We make a system for supervised learning in Unity. You can use it in a lot of your games to experiment with AI. Nuron Dot Net is used. Also we tried AForge but got big leaning error event on simple XOR function.
Out goal is to make universe system that can be used in any kind of the games.
Let’s say I have a multi-class problem where classes are {A, B, C, Other} – where the Other class is a catch-all for all examples that are not in A, B or C.
The data comes in multiple datasets – D1 and D2. Let’s say D1 has been labeled {A, B, Other-or-C} and D2 has been labeled {A, C, Other-or-B}. In practice we can produce this kind of situation by making all C’s into Other in D1 and all B’s into Other in D2 from the original dataset D that contains all classes.
How can I modify the final layer of the network to accommodate this situation? In the end I want to train a model to predict {A, B, C, Other}
The significance of the problem is related to reducing the tagging effort. When you have D1 with 10000 examples and D2 with 500 examples, it would be much easier to train jointly with D1 and D2 as they are instead of tagging D1 with all tags in D2 and D2 with all tags in D1. Some tags might be common to D1 and D2.
This looks like a multi-task learning problem to me where the tasks are partially overlapping.
How to effectively and creatively pre-process text data
A few months ago, we built a content based recommender system using a relative clean text data set. Because I collected the hotel descriptions my self, I made sure that the descriptions were useful for the goals we were going to accomplish. However, the real-world text data is never clean and there are different pre-processing ways and steps for different goals.
Topic modeling in NLP is rarely my final goal in an analysis, I use it often to either explore data or as a tool to make my final model more accurate. Let me show you what I meant.
The Data
We are still using the Seattle Hotel description data set I collected earlier, and I made it a bit more messier this time. We are going to skip all the EDA processes and I want to make recommendations as quickly as possible.
If you have read my previous post, I am sure you understand the following code script. Yes, we are looking for top 5 most similar hotels with “Hilton Garden Inn Seattle Downtown” (except itself), according to hotel description texts.
Our model returns the above 5 hotels and thinks they are top 5 most similar hotels to “Hilton Garden Inn Seattle Downtown”. I am sure you don’t agree, neither do I. Let’s say why the model thinks they are similar by looking at these descriptions.
df.loc['Hilton Garden Inn Seattle Downtown'].desc
df.loc["Mildred's Bed and Breakfast"].desc
df.loc["Seattle Airport Marriott"].desc
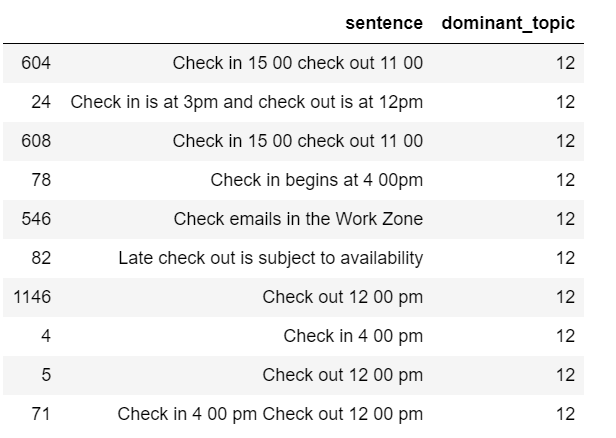
Found anything interesting? Yes, there are indeed somethings in common in these three hotel descriptions, they all have the same check in and check out time, and they all have the similar smoking policies. But are they important? Can we declare two hotels are similar just because they are all “non-smoking”? Of course not, these are not important characteristics and we shouldn’t measure similarity in vector space of these texts.
We need to find a way to safely remove these texts programmatically, while not removing any other useful characteristics.
Topic modeling comes to our rescue. But before that, we need to wrangle the data to make it in the right shape.
Split each description into sentences. Hilton Garden Seattle Downtown’s entire description will be split into 7 sentences.
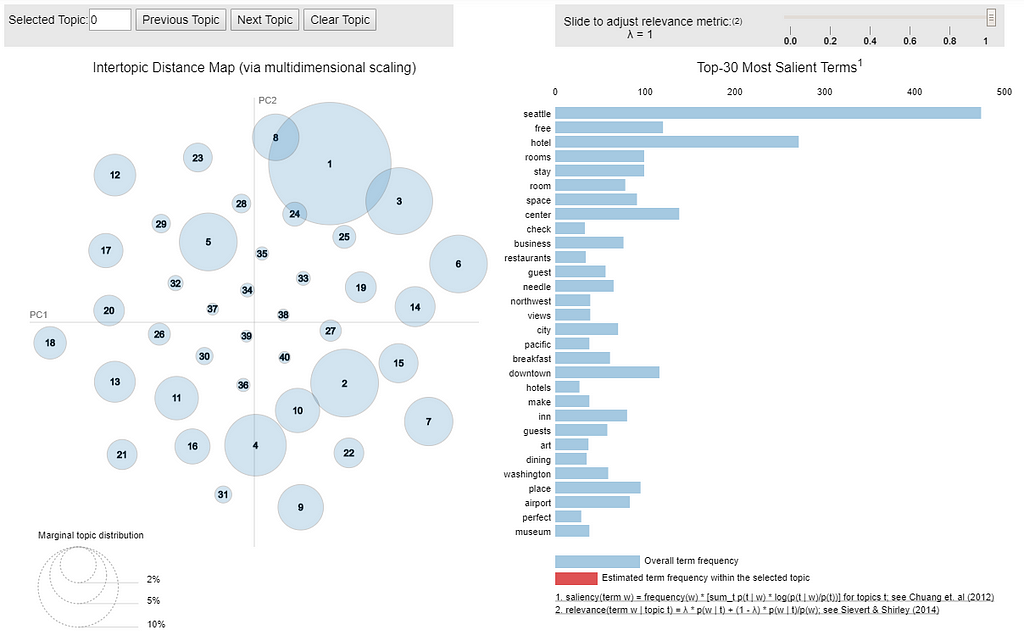
We shall have 40 topics, and each topic shows 20 keywords. Its very hard to print out the entire table, I will only show a small part of it.
Table 2
By staring at the table, we can guess that at least topic 12 should be one of the topics we would like to dismiss, because it contains several words that meaningless for our purpose.
In the following code scripts, we:
Create document-topic matrix.
Create a data frame where each document is a row, and each column is a topic.
The weight of each topic is assigned to each document.
The last column is the dominant topic for that document, in which it carries the most weight.
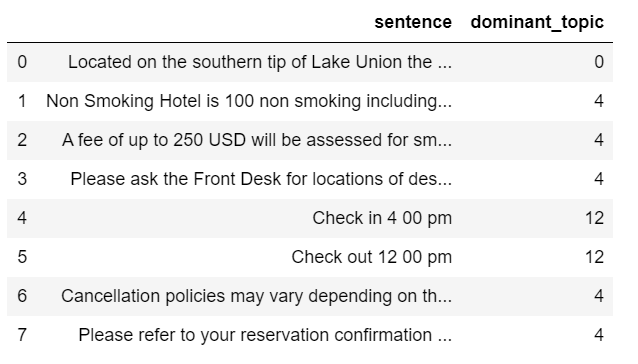
When we merge this data frame to the previous sentence data frame. We are able to find the the weight of each topic in every sentence, and the dominant topic for each sentence.
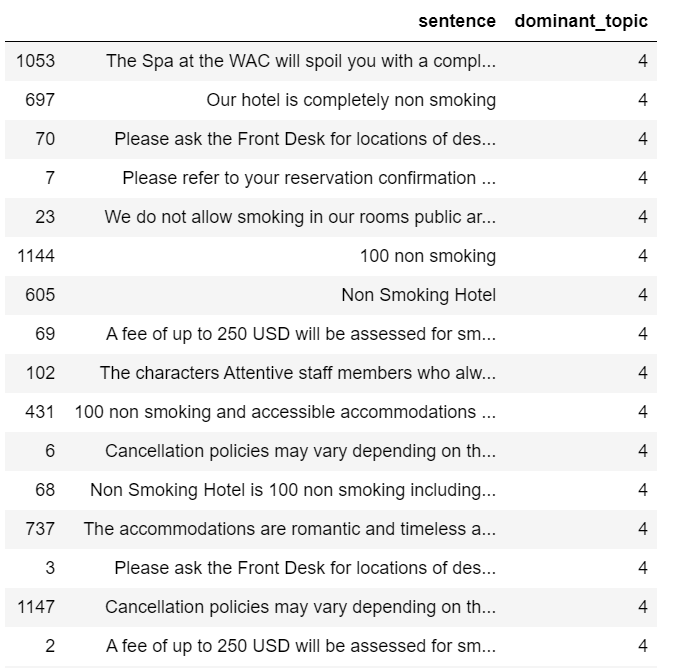
After reviewing the above two tables, I decided to remove all the sentences that have topic 4 or topic 12 as their dominant topic.
print('There are', len(df_sent_topic.loc[df_sent_topic['dominant_topic'] == 4]), 'sentences that belong to topic 4 and we will remove') print('There are', len(df_sent_topic.loc[df_sent_topic['dominant_topic'] == 12]), 'sentences that belong to topic 12 and we will remove')
Let’s see what left for our “Hilton Garden Inn Seattle Downtown”
df_description['sentence'][45]
There is only one sentence left and it is about the location of the hotel and this is what I had expected.
Make Recommendations
Using the same cosine similarity measurement, we are going to find the top 5 most similar hotels with “Hilton Garden Inn Seattle Downtown” (except itself), according to the cleaned hotel description texts.
Highlighting the growing excitement at the intersection of AI, 5G and IoT, NVIDIA CEO Jensen Huang kicks off the Mobile World Congress Los Angeles 2019 Monday, Oct. 21.
The keynote, NVIDIA’s debut at the wireless industry’s highest-profile gathering in the U.S., will be the first of a slate of talks and training sessions from NVIDIA and its partners.
The AI revolution is spurring a wave of progress across the mobile technology industry that’s unleashing unprecedented capabilities and new opportunities.
NVIDIA is at the center of this, thanks to AI and accelerated computing capabilities that have been adopted by industries across the globe.
Jensen Huang to Deliver Agenda-Setting Keynote
Huang will detail how the latest AI and accelerated computing innovations will transform the wireless industry in a keynote that’s open to all on Monday, Oct. 21, at the Los Angeles Convention Center’s Petree Hall.
Our Deep Learning Institute — one of the largest training programs in the world for AI and accelerated computing — has partnered with the show’s sponsor, the GSMA.
Together, we’re offering hands-on training to the show’s attendees in the South Hall, booth 1743.
The training is on a first-come, first-served basis. No need to sign up in advance.
Get Inspired at NVIDIA Booth 1745
If you’re attending the event, our booth will serve as a hub for the innovations we’re bringing to the show.
At the booth, you’ll find NVIDIA Inception partners using our Metropolis platform to showcase a variety of real-world applications that demand GPUs at the edge.
Get Oriented at the NVIDIA Theater
Want to dig into the nit and grit of delivering services such as these? Stop by the NVIDIA Theater to hear speakers from NVIDIA, our partners and our customers.
Among the highlights, Saurabh Jain, director of products and strategic partnerships at NVIDIA, will detail how edge computing brings compute and storage closer to the point of action.
That’s critical for smart cities, and it’s opening up new business and service revenue opportunities for the telecom industry.
Visit NVIDIA booth 1745 at 1:30 pm on Oct. 23 to hear his talk, and stick around for others from key industry leaders.
The Milky Way is on a collision course with the neighboring Andromeda galaxy. But no need to revise your will — the two star systems won’t meet for around 4 billion years.
“At some point in every galaxy’s life, it’ll undergo one of these mergers,” said William Pearson, Ph.D. student at the Netherlands Institute for Space Research and the University of Groningen, Netherlands. “It’s part of our understanding of how we think the universe works. These galaxies tend to find and crash into each other.”
When two galaxies merge, the resulting fused galaxy mixes together all the gas, dust and other matter from the original star systems. Astronomers are interested in how the shape of galaxies change as a result, how the process can cause stars to form at a higher rate, and how the moving matter interacts with the supermassive black holes lying at the center of large galaxies.
By using AI to identify and analyze galaxy mergers across the universe, scientists can better understand how this phenomenon could affect our corner of the universe in the future.
Hubble Up: Analyzing Galaxy Mergers with AI
For the most part, it’s not rocket science to visually determine whether two galaxies are in the thick of a collision.
This image, taken by the Hubble Space Telescope, shows a collision between two spiral galaxies located in the constellation of Hercules, located around 450 million light-years away from Earth. Image credit: NASA, ESA, the Hubble Heritage Team (STScI/AURA)-ESA/Hubble Collaboration and K. Noll (STScI). Licensed under CC BY 4.0.
Just looking at a telescope image, it’s easy to spot tidal tails, sweeping arcs of gas and dust being pulled from one galaxy to another by gravity.
The main challenge is classifying galaxies that are just starting to interact, or, on the other end of the spectrum, at the very final stages of a merge.
And then there’s the sheer volume of data.
Crowdsourced projects like Galaxy Zoo have relied on citizen scientists to classify a database of more than a million galaxy images from various ground-based and satellite telescopes. But that’s just a fraction of an estimated 100 billion galaxies in the universe.
And the available data is just getting larger. Projects like the under-construction Large Synoptic Survey Telescope are expected to capture images of billions of galaxies.
“There’s not enough people in the world to classify all these,” Pearson said. “As astronomers, we need another technique.”
While citizen scientist projects are a powerful tool, it still takes a long time for results to come through, he says. Deep learning models can help researchers keep pace with the many ground- and space-based telescopes busy collecting images of the universe, most of which are publicly available for analysis.
Using an NVIDIA GPU for inference, Pearson’s AI was able to categorize 300,000 galaxies in about 15 minutes. Even at an unheard-of rate of one classification per second, it would have taken an individual two working weeks to accomplish the task.
Trained using the TensorFlow deep learning framework and images from the Sloan Digital Sky Survey, the deep learning model identifies galaxies as merging or not merging with 92 percent accuracy. Pearson hopes for future versions of the CNN to look at more specific details, such as the size of the galaxies and how far along the merging process is.
From this data, researchers can make statistical assessments of broad trends in galaxy mergers — or take a closer look at specific galaxies of interest.
Main image shows two merging galaxies, nicknamed “The Mice,” located 300 million light-years away. Image credit: NASA, Holland Ford (JHU), the ACS Science Team and ESA. Licensed under CC BY 4.0.
I created a tool to visualize the spectral clustering algorithm (for graphs).
What is spectral clustering? Spectral clustering is a clustering technique that can operate either on graphs or continuous data. It makes use of the eigenvectors of the laplacian- or similarity matrix of the data to find optimal cuts to separate the graph into multiple components.