Posted by Catherina Xu and Tulsee Doshi, Product Managers, Google Research
While industry and academia continue to explore the benefits of using machine learning (ML) to make better products and tackle important problems, algorithms and the datasets on which they are trained also have the ability to reflect or reinforce unfair biases. For example, consistently flagging non-toxic text comments from certain groups as “spam” or “high toxicity” in a moderation system leads to exclusion of those groups from conversation.
In 2018, we shared how Google uses AI to make products more useful, highlighting AI principles that will guide our work moving forward. The second principle, “Avoid creating or reinforcing unfair bias,” outlines our commitment to reduce unjust biases and minimize their impacts on people.
As part of this commitment, at TensorFlow World, we recently released a beta version of Fairness Indicators, a suite of tools that enable regular computation and visualization of fairness metrics for binary and multi-class classification, helping teams take a first step towards identifying unjust impacts. Fairness Indicators can be used to generate metrics for transparency reporting, such as those used for model cards, to help developers make better decisions about how to deploy models responsibly. Because fairness concerns and evaluations differ case by case, we also include in this release an interactive case study with Jigsaw’s Unintended Bias in Toxicity dataset to illustrate how Fairness Indicators can be used to detect and remediate bias in a production machine learning (ML) model, depending on the context in which it is deployed. Fairness Indicators is now available in beta for you to try for your own use cases.
What is ML Fairness?
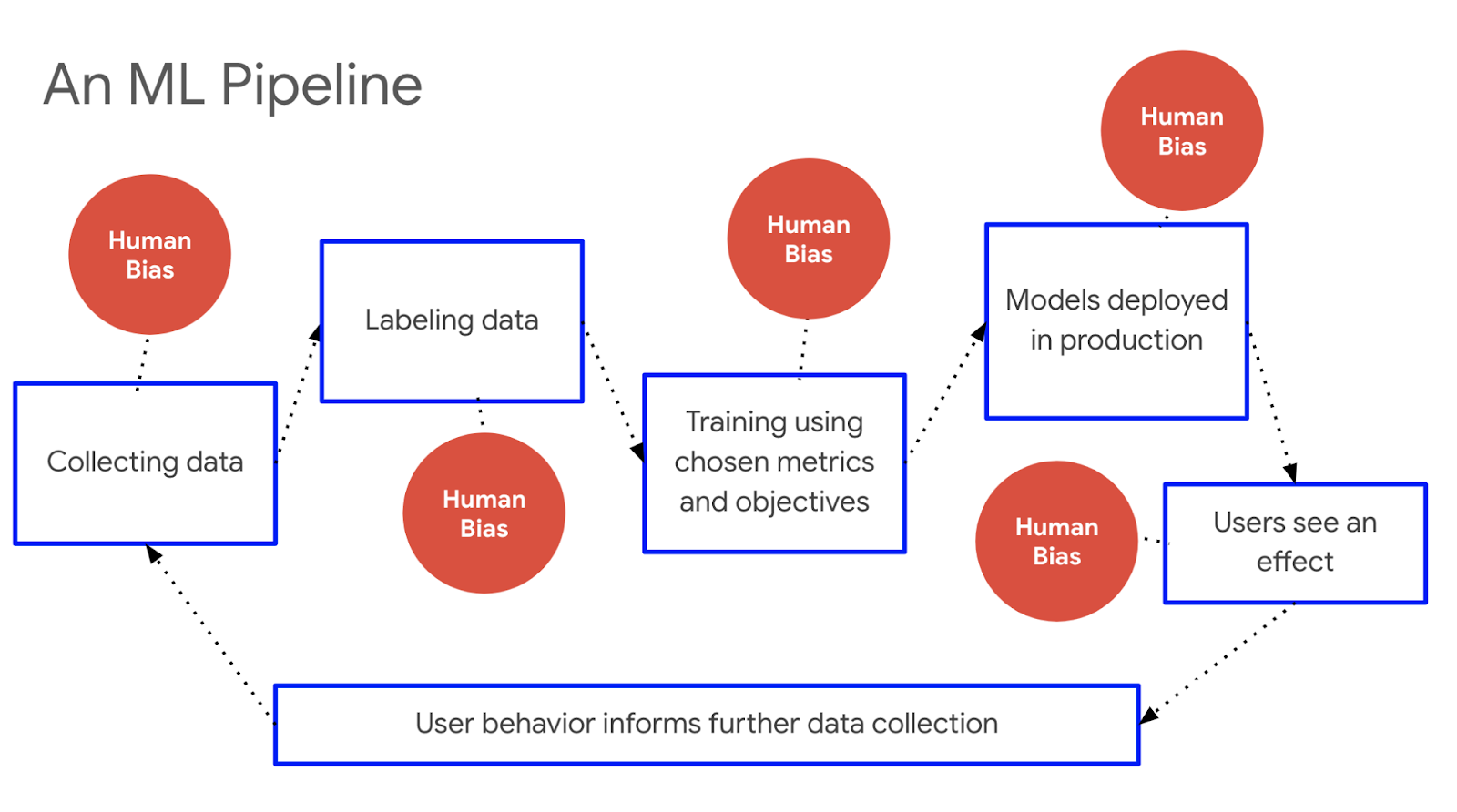
Bias can manifest in any part of a typical machine learning pipeline, from an unrepresentative dataset, to learned model representations, to the way in which the results are presented to the user. Errors that result from this bias can disproportionately impact some users more than others.

To detect this unequal impact, evaluation over individual slices, or groups of users, is crucial as overall metrics can obscure poor performance for certain groups. These groups may include, but are not limited to, those defined by sensitive characteristics such as race, ethnicity, gender, nationality, income, sexual orientation, ability, and religious belief. However, it is also important to keep in mind that fairness cannot be achieved solely through metrics and measurement; high performance, even across slices, does not necessarily prove that a system is fair. Rather, evaluation should be viewed as one of the first ways, especially for classification models, to identify gaps in performance.
The Fairness Indicators Suite of Tools
The Fairness Indicators tool suite enables computation and visualization of commonly-identified fairness metrics for classification models, such as false positive rate and false negative rate, making it easy to compare performance across slices or to a baseline slice. The tool computes confidence intervals, which can surface statistically significant disparities, and performs evaluation over multiple thresholds. In the UI, it is possible to toggle the baseline slice and investigate the performance of various other metrics. The user can also add their own metrics for visualization, specific to their use case.
Furthermore, Fairness Indicators is integrated with the What-If Tool (WIT) — clicking on a bar in the Fairness Indicators graph will load those specific data points into the the WIT widget for further inspection, comparison, and counterfactual analysis. This is particularly useful for large datasets, where Fairness Indicators can be used to identify problematic slices before the WIT is used for a deeper analysis.
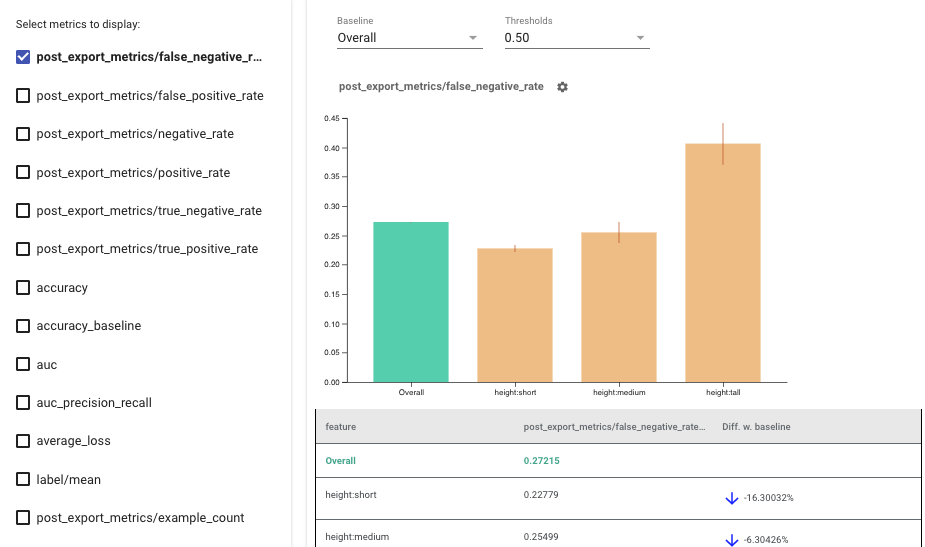
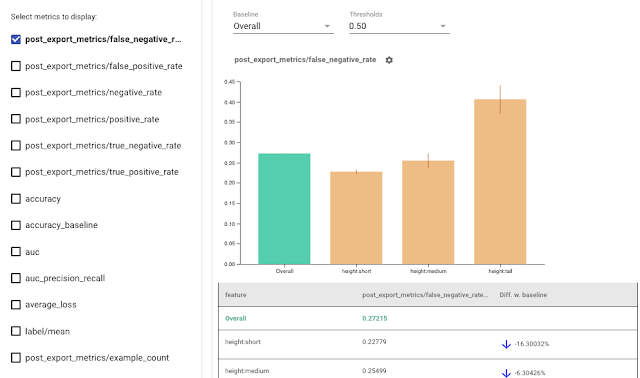 |
| Using Fairness Indicators to visualize metrics for fairness evaluation. |
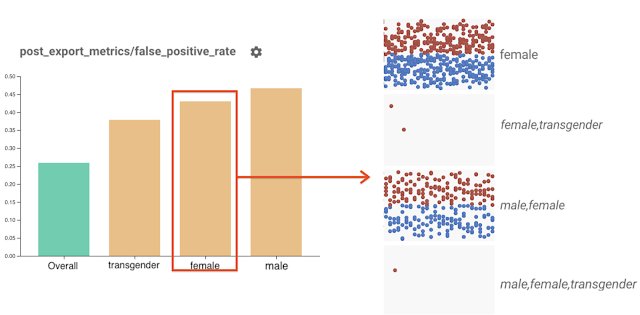 |
| Clicking on a slice in Fairness Indicators will load all the data points in that slice inside the What-If Tool widget. In this case, all data points with the “female” label are shown. |
The Fairness Indicators beta launch includes the following:
How To Use Fairness Indicators in Models Today
Fairness Indicators is built on top of TensorFlow Model Analysis, a component of TensorFlow Extended (TFX) that can be used to investigate and visualize model performance. Based on the specific ML workflow, Fairness Indicators can be incorporated into a system in one of the following ways:
If using TensorFlow models and tools, such as TFX:
- Access Fairness Indicators as part of the Evaluator component in TFX
- Access Fairness Indicators in TensorBoard when evaluating other real-time metrics
If not using existing TensorFlow tools:
- Download the Fairness Indicators pip package, and use Tensorflow Model Analysis as a standalone tool
For non-TensorFlow models:
Fairness Indicators Case Study
We created a case study and introductory video that illustrates how Fairness Indicators can be used with a combination of tools to detect and mitigate bias in a model trained on Jigsaw’s Unintended Bias in Toxicity dataset. The dataset was developed by Conversation AI, a team within Jigsaw that works to train ML models to protect voices in conversation. Models are trained to predict whether text comments are likely to be abusive along a variety of dimensions including toxicity, insult, and sexual explicitness.
The primary use case for models such as these is content moderation. If a model penalizes certain types of messages in a systematic way (e.g., often marks comments as toxic when they are not, leading to a high false positive rate), those voices will be silenced. In the case study, we investigated false positive rate on subgroups sliced by gender identity keywords that are present in the dataset, using a combination of tools (Fairness Indicators, TFDV, and WIT) to detect, diagnose, and take steps toward remediating the underlying problem.
What’s next?
Fairness Indicators is only the first step. We plan to expand vertically by enabling more supported metrics, such as metrics that enable you to evaluate classifiers without thresholds, and horizontally by creating remediation libraries that utilize methods, such as active learning and min-diff. Because we believe it is important to learn through real examples, we hope to ground our work in more case studies to be released over the next few months, as more features become available.
To get started, see the Fairness Indicators GitHub repo. For more information on how to think about fairness evaluation in the context of your use case, see this link.
We would love to partner with you to understand where Fairness Indicators is most useful, and where added functionality would be valuable. Please reach out at tfx@tensorflow.org to provide any feedback on your experience!
Acknowledgements
The core team behind this work includes Christina Greer, Manasi Joshi, Huanming Fang, Shivam Jindal, Karan Shukla, Osman Aka, Sanders Kleinfeld, Alicia Chang, Alex Hanna, and Dan Nanas. We would also like to thank James Wexler, Mahima Pushkarna, Meg Mitchell and Ben Hutchinson for their contributions to the project.



 Ankit Dhawan is a Senior Product Manager for Amazon Polly, a technology enthusiast, and a huge Liverpool FC fan. When not working on delighting our customers, you will find him exploring the Pacific Northwest with his wife and dog. He is an eternal optimist, loves reading biographies, and playing poker. You can indulge him in a conversation on technology, entrepreneurship, or soccer anytime of the day.
Ankit Dhawan is a Senior Product Manager for Amazon Polly, a technology enthusiast, and a huge Liverpool FC fan. When not working on delighting our customers, you will find him exploring the Pacific Northwest with his wife and dog. He is an eternal optimist, loves reading biographies, and playing poker. You can indulge him in a conversation on technology, entrepreneurship, or soccer anytime of the day.