How to evaluate ML models using confusion matrix?
Model Evaluation using Confusion Matrix
Model evaluation is a very important aspect of data science. Evaluation of a Data Science Model provides more colour to our hypothesis and helps evaluate different models that would provide better results against our data.
What Big-O is to coding, validation and evaluation is to Data Science Models.

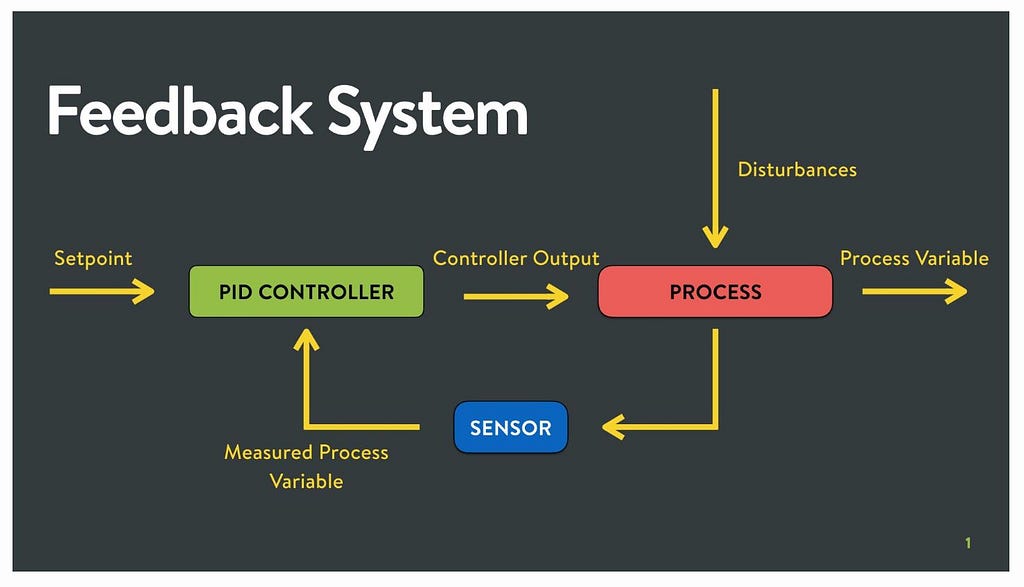
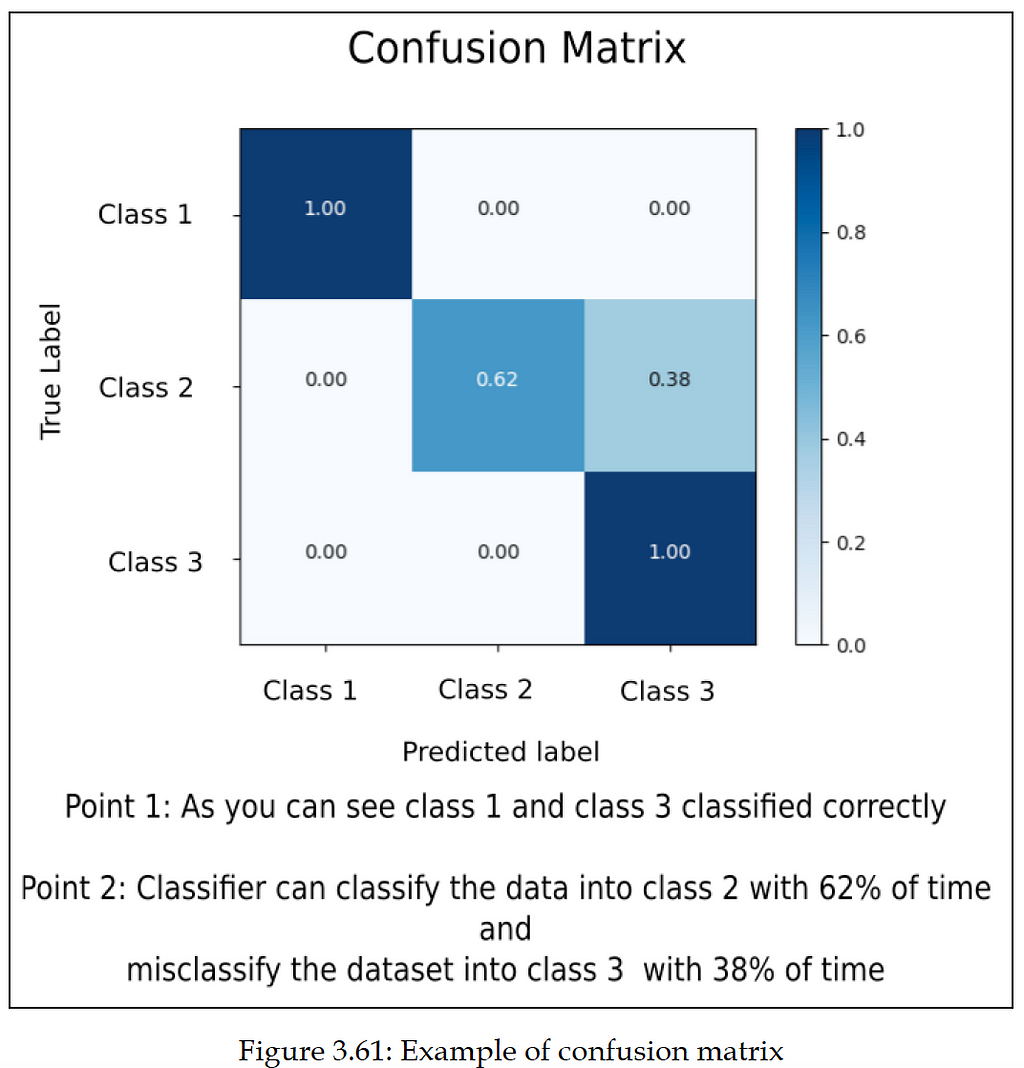
When we are implementing a multi-class classifier, we have multiple classes and the number of data entries belonging to all these classes is different. During testing, we need to know whether the classifier performs equally well for all the classes or whether there is bias towards some classes. This analysis can be done using the confusion matrix. It will have a count of how many data entries are correctly classified and how many are misclassified.
Let’s take an example. There is a total of ten data entries that belong to a class, and the label for that class is “Class 1”. When we generate the prediction from our ML model, we will check how many data entries out of the ten entries get the predicted label as “Class 1”. Suppose six data entries are correctly classified and get the label “Class 1”. In this case, for six entries, the predicted label and True(actual) label is the same, so the accuracy is 60%. For the remaining data entries (4 entries), the ML model misclassifies them. The ML model predicts class labels other than “Class 1”. From the preceding example, it is visible that the confusion matrix gives us an idea about how many data entries are classified correctly and how many are misclassified. We can explore the class-wise accuracy of the classifier.
For more learning on similar topics, the ML solutions book provides good explanations.
For more such answers to important Data Science concepts, please visit Acing AI.
Subscribe to our Acing AI newsletter, I promise not to spam and its FREE!
Thanks for reading! 😊 If you enjoyed it, test how many times can you hit 👏 in 5 seconds. It’s great cardio for your fingers AND will help other people see the story.
How to evaluate ML models using confusion matrix? was originally published in Acing AI on Medium, where people are continuing the conversation by highlighting and responding to this story.