I have heard that Reinforcement Learning (RL) has several problems for use in real-life problems.
📷 alexirpan.com
June 24, 2018 note: If you want to cite an example from the post, please cite the paper which that example came from. If you want to cite the post as a whole, you can use the following BibTeX:
I understand that the problem with RL is that it is appropriate when the environment is constantly receiving information in real-time (like real-time games or driving a car) but not when the environment consists of several features. And in many real-world problems, the environment consists of several features (like turn-based games).
So, as I understand it, there’s a lack of ML models about which action to choose in the simple environment to achieve a score as high as possible. It is difficult to solve simply by classification or regression.
The idea I am thinking of is this:
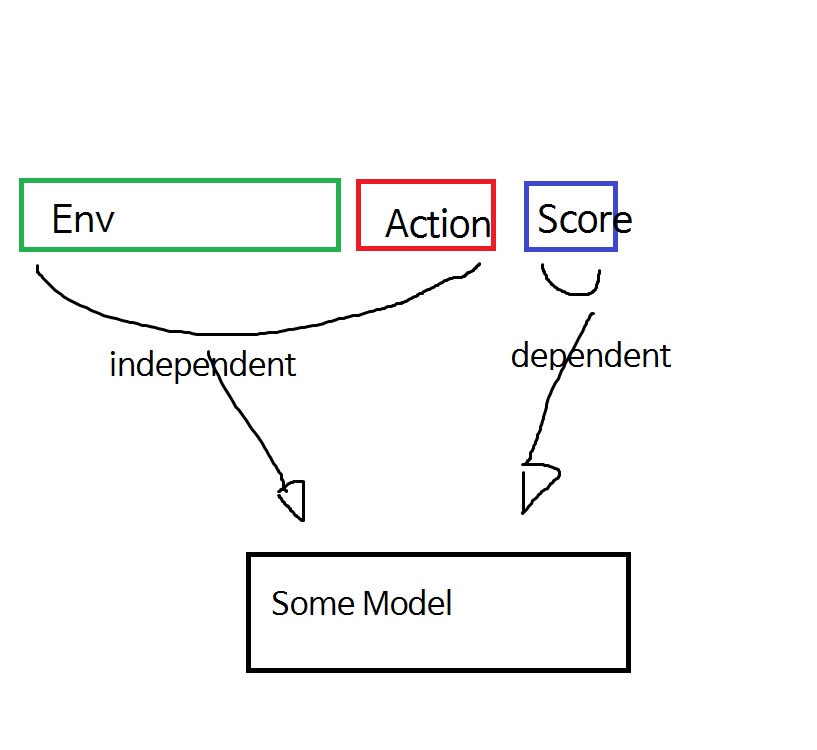
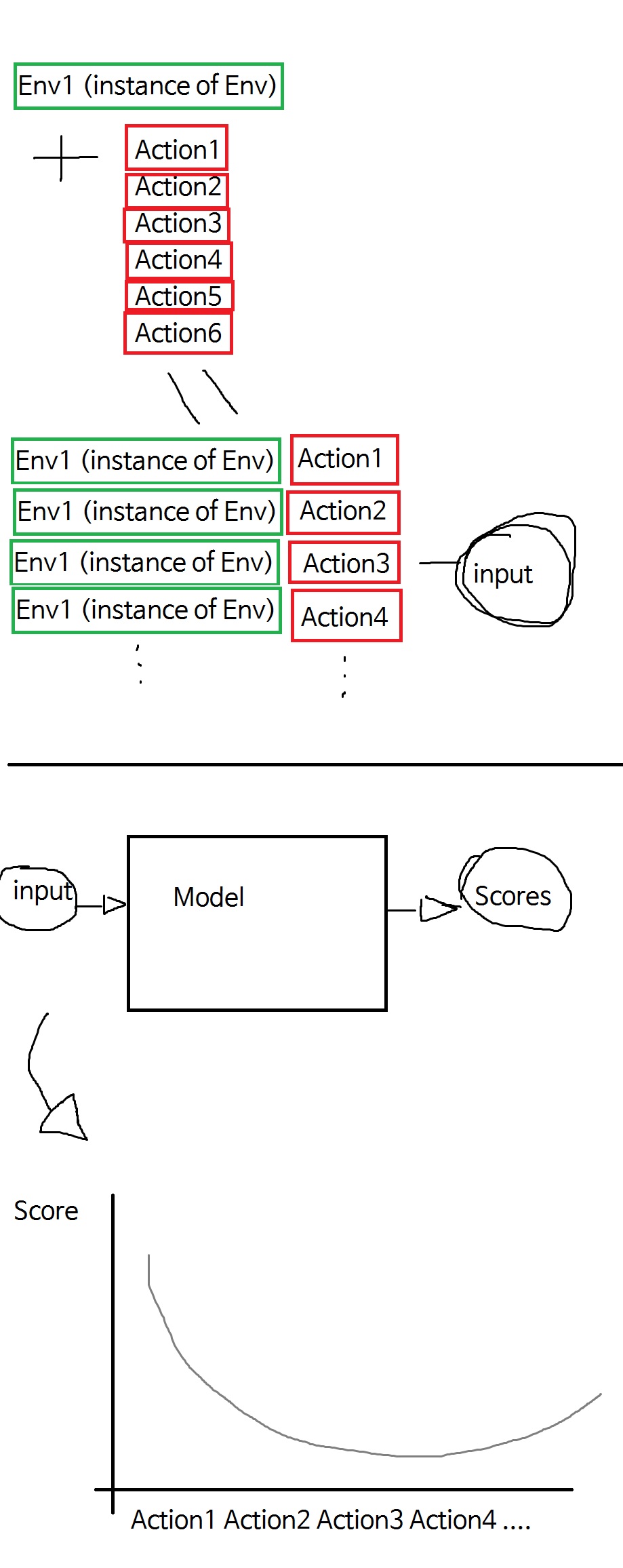
First, I want to select an action with only ML models for tabular data. So use tabular as the data. One row is one case, specific columns are Environment values, specific columns are Action values, and specific columns are Score.
And, Env + Action is used as a dependent value and Score is independent.
And get some model.
📷1.jpg817×750 42.7 KB
And when there is a value for Env, append all combinations of actions into tabular data. then use them as input to predict the score.
Then you get the score value according to the combination of actions. Select the value of the Action whose score is the highest.
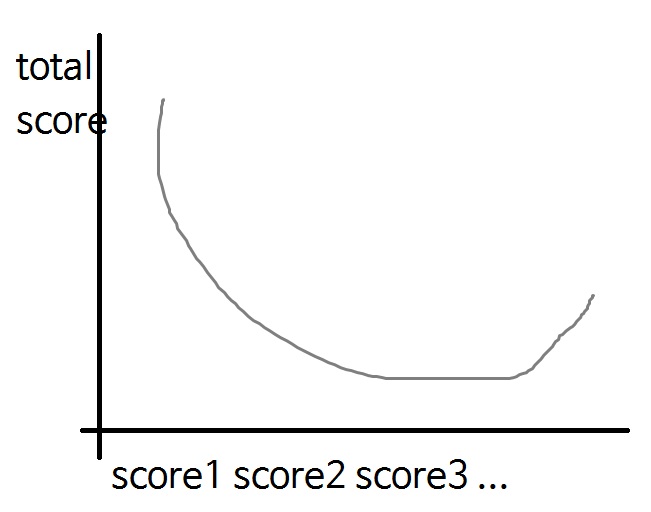
Since the value of Score according to Action is not a real one but a prediction, it may be necessary to select not the global minimum but the section with the most stable slope or the like. Came up with Recalled how to pick LR from a graph in LR Finder. Bayesian optimization can also be used to select the Action values to test. Or use sort of variance. Whatever.
📷2.jpg919×2312 189 KB
And it can also be used to set what is good scores. In other words, When there is a stage, it can decide which score is the best way to get a high total score, in the same way (probably the results obtained so far from the previous stage can be the environment).
That way, if you have a range of target scores, you can choose an Action that will give you that score.
📷3.jpg651×512 23.6 KB
Another consideration here is that Env values are often sequential data. You may need to make the sequential process accordingly. One idea is this: for categorical: Some idea for sequential data
And in the case of numeric + sequential, I may need to use recursion and Deep Learning for tabular data together.
Please check if this idea is already obsolete, typical or absurd! If it looks ok, I’ll dig it.
{kind=link}
{kind=link}
{kind=link}