Service (VPS), Street View, and machine learning to more accurately identify position and orientation. Using the smartphone camera as a sensor, this technology enables a more powerful and intuitive way to help people quickly determine which way to go.
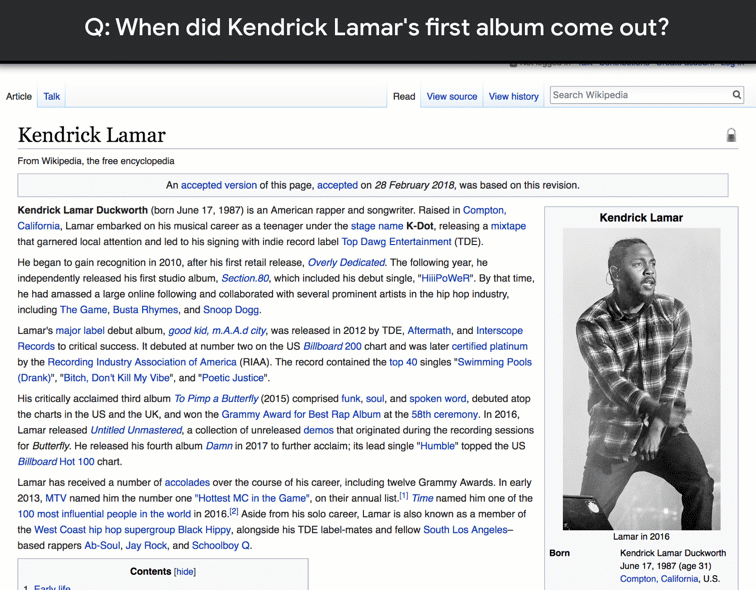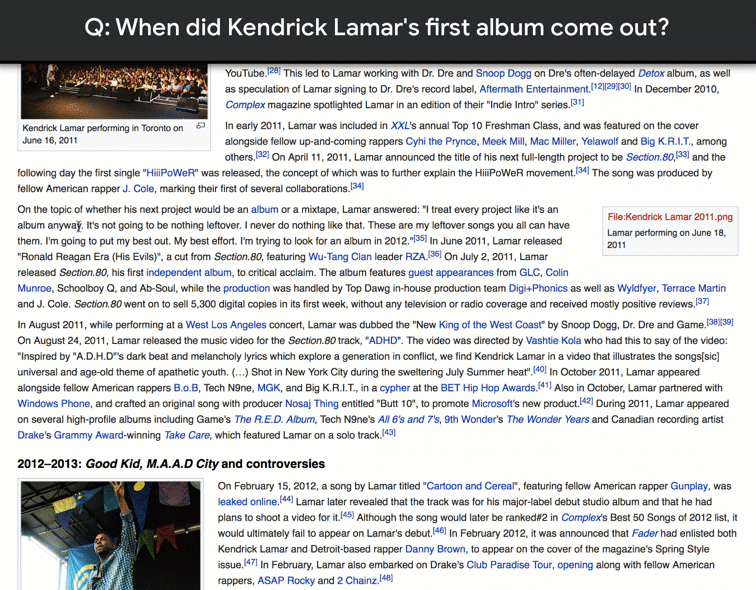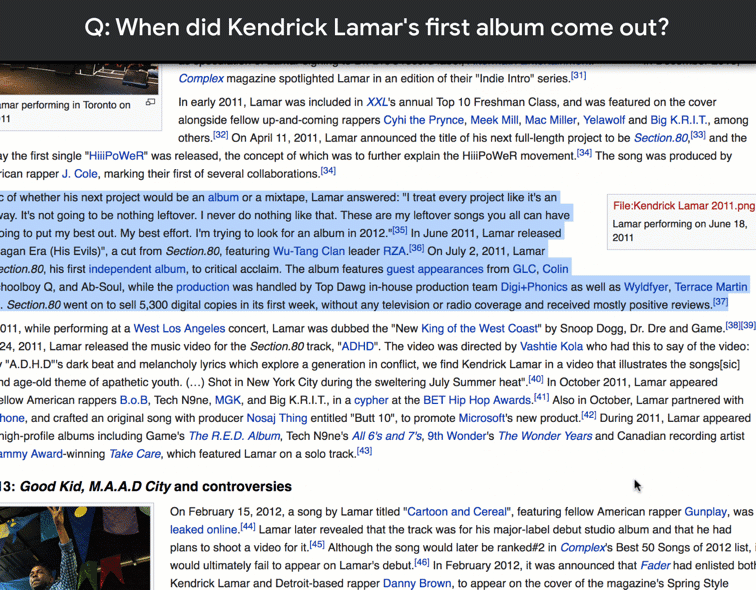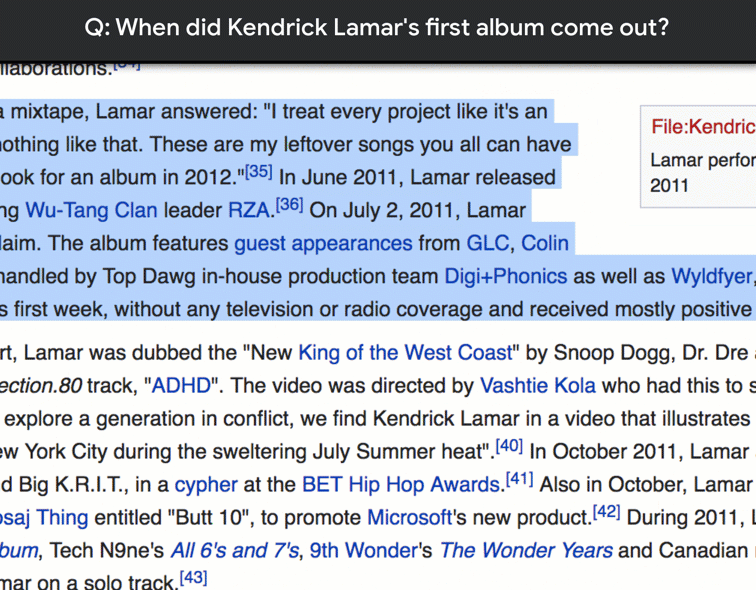
 |
| Due to limitations with accuracy and orientation, guidance via GPS alone is limited in urban environments. Using VPS, Street View and machine learning, Global Localization can provide better context on where you are relative to where you’re going. |
In this post, we’ll discuss some of the limitations of navigation in urban environments and how global localization can help overcome them.
Where GPS Falls Short
The process of identifying the position and orientation of a device relative to some reference point is referred to as localization. Various techniques approach localization in different ways. GPS relies on measuring the delay of radio signals from multiple dedicated satellites to determine a precise location. However, in dense urban environments like New York or San Francisco, it can be incredibly hard to pinpoint a geographic location due to low visibility to the sky and signals reflecting off of buildings. This can result in highly inaccurate placements on the map, meaning that your location could appear on the wrong side of the street, or even a few blocks away.
 |
| GPS signals bouncing off facades in an urban environment. |
GPS has another technical shortcoming: it can only determine the location of the device, not the orientation. Sometimes, sensors in your mobile device can remedy the situation by measuring the magnetic and gravity field of the earth and the relative motion of the device in order to give rough estimates of your orientation. But these sensors are easily skewed by magnetic objects such as cars, pipes, buildings, and even electrical wires inside the phone, resulting in errors that can be inaccurate by up to 180 degrees.
A New Approach to Localization
To improve the precision position and orientation of the blue dot on the map, a new complementary technology is necessary. When walking down the street, you orient yourself by comparing what you see with what you expect to see. Global localization uses a combination of techniques that enable the camera on your mobile device to orient itself much as you would.
VPS determines the location of a device based on imagery rather than GPS signals. VPS first creates a map by taking a series of images which have a known location and analyzing them for key visual features, such as the outline of buildings or bridges, to create a large scale and fast searchable index of those visual features. To localize the device, VPS compares the features in imagery from the phone to those in the VPS index. However, the accuracy of localization through VPS is greatly affected by the quality of the both the imagery and the location associated with it. And that poses another question—where does one find an extensive source of high-quality global imagery?
Enter Street View
Over 10 years ago we launched Street View in Google Maps in order to help people explore the world more deeply. In that time, Street View has continued to expand its coverage of the world, empowering people to not only preview their route, but also step inside famous landmarks and museums, no matter where they are. To deliver global localization with VPS, we connected it with Street View data, making use of information gathered and tested from over 93 countries across the globe. This rich dataset provides trillions of strong reference points to apply triangulation, helping more accurately determine the position of a device and guide people towards their destination.
 |
| Features matched from multiple images. |
Although this approach works well in theory, making it work well in practice is a challenge. The problem is that the imagery from the phone at the time of localization may differ from what the scene looked like when the Street View imagery was collected, perhaps months earlier. For example, trees have lots of rich detail, but change as the seasons change and even as the wind blows. To get a good match, we need to filter out temporary parts of the scene and focus on permanent structure that doesn’t change over time. That’s why a core ingredient in this new approach is applying machine learning to automatically decide which features to pay attention to, prioritizing features that are likely to be permanent parts of the scene and ignoring things like trees, dynamic light movement, and construction that are likely transient. This is just one of the many ways in which we use machine learning to improve accuracy.
Combining Global Localization with Augmented Reality
Global localization is an additional option that users can enable when they most need accuracy. And, this increased precision has enabled the possibility of a number of new experiences. One of the newest features we’re testing is the ability to use ARCore, Google’s platform for building augmented reality experiences, to overlay directions right on top of Google Maps when someone is in walking navigation mode. With this feature, a quick glance at your phone shows you exactly which direction you need to go.

Although early results are promising, there’s significant work to be done. One outstanding challenge is making this technology work everywhere, in all types of conditions—think late at night, in a snowstorm, or in torrential downpour. To make sure we’re building something that’s truly useful, we’re starting to test this feature with select Local Guides, a small group of Google Maps enthusiasts around the world who we know will offer us the feedback about how this approach can be most helpful.
Like other AI-driven camera experiences such as Google Lens (which uses the camera to let you search what you see), we believe the ability to overlay directions over the real world environment offers an exciting and useful way to use the technology that already exists in your pocket. We look forward to continuing to develop this technology, and the potential for smartphone cameras to add new types of valuable experiences.