[N] In the U.K., AI will soon be used to tackle homelessness
According this article, AI and machine learning could help organisations to identify who needs to be safe urgently. Thoughts?
submitted by /u/Yrgalnumer1
[link] [comments]
According this article, AI and machine learning could help organisations to identify who needs to be safe urgently. Thoughts?
submitted by /u/Yrgalnumer1
[link] [comments]
In the Neural Architecture Search paper it is stated that the controller RNN (used to generate architectures) had only 35 units in each of its 2 layers. This very small size seems strange to me. My initial explanation was that the authors had too few samples, but they actually used 15,000, which should be enough to train a bigger network. So what in your opinion could be a reason for a smaller network/why making the controller bigger wouldn’t influence the results?
submitted by /u/LuxuriousLime
[link] [comments]
Hi all,
I was studying the XGBoost paper a couple of weeks ago and I took quite some notes. These notes are not the basic kind but involve step by step derivation of the mathematical functions. I could not find a complete and this detailed study of the paper so I wanted to share. Please comment below if you see any mistake. Any feedback or comment is welcome.
Link: https://drive.google.com/file/d/15l9oAlavzG8MYA7oCUAUfqdCjen6jSdg/view?usp=sharing
submitted by /u/_kty
[link] [comments]
HuggingFace has just released Transformers 2.0, a library for Natural Language Processing in TensorFlow 2.0 and PyTorch which provides state-of-the-art pretrained models in most recent NLP architectures (BERT, GPT-2, XLNet, RoBERTa, DistilBert, XLM…) comprising several multi-lingual models.
An interesting feature is that the library provides deep interoperability between TensorFlow 2.0 and PyTorch.
You can move a full model seamlessly from one framework to the other during its lifetime (instead of just exporting a static computation graph at the end like with ONNX). This way it’s possible to get the best of both worlds by selecting the best framework for each step of training, evaluation, production, e.g. train on TPUs before finetuning/testing in PyTorch and finally deploy with TF-X.
An example in the readme shows how Bert can be finetuned on GLUE in a few lines of code with the high-level API tf.keras.Model.fit() and then loaded in PyTorch for quick and easy inspection and debugging.
As TensorFlow and PyTorch as getting closer, this kind of deep interoperability between both frameworks could become a new norm for multi-backends libraries.
submitted by /u/Thomjazz
[link] [comments]
Leading into TwitchCon — the world’s top gathering of livestreamers — we’re announcing the RTX Broadcast Engine, a new set of RTX-accelerated software development kits that use the AI capabilities of GeForce RTX GPUs to transform livestreams.
Powered by dedicated AI processors called Tensor Cores on RTX GPUs, the new SDKs enable virtual greenscreens, style filters and augmented reality effects — the kind of techniques used by major broadcast networks — all using AI and without the need for special equipment.
Livestreaming of video games has become a cultural phenomenon. Over 750 million people around the world tune in to watch people play video games. TwitchCon is where this global movement comes together. More than 50,000 streamers and fans will converge in San Diego this weekend to meet their favorite gamers and learn about the future of livestreaming.
NVIDIA GPUs are already the most popular choice to power the PC games played by streamers. They’re also used to encode and stream video to platforms such as Twitch, YouTube, Mixer, Huya and Douyu.
With the RTX Broadcast Engine’s AI-powered capabilities, NVIDIA is announcing a new way that RTX GPUs can enable more immersive livestreams — all without special cameras or physical props.
The new SDKs include:
In addition, we’re working with OBS, one of the leading livestreaming applications, to integrate RTX Greenscreen. With it, livestreamers will be able to remove their background environment or instantly teleport themselves anywhere — in this world or in virtual ones. This feature will be showcased at TwitchCon for the first time and available in the coming months.
“NVIDIA has been at the top of my list when it comes to streaming and recording equipment. I’m continually impressed with what they’re doing,” said Hugh Bailey, author, OBS. “And their technology is impressive with RTX features like RTX Greenscreen.”
The RTX Broadcast Engine will enable streaming applications throughout the ecosystem to create immersive tools and effects for broadcasters to engage audiences and drive viewership.
“The new RTX Broadcast Engine is an exciting advancement that will allow developers in our app store to create powerful new tools for streamers with NVIDIA RTX GPUs,” said Ali Moiz, CEO of Streamlabs. “We’re thrilled to continue working with NVIDIA as they introduce new features to the Streamlabs developer community, and look forward to implementing this new technology.”
“We have collaborated with NVIDIA over the years on many projects and the introduction of the NVIDIA RTX Broadcast Engine is by far the most exciting,” said Miguel Molina, director of developer relations at XSplit. “For the XSplit team, we are excited to integrate these new tools into our suite of apps, enabling our users to create better content by maximizing the potential of NVIDIA GeForce RTX.”
In addition to RTX Broadcast Engine, leading applications such as OBS, XSplit, Huya, Douya and Streamlabs have deployed the NVIDIA Video Codec SDK for fast, high-quality streaming. Three new integrations made their debut this month:
Developers can learn more about the RTX Broadcast Engine and apply for early access at developer.nvidia.com/broadcastengine. Or stop by the OBS booth at TwitchCon, booth 1823, where we’ll be showing off RTX Greenscreen in OBS, new RTX Studio laptops and upcoming RTX games.
The post A Stream Come True: NVIDIA RTX Broadcast Engine Brings Twitch Livestreams to Life with AI appeared first on The Official NVIDIA Blog.
I just stumbled upon a paper https://openreview.net/forum?id=HylxE1HKwS / https://arxiv.org/abs/1908.09791 with quite an interesting idea of training a single deep network that can be deployed at many efficiency configurations. But, what’s more “interesting” is the amount of self-citations in the paper. Seven of the cited publications had the third author’s name (which I assume is the PI). I feel that it is excessive. Correct me if I’m wrong. And the fact that this paper is heavily self-citing but isn’t acknowledging existing research that pursued similar direction (e.g., AuxNet, BranchyNet, IDK Cascades, Stochastic Downsampling, Anytime Neural Networks) is worrying.
What do you think of the self-citation trend (if there’s any at all) in machine learning research?
submitted by /u/TreeNetworks
[link] [comments]
Hi everyone!
I am wondering what people think of an idea, which I’m looking at turning into reality: A community centred Machine Learning platform!
Ideas:
Main page: Similar to Reddit where people can post their projects, research, questions and requests.
Projects: People can form long term groups to share code bases, road maps, problems and tasks. Projects might be centred around a research area, a project at work (companies can work together), or something you are making for fun. People can request to be part of projects, so if you spot something you want to be involved in you can join, and if you need help you can ask people to join.
Modules: People can upload Docker containers, these will have a standard API, anyone one can run these. Modules might be an algorithm, model or a utility tool. These can be attatched to projects, and you can browse a library of modules sorted in categories (BioInformatics, Computer Vision, NLP etc) . You can optionally charge for the use of modules you make?
The main goal is to create a collaborative environment, so companies, researchers, and anyone! can show off what they are doing and share ideas, problems and work on projects together.
Questions:
Is this reinventing the wheel, is Kaggle + Reddit + Github etc good enough?
If you made a dream ML social platform, what would you add?
Thanks 🙂
From Tom
submitted by /u/zonkosoft
[link] [comments]
In this post, we share some recent promising results regarding the applications
of Deep Learning in analog IC design. While this work targets a specific
application, the proposed methods can be used in other black box optimization
problems where the environment lacks a cheap/fast evaluation procedure.
<!–
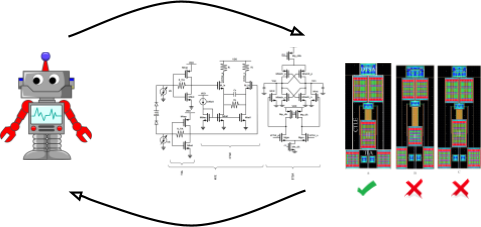
–>

So let’s break down how the analog IC design process is usually done, and then
how we incorporated deep learning to ease the flow.
Hi there,
I’m quite newbie in Machine Learning area. I learnt machine learning 10 years ago, it’s so hard. I just moved my company data warehouse to BigQuery and got some promotion related BigQuery ML. It’s look really easy to build model, training, and evaluation.
What’s the difference between BigQuery ML and other ML out there?
submitted by /u/eeldwin
[link] [comments]