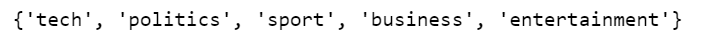I have little knowledge about Artificial Intelligence, and much more knowledge of Neuroscience, so I am having some difficulties answering the question above.
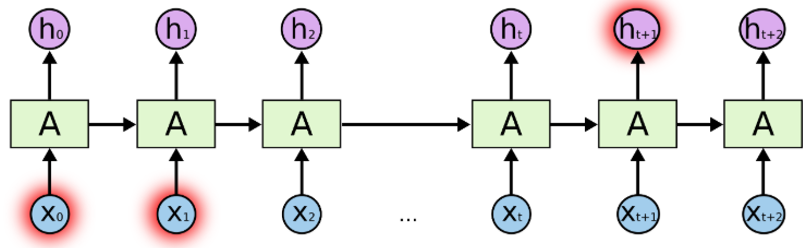
This works well for short sentences, when we deal with a long article, there will be a long term dependency problem.
Therefore, we generally do not use vanilla RNNs, and we use Long Short Term Memory instead. LSTM is a type of RNNs that can solve this long term dependency problem.
In our document classification for news article example, we have this many-to- one relationship. The input are sequences of words, output is one single class or label.
Now we are going to solve a BBC news document classification problem with LSTM using TensorFlow 2.0 & Keras. The data set can be found here.
First, we import the libraries and make sure our TensorFlow is the right version.
There are 2,225 news articles in the data, we split them into training set and validation set, according to the parameter we set earlier, 80% for training, 20% for validation.
Tokenizer does all the heavy lifting for us. In our articles that it was tokenizing, it will take 5,000 most common words. oov_token is to put a special value in when an unseen word is encountered. This means we want <OOV> to be used for words that are not in the word_index. fit_on_text will go through all the text and create dictionary like this:
We can see that “<OOV>” is the most common token in our corpus, followed by “said”, followed by “mr” and so on.
After tokenization, the next step is to turn those tokens into lists of sequence. The following is the 11th article in the training data that has been turned into sequences.
When we train neural networks for NLP, we need sequences to be in the same size, that’s why we use padding. If you look up, our max_length is 200, so we use pad_sequences to make all of our articles the same length which is 200. As a result, you will see that the 1st article was 426 in length, it becomes 200, the 2nd article was 192 in length, it becomes 200, and so on.
In addition, there is padding_type and truncating_type, there are all post, means for example, for the 11th article, it was 186 in length, we padded to 200, and we padded at the end, that is adding 14 zeros.
print(train_padded[10])
Figure 2
And for the 1st article, it was 426 in length, we truncated to 200, and we truncated at the end as well.
Now we are going to look at the labels. Because our labels are text, so we will tokenize them, when training, labels are expected to be numpy arrays. So we will turn list of labels into numpy arrays like so:
Before training deep neural network, we should explore what our original article and article after padding look like. Running the following code, we explore the 11th article, we can see that some words become “<OOV>”, because they did not make to the top 5,000.
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_article(text): return ' '.join([reverse_word_index.get(i, '?') for i in text]) print(decode_article(train_padded[10])) print('---') print(train_articles[10])
Figure 3
Now its the time to implement LSTM.
We build a tf.keras.Sequential model and start with an embedding layer. An embedding layer stores one vector per word. When called, it converts the sequences of word indices into sequences of vectors. After training, words with similar meanings often have the similar vectors.
The Bidirectional wrapper is used with a LSTM layer, this propagates the input forwards and backwards through the LSTM layer and then concatenates the outputs. This helps LSTM to learn long term dependencies. We then fit it to a dense neural network to do classification.
We use relu in place of tahn function since they are very good alternatives of each other.
We add a Dense layer with 6 units and softmax activation. When we have multiple outputs, softmax converts outputs layers into a probability distribution.
In our model summary, we have our embeddings, our Bidirectional contains LSTM, followed by two dense layers. The output from Bidirectional is 128, because it doubled what we put in LSTM. We can also stack LSTM layer but I found the results worse.
print(set(labels))
We have 5 labels in total, but because we did not one-hot encode labels, we have to use sparse_categorical_crossentropy as loss function, it seems to think 0 is a possible label as well, while the tokenizer object which tokenizes starting with integer 1, instead of integer 0. As a result, the last Dense layer needs outputs for labels 0, 1, 2, 3, 4, 5 although 0 has never been used.
If you want the last Dense layer to be 5, you will need to subtract 1 from the training and validation labels. I decided to leave it as it is.
I decided to train 10 epochs, and it is plenty of epochs as you will see.
Actually, as a senior graduate student, I have been doing research in the field of deep learning/nlp for several years. But there is a problem has troubled me a lot during these years. Specifically, a lot of deep learning papers (especially those trying to introduce a new model for some very specific task, for example, reading comprehension, text to SQL, e.t.c) give me a feeling that some design for the model described in the paper is highly engineered and not that intuitive, or in another word, it could have many alternative designs for some module, but few papers really justify why they adopt their specific design in depth. For instance, in a seq2seq setting, some may directly use BERT as the encoder, some may use BERT to generate the embedding for the input sequence first, and then feed the embedding to an LSTM encoder. In fact, this example cannot reveal the problem completely since there can be some other scenarios that have tons of different possible designs that might work, and different papers always adopt their very own design with no much justification.
This really makes me feel extremely bad! First, as a guy who is always eager to know WHY, those papers really can’t answer my question, or maybe it’s just not smart to ask why questions in the context of deep learning model designs. It makes doing research in this field looks more like engineering or even art design, but not science. Secondly, those various designs really impose difficulty in comparing different models. It’s really hard to do control the variables! If one model achieves better performance than the other, it’s hard to tell it is truly due to what the paper claims or some other subtle and tricky designs.
I don’t know is there any other people who feel the same way as me. How should I adjust my mindset for doing research in this field?
For the experts that are keeping up with the everyday ML research breakthroughs could you summarize the best posters/talks to be held at the upcoming NeurIPS 2019? “best” meaning personal best.
If anyone knows of any blog posts on the subject also please post.
My boss wants me to do a hack project where I cluster user feedback / complaints (e.g. people saying “wtf I can’t log in” or “this UI is ugly bla bla” etc.) We have >100k unlabeled data points. There may be jargon in there but it’s mostly legible English. Our goal is to cluster these things so that those talking about the same issue get grouped, and we can take care of them in chunks as nobody wants to read a thousand of these per day.
I’m not an NLP guy by any stretch, so I’ve been reading papers all day to try catching up, however I’m kind of in the middle of the ocean right now. There’s a lot of stuff out there and being inexperienced I thought I’d summon you folks for a discussion on what to try.
My idea now is to use some kind of Transformer model to embed each data point (paragraph) but stuck here as I’m learning that the vectors coming out of those encoders don’t cluster well by text meaning. Let me know any ideas.
P.S. simple models like counting keywords failed me because 1) the data points have a lot of shared vocab so irrelevant things get clustered together, and 2) there are many ways of talking about the same thing with different words.
I was looking for a VM with a GPU to train my model. I was going to use Google Cloud but unfortunately they don’t do business with people from my country so I had to look elsewhere.
That’s when I remembered of paperspace which looked pretty nice. They even have a separate option for ml which allows you send calculations to the cloud and launch notebooks.
But the system wouldn’t accept my card. It simply said “Card is declined”. I reached support and they said that’s probably because their system cannot determine my ip because of VPN or firewall and that I need to turn that off to add card info. Pretty strange thing to ask for IP to simply add payment info but that worked.
I quickly understood that I’m not comfortable with this Gradient service and that I’d like to operate from PyCharm, using vm as a remote interpreter via ssh.
So I tried to rent a regular VM but all the options were locked saying that I need to send a request, describing reasons and ways in which I want to use it. Strange, but I send a request, saying that thing about using PyCharm. Waited a day, no response and sent one more request.
Later that day I get an email from their security staff saying that my account rated highly on their risk matrix and was flagged as suspicious and that I must send them:
a photo of my ID with name matching the card
contact information
company or personal website
link to github or social media accounts
detailed description of what I’m going to do with the service
And if I don’t do it in 24 hours they will ban me forever.
tl;dr accused me of being suspicious and potentially fraudulent and asked all kinds of personal info to unblock me
Well, imo they should balance their false positive rate and improve customer service greatly.
What are other good alternatives for VMs for machine learning? What do you use?
For LeNet trained on MNIST with the lowest possible loss (global minima),
What would the test error rate look like? Is there a benchmark for best possible performance?
Can we achieve global minima on non-convex loss functions for a classification task with a minimum number of parameters? Or conversely, how does adding more parameters to a NN help with this?
I see a lot of brilliant techniques that produce incredible results, but are there any techniques that try to bring learning speeds an order of magnitude or two up even if it costs them half the accuracy, or techniques that try to learn from 400 images instead of 40k?
Or in other words, I would love if someone were to link me some research pursuing non-conventional goals.
I started a project where I’m going to shoot short stories generated by GPT-2. I insert the first line and it completes it. Of course, there is a lot of filling the gaps as sometimes all we get is dialogue and other times only a setting.
This is my first video and I’ve got a few others already shot and plenty scripts selected.
I think this is an interesting application of GPT-2 and illustrates visually that although there is coherence in the text, meaning is many times lost in the process.
It would be amazing if in a few years after posting consistently we can see the evolution of AI generated scripts and who knows we can actually have an interesting story which is not pure absurd comedy as they are mostly now.
Hope you enjoy the project and, if you do, please suggest starting lines.
I applied kmeans clustering to some of the Pollock’s paintings. The idea was to track the artist’s usage of #colors through the years. Here’s the outcome!
I had really good fun in mixing computer science and art. I used Python with the standard data science stack (pandas, numpy, scikitlearn) plus opencv. echarts for the visualizations at the end of the article .