TLDR: Corrupting a small patch of less than 1% of the image size lead to noisy flow estimates that extend beyond the region of the attack, even erasing the motion of objects in the scene in some cases
Anurag Ranjan, Joel Janai, Andreas Geiger, Michael J. Black
(Submitted on 22 Oct 2019)
Deep neural nets achieve state-of-the-art performance on the problem of optical flow estimation. Since optical flow is used in several safety-critical applications like self-driving cars, it is important to gain insights into the robustness of those techniques. Recently, it has been shown that adversarial attacks easily fool deep neural networks to misclassify objects. The robustness of optical flow networks to adversarial attacks, however, has not been studied so far. In this paper, we extend adversarial patch attacks to optical flow networks and show that such attacks can compromise their performance. We show that corrupting a small patch of less than 1% of the image size can significantly affect optical flow estimates. Our attacks lead to noisy flow estimates that extend significantly beyond the region of the attack, in many cases even completely erasing the motion of objects in the scene. While networks using an encoder-decoder architecture are very sensitive to these attacks, we found that networks using a spatial pyramid architecture are less affected. We analyse the success and failure of attacking both architectures by visualizing their feature maps and comparing them to classical optical flow techniques which are robust to these attacks. We also demonstrate that such attacks are practical by placing a printed pattern into real scenes.
Hello, I have some basic experience with machine learning using Python, but I’ve been unable to find a guide on how to do what I’d like to do. That is, I’d like to train a model using my collection of audio files (hundreds of thousands of MP3s, WAVs, and FLACs) and output new audio files. I would greatly appreciate any help or points in the right direction!
What do you think is the best open-source model management framework and why? I’ve looked into ModelDB, Polyaxon, studio.ml, datmo, etc., but I’m not sure which one people consider the best/most robust. Have you guys used or tried any, and if so, what did you like and not like?
Uncover new insights in early childhood education and how media can support learning outcomes.
PBS KIDS, a trusted name in early childhood education for decades, aims to gain insights into how media can help children learn important skills for success in school and life. In this challenge, you’ll use anonymous gameplay data, including knowledge of videos watched and games played, from the PBS KIDS Measure Up! app, a game-based learning tool developed as a part of the CPB-PBS Ready To Learn Initiative with funding from the U.S. Department of Education. Competitors will be challenged to predict scores on in-game assessments and create an algorithm that will lead to better-designed games and improved learning outcomes. Your solutions will aid in discovering important relationships between engagement with high-quality educational media and learning processes.
In the PBS KIDS Measure Up! app, children ages 3 to 5 learn early STEM concepts focused on length, width, capacity, and weight while going on an adventure through Treetop City, Magma Peak, and Crystal Caves. Joined by their favorite PBS KIDS characters, children can also collect rewards and unlock digital toys as they play.
Above is an update to an ongoing “Applied-ML” project of mine.
This is a pan tilt turret equipped with an infrared depth camera that is being guided by YOLOv3 in ROS to track “Human heads”. I trained YOLO using Google OpenImages V4, and used pirobot’s code for “Robotics By Example, volume 2”, leggedrobotic’s darknet_ros, and my own headtracker node to take the 2D data for the bounding boxes from YOLO and retrieve the 3D data associated with specific depth registered RGB pixel coordinates for tracking.
The detection is much smoother in this release, although at about :12 in the video here, it jolts hard to the right in error (likely an error in lead and/or joint speed update, should be easy to resolve).
YOLO performs significantly better on the NVidia Tesla k40 that I’m using here as well, upgraded from the GTX1060 in my previous post. I’m also using a calibrated Orbbec Astra Pro instead of the Kinect 360 as well. The depth registration of the RGB as well as the stability of the detection has noticably improved.
I plan to begin the challenge of designing a rudimentary implementation of “visual dialogue” with this in an eventual upcoming upgrade. Ideally, I want this to be able to not just hold somewhat of a conversation, but be able to look around a room at objects that it’s capable of detecting, use SLAM to store their location, and interact with people and the world around it verbally and within context (an example being “what is that cat behind you doing?” and have it respond with looking for said cat, tracking and mapping it’s location, and generating a verbal response).
Stay tuned for more updates; the next will be a bit more exciting!
Link to the first release of this bot and description of the underlying technology is below:
Posted by Serge Belongie, Visiting Faculty and Hartwig Adam, Engineering Director, Google Research
The promise of machine learning (ML) for speciesidentification is coming to fruition, revealing its transformative potential in biodiversity research. International workshops such as FGVC and LifeCLEF feature competitions to develop top performing classification algorithms for everything from wildlife camera trap images to pressed flower specimens on herbarium sheets. The encouraging results that have emerged from these competitions inspired us to expand the availability of biodiversity datasets and ML models from workshop-scale to global-scale.
Bringing powerful ML algorithms to the communities that need them requires more than the traditional “big data + big compute” equation. Institutions ranging from natural history museums to citizen science groups take great care to collect and annotate datasets, and the data they share have enabled numerous scientific research publications. But central to the tradition of scholarly research are the conventions of citation and attribution, and it follows that as ML extends its reach into the life sciences, it should bring with it appropriate counterparts to those conventions. More broadly, there is a growing awareness of the importance of ethics, fairness, and transparency within the ML community. As institutions develop and deploy applications of ML at scale, it is critical that they be designed with these considerations in mind.
This week at Biodiversity Next, in collaboration with the Global Biodiversity Information Facility (GBIF), iNaturalist, and Visipedia, we are announcing a new workflow for biodiversity research institutions who would like to make use of ML. With its billion+ species occurrence count contributed by thousands of institutions around the globe, GBIF is playing a vital role in enabling this workflow, whether in terms of data aggregation, collaboration across teams, or standardizing citation practices. In the short term, the most important role relates to an emerging cultural shift in accepted practices for the use of mediated data for training of ML models. In the process of data mediation, GBIF helps ensure that training datasets for ML follow standardized licensing terms, use compatible taxonomies and data formats, and provide fair and sufficient data coverage for the ML task at hand by potentially sampling from multiple source datasets.
This new workflow comprises the following two components:
To assist in developing and refining machine vision models, GBIF will package datasets, taking care to ensure license and citation practice are respected. The training datasets will be issued a Digital Object Identifier (DOI), and will be linked through the DOI citation graph.
To assist application developers, Google and Visipedia will train and publish publicly accessible models with documentation on TensorFlow Hub. These models can then, in turn, be deployed in biodiversity research and citizen science efforts.
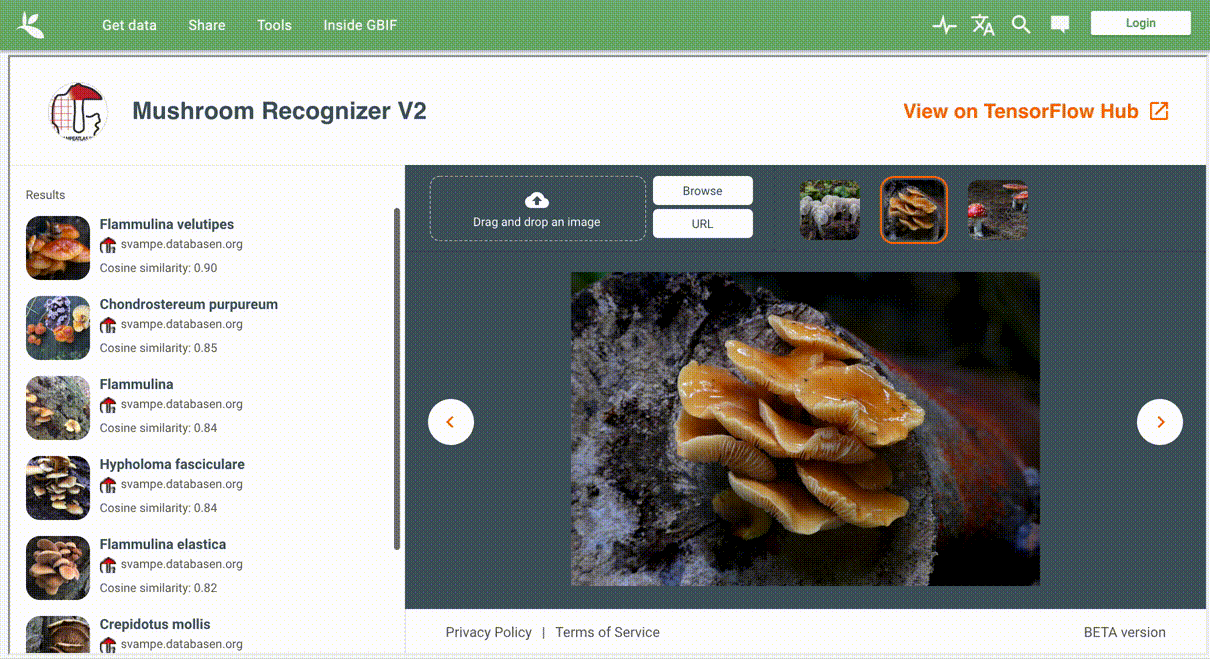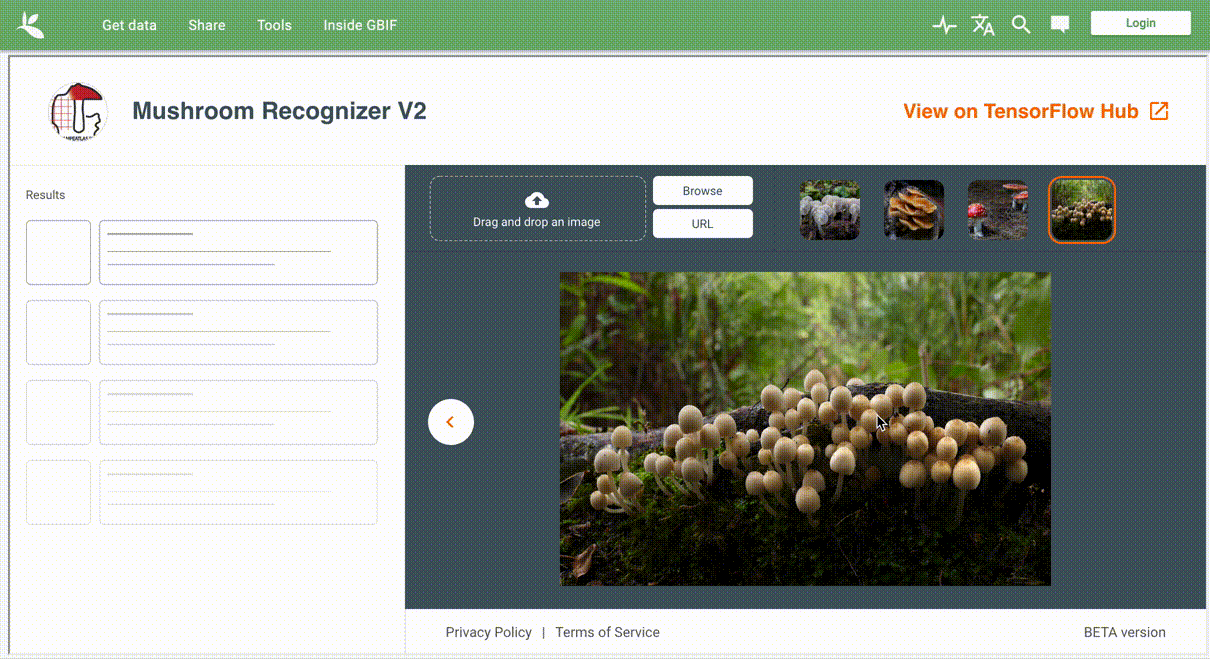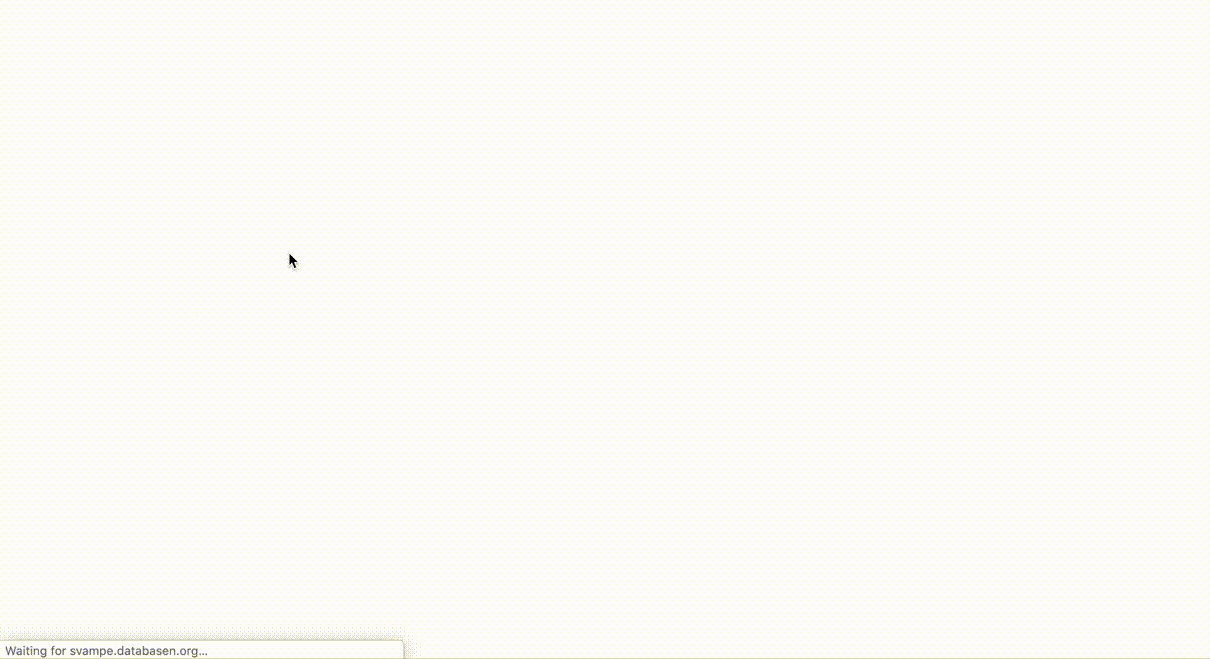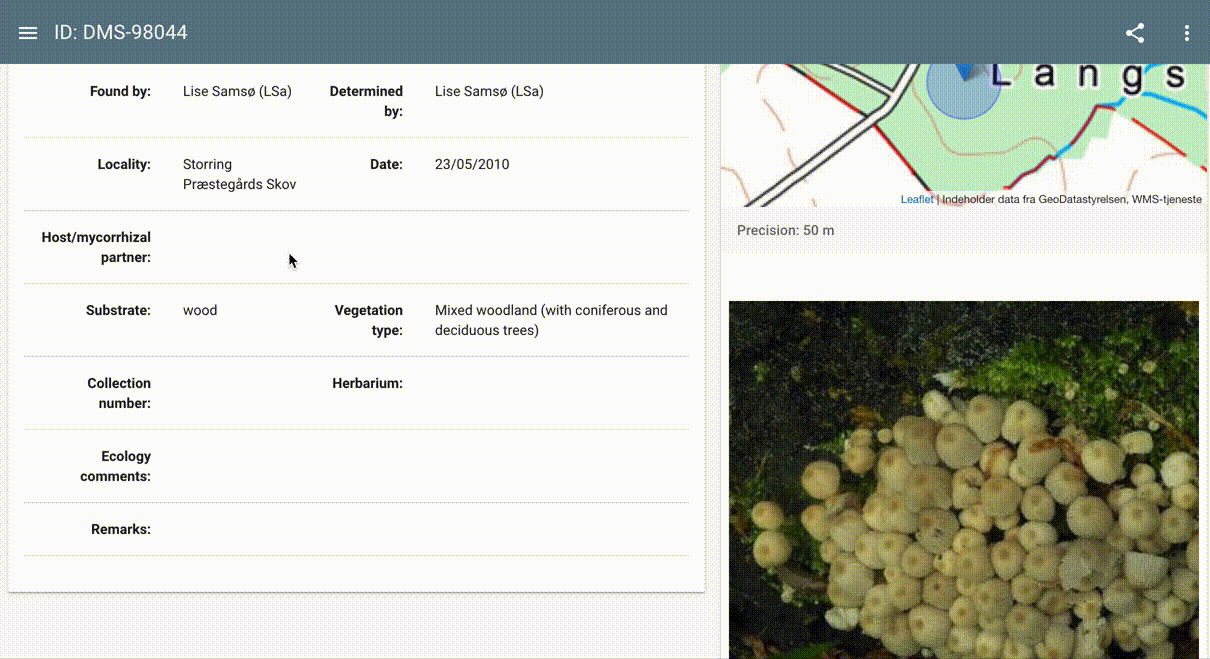
Case Study: Recognizing Fungi Species from Photos with the Interactive Mushroom Recognizer As an illustration of the above workflow, we present an example of fungi recognition. The dataset in this case is curated by the Danish Mycological Society, and formatted, packaged, and shared by GBIF. The dataset provenance, model architecture, license information, and more can be found on the TF Hub model page, along with a live, interactive demonstration of the model that can run on user-supplied images.
Illustration of live, interactive Mushroom Recognizer, powered by a publicly available model trained on a fungi dataset provided by the Danish Mycological Society.
Invitation to Participate For more information about this initiative, please visit the project page at GBIF. We look forward to engaging with institutions around the globe to enable new and innovative uses of ML for biodiversity.
Acknowledgements We’d like to thank our collaborators at GBIF, iNaturalist, and Visipedia for working together to develop this workflow. At Google we would like to thank Christine Kaeser-Chen, Chenyang Zhang, Yulong Liu, Kiat Chuan Tan, Christy Cui, Arvi Gjoka, Denis Brulé, Cédric Deltheil, Clément Beauseigneur, Grace Chu, Andrew Howard, Sara Beery, and Katherine Chou.
MLP is a bit old, however it is mature to be deployed in industry. This repo has two purposes: a minimal C++ MLP code for education and the real time performance for the industry/IoT. There are several good points:
0: It uses standard C++ code, no magic instruction. Thus is portable to most machines.
1: It use c++ templates, thus inlines everything. It works like a pre-defined static function, pure stream of float point instructions.
2: It works by SGD of 1 sample each time. Thus it enables real time learning and prediction which is useful for future industry. The training “FPS” can reach 100k for a 32-hidden,16-layer network, eg. We can learn and predict each WAV frame as it arrives.
3: It use shared hidden-hidden weights. In fact it is similar to RNN making use of marginal chaos. This reduces the size of network to the cache without loss of accuracy.
4: the activation function used is y=x/(1+|x|) which is sigmoid like. It and its gradient are fast to calculate and not easily saturated.
5: experiment shows that only a single CPU thread is needed, and more threads just not improve the speed due to memory bound.
6: for >=32 hidden units, gcc autovectorization will turn it to SSE/AVX code, which is 4X faster.
7: the float point type is a template parameter, float/double/long double are OK.
A new report estimates the cost of waste in the U.S. healthcare system alone ranges as high as $935 billion a year, about 25 percent of total healthcare spending.
A growing army of startups and established practitioners sees the inefficiencies as a trillion-dollar opportunity to apply AI.
The U.S. spends about 18 percent of its gross domestic product on healthcare, more than any other country. A report published online by the Journal of the American Medical Association surveyed 54 studies to estimate annual waste figures in six broad categories, including failures from choosing ineffective treatments (up to $166 billion), failures from coordinating multiple treatments ($78 billion), fraud and abuse ($84 billion) and administrative complexity ($266 billion).
“Implementation of effective measures to eliminate waste represents an opportunity to reduce the continued increases in U.S. health care expenditures,” the report concluded.
MICCAI Heard the Call
Researchers echoed that theme at a major medical imaging conference in Shenzhen, China, recently.
Shiyuan Liu
Catherine Mohr, vice president of strategy at Intuitive Surgical, reviewed the history of medtech with an eye on “how to think about distinguishing price from value when developing the next generation of medical devices,” in a keynote at this year’s International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI).
Attendees also got an update on the state of the art in using AI in medical imaging in a keynote from Shiyuan Liu, president of the Chinese Medical Imaging AI Innovation Alliance. Liu called for practitioners, vendors and academics to work together to drive AI forward.
700+ AI Healthcare Startups
Opportunities span the waterfront. “Every single type of health professional” will be impacted by AI, said Eric Topol, founder and director of the Scripps Research Translational Institute, in a keynote at NVIDIA’s GTC event in Silicon Valley earlier this year. AI will help practitioners provide “better, faster, cheaper” care, said the author of the recently released book, “Deep Medicine: How Artificial Intelligence Can Make Healthcare Human Again.”
That message has not been lost on entrepreneurs. A recent healthcare event sponsored by a major Wall Street bank was “crawling with tech VCs, and five years ago that was not the case,” said Jeff Herbst, vice president of business development at NVIDIA.
With more than 700 startups, healthcare represents the largest category in NVIDIA’s Inception accelerator program that provides AI training and tools to fuel their growth. Herbst calls out Biotrillion as one to watch. The startup generates digital biomarkers to detect disease using its own analytics on sensor data from a user’s smartphone and smartwatch.
“The biggest opportunity in healthcare is in using AI to keep people well — this is the most exciting area to me,” he said.
Houston-based InformAI helps reduce fatigue and stress for radiologists by building deep learning tools that can help them analyze medical scans faster. It’s image classifiers and patient outcome predictors run both on NVIDIA V100 GPUs in the Microsoft Azure cloud platform and an onsite NVIDIA DGX Station. In just 30 seconds they can analyze a patient’s 3D CT scan for 20 sinus conditions.
Subtle Medical of Menlo Park, CA, announced this week that it received FDA clearance for SubtleMR, its deep learning solution for improving the image quality of MRIs. The Inception member’s first product, SubtlePET, which can produce PET images in as little as a quarter of the scanning time of current systems, received FDA clearance last year. Both products are trained on DGX-1 and DGX Station and enabled by TensorRT.
Major Players Embrace AI
Medical imaging is one of the biggest areas in healthcare AI, with startups scattered around the globe. They include South Korean startup Lunit and InferVISION, one of China’s top medical imaging startups, focusing on lung nodule analysis and prediction from CT scans.
Major providers and vendors are also embracing AI. Two developers from UnitedHealth Group, one of the largest healthcare companies in the U.S., shared in a talk at GTC earlier this year how the provider is adopting AI for tasks that span prior authorization of medical procedures to directing phone calls.
In June, Siemens Healthineers and NVIDIA shared their latest work in AI for medical imaging at the Society for Imaging Informatics in Medicine annual conference. Siemens Healthineers is using an NVIDIA GPU-based supercomputing infrastructure to develop AI software for generating organ segmentations that enable precision radiation therapy.
“The area that will have the biggest impact in AI is healthcare,” said Ian Buck, vice president of NVIDIA’s Accelerated Computing Group in a recent interview.
“The healthcare industry is chock full of data … there are many obstacles ahead, but I am truly hopeful AI can help cure diseases and save lives — that makes me excited about the work we do,” Buck said.
The algorithm was performing its task correctly — it accurately predicted future health costs for patients to determine which ones should get extra care. But it still ended up discriminating against black patients.
A really interesting read (and interview with Topcoder CEO Mike Morris and Dr. Raymond H. Mak of Harvard Medical Schooll) on a collaboration between Harvard Medical School and Topcoder on the tremendous progress that they have made in identifying Lung Cancer.