Machine Learning: Living in the Age of AI
The post Machine Learning: Living in the Age of AI appeared first on The AI Blog.
The post Machine Learning: Living in the Age of AI appeared first on The AI Blog.
The post Harnessing the power of AI to transform healthcare appeared first on The AI Blog.
Reinforcement learning (RL) is a framework that lets agents learn decision making from experience. One of the many variants of RL is off-policy RL, where an agent is trained using a combination of data collected by other agents (off-policy data) and data it collects itself to learn generalizable skills like robotic walking and grasping. In contrast, fully off-policy RL is a variant in which an agent learns entirely from older data, which is appealing because it enables model iteration without requiring a physical robot. With fully off-policy RL, one can train several models on the same fixed dataset collected by previous agents, then select the best one. However, fully off-policy RL comes with a catch: while training can occur without a real robot, evaluation of the models cannot. Furthermore, ground-truth evaluation with a physical robot is too inefficient to test promising approaches that require evaluating a large number of models, such as automated architecture search with AutoML.
This challenge motivates off-policy evaluation (OPE), techniques for studying the quality of new agents using data from other agents. With rankings from OPE, we can selectively test only the most promising models on real-world robots, significantly scaling experimentation with the same fixed real robot budget.
 |
| A diagram for real-world model development. Assuming we can evaluate 10 models per day, without off-policy evaluation, we would need 100x as many days to evaluate our models. |
Though the OPE framework shows promise, it assumes one has an off-policy evaluation method that accurately ranks performance from old data. However, agents that collected past experience may act very differently from newer learned agents, which makes it hard to get good estimates of performance.
In “Off-Policy Evaluation via Off-Policy Classification”, we propose a new off-policy evaluation method, called off-policy classification (OPC), that evaluates the performance of agents from past data by treating evaluation as a classification problem, in which actions are labeled as either potentially leading to success or guaranteed to result in failure. Our method works for image (camera) inputs, and doesn’t require reweighting data with importance sampling or using accurate models of the target environment, two approaches commonly used in prior work. We show that OPC scales to larger tasks, including a vision-based robotic grasping task in the real world.
How OPC Works
OPC relies on two assumptions: 1) that the final task has deterministic dynamics, i.e. no randomness is involved in how states change, and 2) that the agent either succeeds or fails at the end of each trial. This second “success or failure” assumption is natural for many tasks, such as picking up an object, solving a maze, winning a game, and so on. Because each trial will either succeed or fail in a deterministic way, we can assign binary classification labels to each action. We say an action is effective if it could lead to success, and is catastrophic if it is guaranteed to lead to failure.
OPC utilizes a Q-function, learned with a Q-learning algorithm, that estimates the future total reward if the agent chooses to take some action from its current state. The agent will then choose the action with the largest total reward estimate. In our paper, we prove that the performance of an agent is measured by how often its chosen action is an effective action, which depends on how well the Q-function correctly classifies actions as effective vs. catastrophic. This classification accuracy acts as an off-policy evaluation score.
However, the labeling of data from previous trials is only partial. For example, if a previous trial was a failure, we do not get negative labels because we do not know which action was the catastrophic one. To overcome this, we leverage techniques from semi-supervised learning, positive-unlabeled learning in particular, to get an estimate of classification accuracy from partially labeled data. This accuracy is the OPC score.
Off-Policy Evaluation for Sim-to-Real Learning
In robotics, it’s common to use simulated data and transfer learning techniques to reduce the sample complexity of learning robotics skills. This can be very useful, but tuning these sim-to-real techniques for real-world robotics is challenging. Much like off-policy RL, training doesn’t use the real robot, because it is trained in simulation, but evaluation of that policy still needs to use a real robot. Here, off-policy evaluation can come to the rescue again—we can take a policy trained only in simulation, then evaluate it using previous real-world data to measure its transfer to the real robot. We examine OPC across both fully off-policy RL and sim-to-real RL.
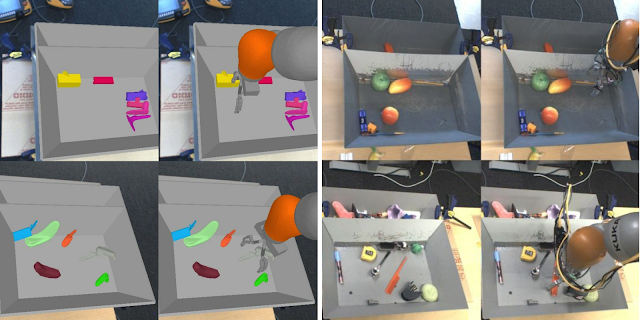 |
| An example of how simulated experience can differ from real-world experience. Here, simulated images (left) have much less visual complexity than real-world images (right). |
Results
First, we set up a simulated version of our robot grasping task, where we could easily train and evaluate several models to benchmark off-policy evaluation. These models were trained with fully off-policy RL, then evaluated with off-policy evaluation. We found that in our robotics tasks, a variant of the OPC called the SoftOPC performed best at predicting final success rate.
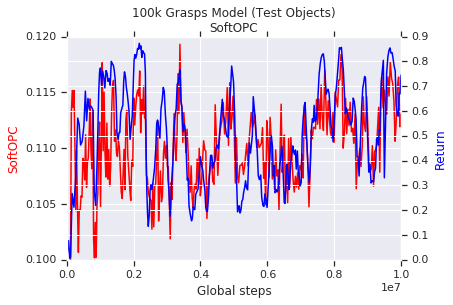 |
| An experiment in the simulated grasping task. The red curve is the dimensionless SoftOPC score over the course of training, evaluated from old data. The blue curve is the grasp success rate in simulation. We see the SoftOPC on old data correlates well with grasp success of the model within our simulator. |
After success in sim, we then tried SoftOPC in the real-world task. We took 15 models, trained to have varying degrees of robustness to the gap between simulation and reality. Of these models, 7 of them were trained purely in simulation, and the rest were trained on mixes of simulated and real-world data. For each model, we evaluated the SoftOPC on off-policy real-world data, then the real-world grasp success, to see how well SoftOPC predicted performance of that model. We found that on real data, the SoftOPC does produce scores that correlate with true grasp success, letting us rank sim-to-real techniques using past real experience.
 |
| SoftOPC score and true performance for 3 different sim-to-real methods: a baseline simulation, a simulation with random textures and lighting, and a model trained with RCAN. All three models are trained with no real data, then evaluated with off-policy evaluation on a validation set of real data. The ordering of the SoftOPC score matches the order of real grasp success. |
Below is a scatterplot of the full results from all 15 models. Each point represents the off-policy evaluation score and real-world grasp success of each model. We compare different scoring functions by their correlation to final grasp success. The SoftOPC does not correlate perfectly with true grasp success, but its scores are significantly more reliable than baseline approaches like the temporal-difference error (the standard Q-learning loss).
 |
| Results from our sim-to-real evaluation experiment. On the left is a baseline, the temporal difference error of the model. On the right is one of our proposed methods, the SoftOPC. The shaded region is a 95% confidence interval. The correlation is significantly better with SoftOPC. |
Future Work
One promising direction for future work is to see if we can relax our assumptions about the task, to support tasks where dynamics are more noisy, or where we get partial credit for almost succeeding. However, even with our included assumptions, we think the results are promising enough to be applied to many real-world RL problems.
Acknowledgements
This research was conducted by Alex Irpan, Kanishka Rao, Konstantinos Bousmalis, Chris Harris, Julian Ibarz and Sergey Levine. We’d like to thank Razvan Pascanu, Dale Schuurmans, George Tucker and Paul Wohlhart for valuable discussions. A preprint is available on arXiv.

Virtually every federal agency is focused on understanding how AI will affect society, from better protecting data to improving public services, lowering costs and providing better quality of life for consumers.
Leaders in the federal government and private sector pushing these initiatives forward will come together later this year at the GPU Technology Conference in Washington, hosted by NVIDIA and its partners, including Booz Allen Hamilton, Dell, IBM, Lockheed Martin and other important AI technology providers.
More than 3,000 attendees — made up of developers, researchers, policymakers and CIOs — will be there to discuss the latest developments in deep learning, machine learning, cybersecurity, autonomous machines, HPC, intelligent video analytics, healthcare, 5G, VR and more.
Registration is now open for the conference and training sessions, which will run from Nov. 4-6 at the Reagan Center.
Over 700 companies and organizations will participate in the event, from the nation’s top technology firms to government contractors and national labs — such as Alphabet, Amazon Web Services, Booz Allen Hamilton, Carnegie Mellon University, Dell EMC, the Department of Energy, IBM, Lockheed Martin, Microsoft and Oak Ridge National Laboratory.
GTC DC, now in its fourth year, will feature more than 100 sessions and panels on topics such as AI applications for humanitarian disaster relief, supply chain management, fraud prevention and 5G technology.
Tuesday morning kicks off with a keynote by Ian Buck, NVIDIA’s vice president of accelerated computing. Dozens more experts across a wide range of fields will be presenting, with talks from NetApp, Pure Storage, Carahsoft Technology Corp., Kinetica, Government Acquisitions, Inc. and others. Confirmed speakers include:
A series of policy discussions will take place Nov. 5 with leaders from a variety of agencies and government contractors. The panel discussions will focus on America’s national AI strategy, cybersecurity and workforce training.
Attendees can register for dozens of hands-on training sessions held throughout the conference. Six NVIDIA Deep Learning Institute full-day workshops will be offered on Nov. 4 — from Fundamentals of Accelerated Computing with CUDA Python to industry-specific deep learning trainings for industrial inspection, robotics, intelligent video analytics, and healthcare image analysis. Register early to reserve your seat.
We will also host our third Women in AI breakfast in DC this year. The event, which covers relevant and timely topics in AI, features women speakers across industry and research fields.
More than 50 companies will exhibit their latest technology in the Expo Hall, during show hours on Nov. 5 and 6. Evening receptions will offer networking opportunities for attendees.
Developers and thought leaders are invited to submit talks and research posters for the event. For registration and additional conference details, check out the GTC DC website.
The post GTC DC, Washington’s Premier AI Conference, Returns Nov. 4-6 with 3,000+ Attendees appeared first on The Official NVIDIA Blog.
The AWS DeepRacer League is the world’s first global autonomous racing league, open to anyone. Developers of all skill levels can compete in person at 22 AWS events globally, or online via the AWS DeepRacer console, for a chance to win an expense paid trip to re:Invent 2019, where they will race to win the Championship Cup 2019.
On May 30th, the AWS DeepRacer league visited the AWS Summit in Chicago, which was the 11th live race of the 2019 season. The top three there were as enthusiastic as ever and eager to put their models to the test on the track.
The Chicago race was extremely close to seeing all of the top three participants break the 10-second barrier. Scott from A Cloud Guru at the topped the board with 9.35 seconds, closely followed by RoboCalvin at 10.23 seconds and szecsei with 10.79 seconds.
Before Chicago, the winner Scott from A cloud guru had competed in the very first race in Santa Clara and was knocked from the top spot in the last hour of racing! There he ended up 4th, with a time of 11.75 seconds. He tried again in Atlanta, but couldn’t do better than 8th recording a time of 12.69 seconds. It was third time lucky for him in Chicago, where he was finally crowned champion and scored his winning ticket to the Championship Cup at re:Invent 2019!

Winners from Chicago RoboCalvin (2nd – 10.2 seconds), Scott (winner – 9.35 seconds), Szecsei (3rd – 10.7 seconds).
On June 4th, the AWS DeepRacer League moved to the next race in Las Vegas, Nevada, where the inaugural re:MARS conference took place. Re:MARS is a new global AI event focused on Machine Learning, Automation, Robotics, and Space.
Over 2.5 days, AI enthusiasts visited the DeepRacer track to compete for the top prize. It was a competitive race; the world record was broken twice (the previous record was set in Seoul in April and was 7.998 seconds). John (who eventually came second), was first to break it and was in the lead with a time of 7.84 seconds for most of the afternoon before astronav (Anthony Navarro) knocked him off the top spot in the final few minutes of racing, with a winning time of 7.62 seconds. Competition was strong, and developers returned to the tracks multiple times after iterating on their model. Although the times were competitive, they were all cheering for each other and even sharing strategies. It was the fastest race we have seen yet – the top 10 were all under 10 seconds!

The winners from re:MARS John (2nd – 7.84 seconds), Anthony (1st – 7.62 seconds), Gustav (3rd – 8.23 seconds).
Participants in the league vary in their ability and experience in machine learning. Re:MARS, not surprisingly brought some speedy times, but developers there were still able to learn something new and build on their existing skills. Similarly, our winner from Chicago had some background in the field, but our 3rd place winner had absolutely none. The league is open to all and can help you reach your machine learning goals. The pre-trained models provided at the track make it possible for you to enter the league without building a model, or you can create your own from scratch in one of the workshops held at the event. And new this week is the racing tips page, providing developers with the most up to date tools to improve lap times, tips from AWS experts, and opportunities to connect with the DeepRacer community. Check it out today and start sharing your DeepRacer story!

Machine learning developers, with some or no experience before entering the league.
The 2019 season is in the home stretch and during the week of June 10th, 3 more races are taking place. There will be a full round up on all the action next week, as we approach the last few chances on the summit circuit for developers to advance to the finals at re:Invent 2019. Start building today for your chance to win!
This week, Long Beach, CA hosts the 2019 Conference on Computer Vision and Pattern Recognition (CVPR 2019), the premier annual computer vision event comprising the main conference and several co-located workshops and tutorials. As a leader in computer vision research and a Platinum Sponsor, Google will have a strong presence at CVPR 2019—over 250 Googlers will be in attendance to present papers and invited talks at the conference, and to organize and participate in multiple workshops.
If you are attending CVPR this year, please stop by our booth and chat with our researchers who are actively pursuing the next generation of intelligent systems that utilize the latest machine learning techniques applied to various areas of machine perception. Our researchers will also be available to talk about and demo several recent efforts, including the technology behind predicting pedestrian motion, the Open Images V5 dataset and much more.
You can learn more about our research being presented at CVPR 2019 in the list below (Google affiliations highlighted in blue)
Area Chairs include:
Jonathan T. Barron, William T. Freeman, Ce Liu, Michael Ryoo, Noah Snavely
Oral Presentations
Relational Action Forecasting
Chen Sun, Abhinav Shrivastava, Carl Vondrick, Rahul Sukthankar, Kevin Murphy, Cordelia Schmid
Pushing the Boundaries of View Extrapolation With Multiplane Images
Pratul P. Srinivasan, Richard Tucker, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng, Noah Snavely
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Chenxi Liu, Liang-Chieh Chen, Florian Schroff, Hartwig Adam, Wei Hua, Alan L. Yuille, Li Fei-Fei
AutoAugment: Learning Augmentation Strategies From Data
Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, Quoc V. Le
DeepView: View Synthesis With Learned Gradient Descent
John Flynn, Michael Broxton, Paul Debevec, Matthew DuVall, Graham Fyffe, Ryan Overbeck, Noah Snavely, Richard Tucker
Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation
He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, Leonidas J. Guibas
Do Better ImageNet Models Transfer Better?
Simon Kornblith, Jonathon Shlens, Quoc V. Le
TextureNet: Consistent Local Parametrizations for Learning From High-Resolution Signals on Meshes
Jingwei Huang, Haotian Zhang, Li Yi, Thomas Funkhouser, Matthias Niessner, Leonidas J. Guibas
Diverse Generation for Multi-Agent Sports Games
Raymond A. Yeh, Alexander G. Schwing, Jonathan Huang, Kevin Murphy
Occupancy Networks: Learning 3D Reconstruction in Function Space
Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, Andreas Geiger
A General and Adaptive Robust Loss Function
Jonathan T. Barron
Learning the Depths of Moving People by Watching Frozen People
Zhengqi Li, Tali Dekel, Forrester Cole, Richard Tucker, Noah Snavely, Ce Liu, William T. Freeman
Composing Text and Image for Image Retrieval – an Empirical Odyssey
Nam Vo, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, James Hays
Learning to Synthesize Motion Blur
Tim Brooks, Jonathan T. Barron
Neural Rerendering in the Wild
Moustafa Meshry, Dan B. Goldman, Sameh Khamis, Hugues Hoppe, Rohit Pandey, Noah Snavely, Ricardo Martin-Brualla
Neural Illumination: Lighting Prediction for Indoor Environments
Shuran Song, Thomas Funkhouser
Unprocessing Images for Learned Raw Denoising
Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, Jonathan T. Barron
Posters
Co-Occurrent Features in Semantic Segmentation
Hang Zhang, Han Zhang, Chenguang Wang, Junyuan Xie
CrDoCo: Pixel-Level Domain Transfer With Cross-Domain Consistency
Yun-Chun Chen, Yen-Yu Lin, Ming-Hsuan Yang, Jia-Bin Huang
Im2Pencil: Controllable Pencil Illustration From Photographs
Yijun Li, Chen Fang, Aaron Hertzmann, Eli Shechtman, Ming-Hsuan Yang
Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis
Qi Mao, Hsin-Ying Lee, Hung-Yu Tseng, Siwei Ma, Ming-Hsuan Yang
Revisiting Self-Supervised Visual Representation Learning
Alexander Kolesnikov, Xiaohua Zhai, Lucas Beyer
Scene Graph Generation With External Knowledge and Image Reconstruction
Jiuxiang Gu, Handong Zhao, Zhe Lin, Sheng Li, Jianfei Cai, Mingyang Ling
Scene Memory Transformer for Embodied Agents in Long-Horizon Tasks
Kuan Fang, Alexander Toshev, Li Fei-Fei, Silvio Savarese
Spatially Variant Linear Representation Models for Joint Filtering
Jinshan Pan, Jiangxin Dong, Jimmy S. Ren, Liang Lin, Jinhui Tang, Ming-Hsuan Yang
Target-Aware Deep Tracking
Xin Li, Chao Ma, Baoyuan Wu, Zhenyu He, Ming-Hsuan Yang
Temporal Cycle-Consistency Learning
Debidatta Dwibedi, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, Andrew Zisserman
Depth-Aware Video Frame Interpolation
Wenbo Bao, Wei-Sheng Lai, Chao Ma, Xiaoyun Zhang, Zhiyong Gao, Ming-Hsuan Yang
MnasNet: Platform-Aware Neural Architecture Search for Mobile
Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, Quoc V. Le
A Compact Embedding for Facial Expression Similarity
Raviteja Vemulapalli, Aseem Agarwala
Contrastive Adaptation Network for Unsupervised Domain Adaptation
Guoliang Kang, Lu Jiang, Yi Yang, Alexander G. Hauptmann
DeepLight: Learning Illumination for Unconstrained Mobile Mixed Reality
Chloe LeGendre, Wan-Chun Ma, Graham Fyffe, John Flynn, Laurent Charbonnel, Jay Busch, Paul Debevec
Detect-To-Retrieve: Efficient Regional Aggregation for Image Search
Marvin Teichmann, Andre Araujo, Menglong Zhu, Jack Sim
Fast Object Class Labelling via Speech
Michael Gygli, Vittorio Ferrari
Learning Independent Object Motion From Unlabelled Stereoscopic Videos
Zhe Cao, Abhishek Kar, Christian Hane, Jitendra Malik
Peeking Into the Future: Predicting Future Person Activities and Locations in Videos
Junwei Liang, Lu Jiang, Juan Carlos Niebles, Alexander G. Hauptmann, Li Fei-Fei
SpotTune: Transfer Learning Through Adaptive Fine-Tuning
Yunhui Guo, Honghui Shi, Abhishek Kumar, Kristen Grauman, Tajana Rosing, Rogerio Feris
NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
Golnaz Ghiasi, Tsung-Yi Lin, Quoc V. Le
Class-Balanced Loss Based on Effective Number of Samples
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, Serge Belongie
FEELVOS: Fast End-To-End Embedding Learning for Video Object Segmentation
Paul Voigtlaender, Yuning Chai, Florian Schroff, Hartwig Adam, Bastian Leibe, Liang-Chieh Chen
Inserting Videos Into Videos
Donghoon Lee, Tomas Pfister, Ming-Hsuan Yang
Volumetric Capture of Humans With a Single RGBD Camera via Semi-Parametric Learning
Rohit Pandey, Anastasia Tkach, Shuoran Yang, Pavel Pidlypenskyi, Jonathan Taylor, Ricardo Martin-Brualla, Andrea Tagliasacchi, George Papandreou, Philip Davidson, Cem Keskin, Shahram Izadi, Sean Fanello
You Look Twice: GaterNet for Dynamic Filter Selection in CNNs
Zhourong Chen, Yang Li, Samy Bengio, Si Si
Interactive Full Image Segmentation by Considering All Regions Jointly
Eirikur Agustsson, Jasper R. R. Uijlings, Vittorio Ferrari
Large-Scale Interactive Object Segmentation With Human Annotators
Rodrigo Benenson, Stefan Popov, Vittorio Ferrari
Self-Supervised GANs via Auxiliary Rotation Loss
Ting Chen, Xiaohua Zhai, Marvin Ritter, Mario Lučić, Neil Houlsby
Sim-To-Real via Sim-To-Sim: Data-Efficient Robotic Grasping via Randomized-To-Canonical Adaptation Networks
Stephen James, Paul Wohlhart, Mrinal Kalakrishnan, Dmitry Kalashnikov, Alex Irpan, Julian Ibarz, Sergey Levine, Raia Hadsell, Konstantinos Bousmalis
Using Unknown Occluders to Recover Hidden Scenes
Adam B. Yedidia, Manel Baradad, Christos Thrampoulidis, William T. Freeman, Gregory W. Wornell
Workshops
Computer Vision for Global Challenges
Organizers include: Timnit Gebru, Ernest Mwebaze, John Quinn
Deep Vision 2019
Invited speakers include: Pierre Sermanet, Chris Bregler
Landmark Recognition
Organizers include: Andre Araujo, Bingyi Cao, Jack Sim, Tobias Weyand
Image Matching: Local Features and Beyond
Organizers include: Eduard Trulls
3D-WiDGET: Deep GEneraTive Models for 3D Understanding
Invited speakers include: Julien Valentin
Fine-Grained Visual Categorization
Organizers include: Christine Kaeser-Chen
Advisory panel includes: Hartwig Adam
Low-Power Image Recognition Challenge (LPIRC)
Organizers include: Aakanksha Chowdhery, Achille Brighton, Alec Go, Andrew Howard, Bo Chen, Jaeyoun Kim, Jeff Gilbert
New Trends in Image Restoration and Enhancement Workshop and Associated Challenges
Program chairs include: Vivek Kwatra, Peyman Milanfar, Sebastian Nowozin, George Toderici, Ming-Hsuan Yang
Spatio-temporal Action Recognition (AVA) @ ActivityNet Challenge
Organizers include: David Ross, Sourish Chaudhuri, Radhika Marvin, Arkadiusz Stopczynski, Joseph Roth, Caroline Pantofaru, Chen Sun, Cordelia Schmid
Third Workshop on Computer Vision for AR/VR
Organizers include: Sofien Bouaziz, Serge Belongie
DAVIS Challenge on Video Object Segmentation
Organizers include: Jordi Pont-Tuset, Alberto Montes
Efficient Deep Learning for Computer Vision
Invited speakers include: Andrew Howard
Fairness Accountability Transparency and Ethics in Computer Vision
Organizers include: Timnit Gebru, Margaret Mitchell
Precognition Seeing through the Future
Organizers include: Utsav Prabhu
Workshop and Challenge on Learned Image Compression
Organizers include: George Toderici, Michele Covell, Johannes Ballé, Eirikur Agustsson, Nick Johnston
When Blockchain Meets Computer Vision & AI
Invited speakers include: Chris Bregler
Applications of Computer Vision and Pattern Recognition to Media Forensics
Organizers include: Paul Natsev, Christoph Bregler
Tutorials
Towards Relightable Volumetric Performance Capture of Humans
Organizers include: Sean Fanello, Christoph Rhemann, Graham Fyffe, Jonathan Taylor, Sofien Bouaziz, Paul Debevec, Shahram Izadi
Learning Representations via Graph-structured Networks
Organizers include: Ming-Hsuan Yang
Computer vision technology that can identify items in a shopping bag. Deep learning tools that inspect train tracks for defects. An AI model that automatically labels street-view imagery.
These are just a few of the AI breakthroughs being showcased this week by the dozens of NVIDIA Inception startups at the annual Computer Vision and Pattern Recognition conference, one of the world’s top AI research events.
The NVIDIA Inception virtual accelerator program supports startups harnessing GPUs for AI and data science applications. Since its launch in 2016, the program has expanded over tenfold in size, to over 4,000 companies. More than 50 of them can be found in the CVPR expo hall — exhibiting GPU-powered work spanning retail, robotics, healthcare and beyond.
From self-serve weighing stations that automatically identify fresh produce items in a plastic shopping bag, to smart vending machines that can recognize when a shopper takes a beverage out of a cooler — product recognition AI developed by Malong Technologies is enabling frictionless shopping experiences.
Malong’s computer vision solutions are transforming traditional retail equipment into smarter devices, enabling machines to see the products within them to improve operational efficiency, security and the customer experience.
Using the NVIDIA Metropolis platform for smart cities, the company is building product recognition AI models that enable highly accurate, real-time decisions at the edge. Malong develops powerful, scalable intelligent video analytics tools that can accurately recognize hundreds of thousands of retail products in real time. The company researches weakly-supervised learning to significantly reduce the effort to retrain their models as product packaging and store environments change.
Malong was able to speed its inferencing by more than 40x compared to CPU when using DeepStream and TensorRT software libraries on the NVIDIA T4 GPU. The company uses NVIDIA V100 GPUs in the cloud for training, and the Jetson TX2 supercomputer on a module to bring true AI computing at the edge.
At CVPR, the company is at booth 1316 on the show floor and is presenting research that achieves a new gold standard for image retrieval, outperforming prior methods by a significant margin. Malong is also co-hosting the Fine-Grained Visual Categorization Workshop and organized the first ever retail product recognition challenge at CVPR.
Manually inspecting railway tracks is a dangerous task, often done by workers at night when trains aren’t running. But with high-speed cameras, transportation companies can instead capture images of the tracks and use AI to automatically detect defects for railway maintenance.
ABEJA, based in Japan, is developing deep learning models that detects anomalies on tracks with more than 90 percent accuracy, a significant improvement over other automated inspection methods. The startup works with SMRT, Singapore’s leading public transport operator, to examine rail defects.
Founded in 2012, ABEJA builds deep learning tools for multiple industries, including retail, manufacturing and infrastructure. Other use cases include an AI to measure efficiency in car factories and a natural language processing model to provide insights for call centers.
The company uses NVIDIA GPUs on premises and in the cloud for training its AI models. For inference, ABEJA has used GPUs for real-time data processing and high-performance image segmentation projects. It has also deployed projects using NVIDIA Jetson TX2 for AI inference at the edge.
The startup is showing a demo of the ABEJA annotation model in its CVPR booth.
Sweden-based Mapillary uses computer vision to automate mapping. Its AI models break down and classify street-level images, segmenting and labeling elements like roads, lane markings, street lights and sidewalks. The company has to date processed hundreds of millions of images submitted by individual contributors, nonprofit organizations, companies and governments worldwide.
These labeled datasets can be used for various purposes, including to create useful maps for local governments, train self-driving cars, or build tools for people with disabilities.
Mapillary is presenting four papers at CVPR this year, including one titled Seamless Scene Segmentation. The model described in the research — a new approach that joins two AI models into one, setting a new state-of-the-art for performance — was trained on eight NVIDIA V100 GPUs.
The segmentation models featured in Mapillary’s CVPR booth were also trained using V100 GPUs. By adopting the NVIDIA TensorRT inference software stack in 2017, Mapillary was able to speed up its segmentation algorithms by up to 27x when running on the Amazon Web Services cloud.
Companies interested in the NVIDIA Inception virtual accelerator can visit the program website and apply to join. Inception members are eligible for a 20 percent discount on up to six NVIDIA TITAN RTX GPUs until Oct. 26.
Startups based in the following countries can request a discount code by emailing inceptionprogram@nvidia.com: Australia, Austria, Belgium, Canada, Czech Republic, Denmark, Finland, France, Germany, Ireland, Italy, Luxembourg, the Netherlands, Norway, Poland, Spain, Sweden, United Kingdom, United States.
The post Making Waves at CVPR: Inception Startups Exhibit GPU-Powered Work in Long Beach appeared first on The Official NVIDIA Blog.