Posted by Rajan Patel, Director, Augmented Reality
Around the world, millions of people are coming online for the first time, and many of them are among the 800 million adults worldwide who are unable to read or write, or those who are migrating to towns and cities where they are not able to speak the predominant language. As a smartphone camera-based tool, Google Lens has great potential for helping people who struggle with reading and other language-based challenges. Lens uses computer vision, machine learning and Google’s Knowledge Graph to let people turn the things they see in the real world into a visual search box, enabling them to identify objects like plants and animals, or to copy and paste text from the real world into their phone.
However, in order for Lens to be able to help the greatest number of people, we needed to create a special version that can work on even the most basic smartphones. So at I/O 2019, we announced a new version of Lens designed specifically for use in Google Go—our Search app for entry level devices—and we included a new set of features designed to help people who face reading and other language-based challenges. When users point their camera at text they don’t understand, Lens in Google Go can translate and read it out loud. It even highlights each word as it’s being read so users can follow along. If you want to try out these features for yourself, they are available today via Lens in Google Go. While Google Go was initially available only on Android Go devices and on the Google Play Store in select markets, recently, we made it available globally in the Google Play Store.

To make these reading features work, the Google Go version of Lens needs to be able to capture high quality images on a wide variety of devices, then identify the text, understand its structure, translate and overlay it in context, and finally, read it out loud.
Image Capture
Image capture on entry-level devices, like those that run Android Go, is tricky since it must work on a wide variety of devices, many of which are more resource constrained than flagship phones. To build a universal tool that can reliably capture high-quality images with minimal lag, we made Lens in Google Go an early adopter of a new Android support library called CameraX. Available in Jetpack—a suite of libraries, tools, and guidance for Android developers—CameraX is an abstraction layer over the Android Camera2 API that resolves device compatibility issues so developers don’t have to write their own device-specific code.
Using CameraX, we implemented two capture strategies to balance capture latency against performance impact. On higher-end phones, which are powerful enough to provide a constant stream of high-resolution frames from which to select an image, we’ve made capture instantaneous. On less advanced devices, streaming these frames could cause camera lag since the CPU is less powerful, so we process the frame when the user taps capture to produce a single, on-demand high-resolution image.
Text Recognition
After Lens in Google Go captures an image, it needs to make sense of the shapes and letters that constitute the words, sentences and paragraphs. To do this, the image is scaled down and transferred to the Lens server, where the processing will be performed. Next, optical character recognition (OCR) is applied, which utilizes a region proposal network to detect character level bounding boxes that can be merged into lines for text recognition.
Merging these character boxes into words is a two-step, sequential process. The first step is to apply the Hough Transform, which assumes the text is distributed across parallel lines. The second step uses Text Flow, which instead traces text that may follow a curve by finding the shortest path through a graph of detected text boxes. This ensures that text with a variety of distributions, be they straight, curved or mixed, can be identified and processed.
Because the images captured by Lens in Google Go may include sources such as signage, handwriting or documents, a slew of additional challenges can arise. For example, the text can be obscured, scripts can be uniquely stylized, and images can be blurry. All of these issues can cause the OCR engine to misunderstand various characters within each word. To correct mistakes and improve word accuracy, Lens in Google Go uses the context of surrounding words to make corrections. It also utilizes the Knowledge Graph to provide contextual clues, such as whether a word is likely a proper noun and should not be spell-corrected.
All of these steps, from script detection and direction identification to text recognition, are performed by separable convolutional neural networks (CNNs) with an additional quantized long short-term memory (LSTM) network. And the models are trained on data from a variety of sources, ranging from ReCaptcha to scanned images from Google Books.
 |
| Left: Image with bounding box around recognized text. The raw OCR output from this image reads, “Cise is beauti640”. Right: By applying Knowledge Graph in addition to context from nearby words, Lens in Google Go recognizes the words, “life is beautiful”. |
Understanding Structure
Once the individual words have been recognized, Lens must determine how to fit them together. The text that people come across in the real world is laid out in many different ways. A newspaper, for example, is laid out into columns, with headlines, article text, and advertisements. Meanwhile, a bus schedule, has one column for destinations and another with times. While understanding text structure comes very naturally to people, computers need to be taught how to comprehend it. Lens uses CNNs to detect coherent text blocks like columns, or text in a consistent style or color. And then, within each block, it uses signals like text-alignment, language, and the geometric relationship of the paragraphs to determine their final reading order.
One of the other challenges in detecting document structure is that people take pictures of text from different angles, often with a warped perspective. This means we cannot revert to off-the-shelf detectors that rely on axis aligned boxes, but must generalize our systems to be able to deal with homographic distortions.
 |
| Paragraph segmentation on the front page of a newspaper. Notice how “News Analysis”, which is embedded in the middle of a column, has been identified separately due to its distinct style features. |
Translations in Context
To provide users with the most helpful information, translations must be both accurate and contextual. Lens uses Google Translate’s neural machine translation (NMT) algorithms, to translate entire sentences at a time, rather than going word-by-word, in order to preserve proper grammar and diction.
For the translation to be most useful, it needs to be placed in the context of the original text. For example, when translating instructions on an ATM, it is important to know which buttons correspond to which instructions. Part of the challenge is accounting for the fact that the translated text can be much shorter or longer than the original. For example, German sentences tend to be longer than English ones. To accomplish this seamless overlay, Lens redistributes the translation into lines of similar length, and chooses an appropriate font size to match. It also matches the color of the translation and its background with the original text through the use of a heuristic that assumes the background and the text differ in luminosity, and that the background takes up the majority of the space. This allows Lens to classify whether a pixel represents background or text, and then sample the average color from these two regions to ensure the translated text matches the original text.
Reading the Text Out Loud
The final challenge in delivering information in the most helpful way with Lens in Google Go is reading the text aloud. High-fidelity audio is generated using Google Text-to-Speech (TTS), a service that applies machine learning to disambiguate and detected entities such as dates, phone numbers and addresses, and uses that to generate realistic speech based on DeepMind’s WaveNet.
These reading features become more contextual and useful when they are paired with display. Lens utilizes timing annotations from the TTS service that mark the beginning of each word in order to highlight each word on screen as it’s being read, similar to a karaoke machine. Say for example, a user takes a picture of an ATM screen with different labels next to different buttons. This karaoke effect allows users to know which label applies to which button. It may also help users learn how to pronounce the words being translated.
Looking Ahead
Taken together, it is our hope that these features will have a positive impact on the day-to-day lives of millions of people. Moving forward, we will continue to work on further updates to these reading features to make the OCR more precise, including improvements to text structure understanding (e.g. multi-column text) and recognition of Indic scripts. As we address these text challenges, we continue to look for new ways that the combination of machine learning and the smartphone camera can help people as they go about their lives.

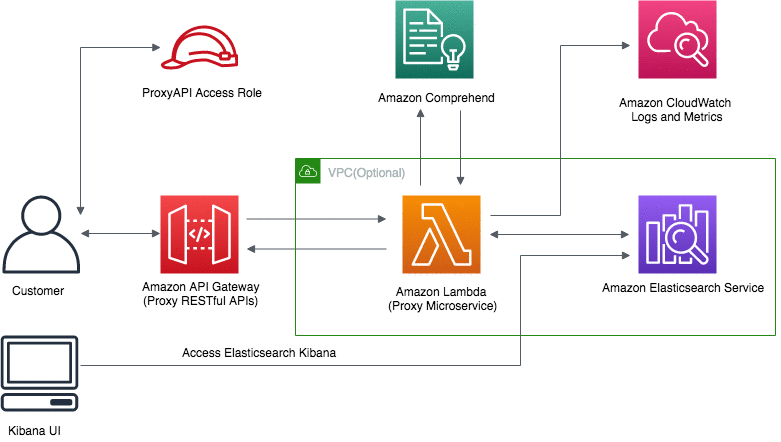
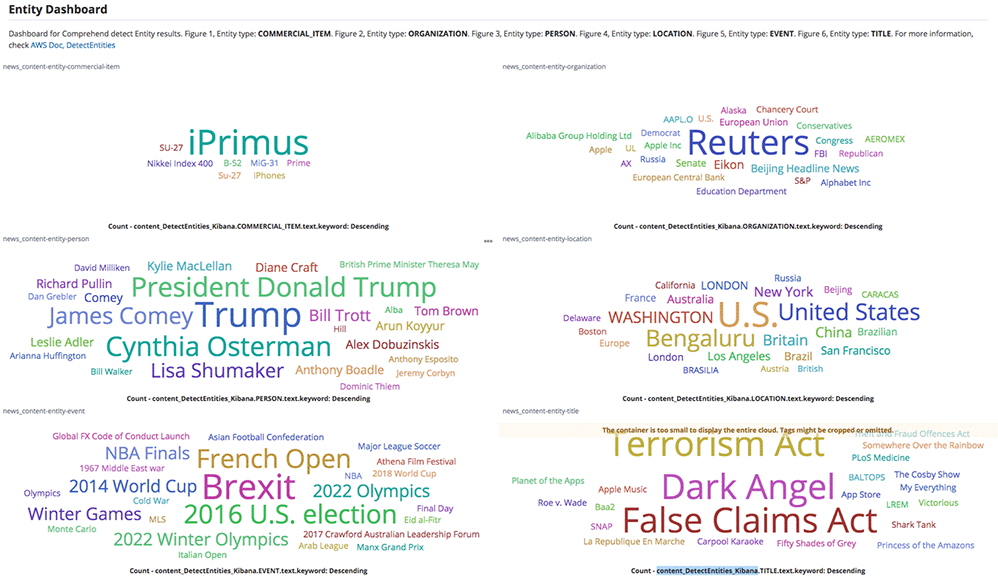
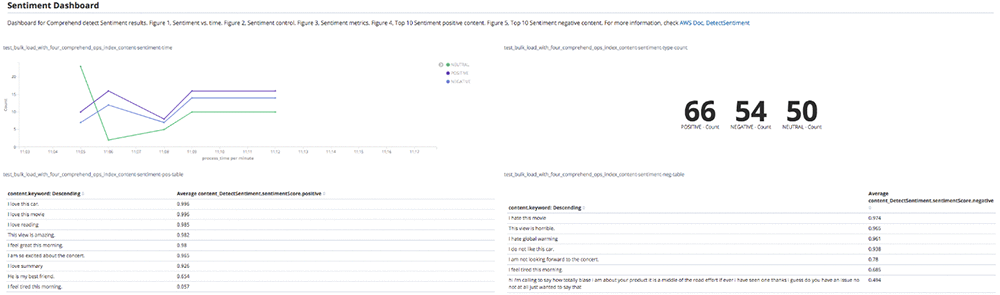
 Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.
Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.




![[P] Realtime Stereo Vision (toy project)](https://b.thumbs.redditmedia.com/gW4Mc2DM5PAL4-P2_JA8YIfW5Itewr2rh34i1GMPVdc.jpg "[P] Realtime Stereo Vision (toy project)")
{kind=link}