We recently announced that Amazon Transcribe now supports transcription for audio and video for 7 additional languages including Gulf Arabic, Swiss German, Hebrew, Japanese, Malay, Telugu, and Turkish languages. Using Amazon Transcribe, customers can now take advantage of 31 supported languages for transcription use cases such as improving customer service, captioning and subtitling, meeting accessibility requirements, and cataloging audio archives.
Using Amazon Transcribe
Amazon Transcribe is an easy-to-use automatic speech recognition (ASR) service that makes it easy to analyze audio files and convert those into text that includes enrichment such as speaker identification, timestamp generation, punctuation, and formatting. With the recent announcement, customers can now transcribe audio from even more languages.
Using the AWS Management Console, let’s check out one of the latest languages in action. Amazon Transcribe allows users to transcribe streaming audio or perform asynchronous transcription. For this, we will create a job for asynchronous transcription using an audio file stored in Amazon S3 as input.
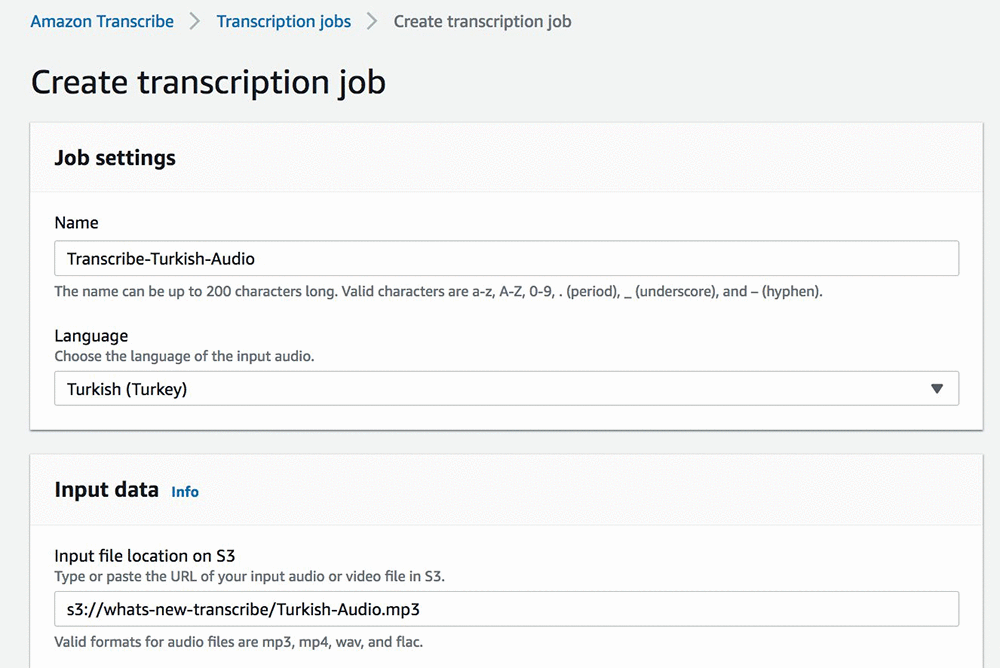
Upon completion of the job, the audio-to-text transcription is provided in the response. For those of us that don’t know Turkish, you can then run your transcribed text through the Amazon Translate service to translate the transcribed text into your preferred language.

In the example above, we are using the console to create the transcription job; however, customers can also programmatically submit transcription jobs using the Amazon Transcribe APIs. The APIs are available in the AWS SDKs. The example below demonstrates invoking the Amazon Transcribe APIs through the AWS CLI:
Start Transcription Job
$ aws transcribe start-transcription-job --transcription-job-name Transcribe-Turkish-Audio-CLI --language-code tr-TR --media MediaFileUri=s3://whats-new-transcribe/Turkish-Audio.mp3 --media-format mp3 --region us-east-1
{
"TranscriptionJob": {
"TranscriptionJobName": "Transcribe-Turkish-Audio-CLI",
"LanguageCode": "tr-TR",
"TranscriptionJobStatus": "IN_PROGRESS",
"Media": {
"MediaFileUri": "s3://whats-new-transcribe/Turkish-Audio.mp3"
},
"CreationTime": 1574392674.948,
"MediaFormat": "mp3"
}
}
Get Information about Transcription Job
$ aws transcribe get-transcription-job --transcription-job-name Transcribe-Turkish-Audio-CLI --region us-east-1
{
"TranscriptionJob": {
"TranscriptionJobName": "Transcribe-Turkish-Audio-CLI",
"LanguageCode": "tr-TR",
"MediaSampleRateHertz": 22050,
"TranscriptionJobStatus": "COMPLETED",
"Settings": {
"ChannelIdentification": false
},
"Media": {
"MediaFileUri": "s3://whats-new-transcribe/Turkish-Audio.mp3"
},
"CreationTime": 1574392674.948,
"CompletionTime": 1574392772.813,
"MediaFormat": "mp3",
"Transcript": {
"TranscriptFileUri": "https://s3.amazonaws.com/aws-transcribe-us-east-1-prod/"
}
}
}
Because we did not explicitly specify a bucket to direct transcription output to, the transcription result is provided via a presigned URL that provides secure access to that transcription. Using the TranscriptFileUri returned on output, we can view/parse that JSON object returned for the transcript text returned.
The transcribed text can then be used for a variety of use cases such as input into Amazon Comprehend for identification of key phrases and key entities such as names, organization names, or as input into Amazon Translate as shown above for translation into one or more languages.
Amazon Transcribe and Amazon Translate for multilingual subtitles
The combined capability of using Amazon Transcribe and Amazon Translate allows customers to quickly transcribe audio as well as convert it into multiple target languages for meeting globalization requirements as well as use cases such as extended global reach on videos or adding subtitles to training videos for your organization. These capabilities can be extended into multilingual subtitles for videos and podcasts. Providing these capabilities allows users to extend global reach by including more language options for broader audiences.
AWS Architecture provides a quick start solution and deployment guide customers can leverage for Live Streaming with Automated Multi-Language Subtitling. This real-time subtitling solution for live streaming video generates multi-language subtitles for live streaming videos using Amazon Transcribe for audio-to-text and Amazon Translate for language translation.
Available Now!
These new languages are available today in all Regions where Amazon Transcribe is available. The free tier offers 60 minutes per month for the first 12 months, starting from your first transcription request.
We’re looking forward to your feedback! Please post it to the AWS Forum for Amazon Transcribe, or send it to your usual AWS Support contacts.
About the author
 Shelbee Eigenbrode is a solutions architect at Amazon Web Services (AWS). Her current areas of depth include DevOps combined with machine learning and artificial intelligence. She’s been in technology for 22 years, spanning multiple roles and technologies. In her spare time she enjoys reading, spending time with her family, friends and her fur family (aka. dogs).
Shelbee Eigenbrode is a solutions architect at Amazon Web Services (AWS). Her current areas of depth include DevOps combined with machine learning and artificial intelligence. She’s been in technology for 22 years, spanning multiple roles and technologies. In her spare time she enjoys reading, spending time with her family, friends and her fur family (aka. dogs).
![[P] I re-implemented Hyperband, check it out!](https://b.thumbs.redditmedia.com/5olaEtnSAzGouSZRAaOSRulKG-i9rlHwhGjlXWKG2wA.jpg "[P] I re-implemented Hyperband, check it out!")
 Chiao-ting Fang is a TTS language engineer for Amazon text-to-speech. She enjoys applying her linguistic knowledge at work to build better, more natural-sounding voices. She loves languages, traveling, and star-gazing.
Chiao-ting Fang is a TTS language engineer for Amazon text-to-speech. She enjoys applying her linguistic knowledge at work to build better, more natural-sounding voices. She loves languages, traveling, and star-gazing.{kind=link}