Author: torontoai
[D] Best approaches for semi-supervised learning and learning with low quality labels.
I am starting work on an area where data is abundant but, labelling is almost impossible. The only viable labelling approach I can employ is to use manually defined thresholds to generate labels algorithmically. I think I will have to look into techniques that try to achieve superhuman accuracy, since my model should outperform the labelling algorithm. Anyone have any idea of what to do?
I have looked into pseudo-labelling but I am not sure how useful it will be in this context. It deals with the case of small amount of well labelled data and large amount of unlabelled data. My case is large amount of badly labelled data.
EDIT: Some extra information
The number of classes, is up to me to decide. It is a regression problem where the target is discretized according to manually defined thresholds(ordinal classification). By algorithmically labelling I mean that I can apply some mathematical manipulation to the data and generate labels. These labels won’t be too accurate mainly because the math formulas don’t take into account all the features nor the correlation among features. By badly labelled I mean mistaken labels.
submitted by /u/Atom_101
[link] [comments]
[D] AI for Autochess games (Team Fight Tactics)
Dear all,
sorry in advance if this is the wrong subreddit for this kind of question.
So with the recent rise of autobattlers, I wanted to create a basic AI for TeamFightTactics as a side-project.
For everyone that does not know the concept of these, I’ll try to summarize it quickly:
You are randomly offered champions from a fixed pool that you can buy, you can place a limited number of champions on the board (and keep some on the bench) and then they fight against the team of other players. Their strength is defined by synergies, their level and the items you obtain throughout the game.
Steps I would take:
- Data retrieval: Since we cannot access the raw data, i.e. which player has which champ, we have to extract this data from screenshots of their boards. My first intuition would be to use object detection such as YOLO, however since charachters/items always look the same, there could be an easier solution.
- Strategy: This is the harder part – as we cannot play games against ourselves I feel like deep learning cannot be applied here, any suggestions would be highly appreciated.
Thanks a lot for your time!
submitted by /u/MrLemmingv2
[link] [comments]
[D] Is transfer learning still worth entering into as a researcher?
I’m more interested in the theory behind transfer learning, so is the field dying down? Are a lot of the major problems solved? Just curios what others think here.
submitted by /u/Minimum_Zucchini
[link] [comments]
[D] Why is the L2 distance used for reconstruction loss in this VAE?
I was looking at the world models paper and saw that they use the L2 distance as reconstruction loss in their variational auto-encoder. All VAEs I’ve seen so far have used the cross entropy loss, so why L2?
submitted by /u/samuelknoche
[link] [comments]
[D] Tips on improving random forest predictive accuracy when # of features is really low?
Working on a random forest predictive model with a continuous response variable and two continuous features. Normally when I do RF projects I use some sort of feature selection method to choose which features to use. Then I fit the RF model onto those features. Then to test accuracy / related metrics I use cross validation, confusion matrices, etc.
However in this case I only have two given features. I don’t want to just literally run a RF model on those two features as my whole entire project. I’m thinking gradient boosting is what I should learn? Also I think I should play around with the number of estimators and depth of the RF. I’m using sklearn in Python if that helps.
Any other suggestions? Obviously this type of problem/challenge is an unexplored area for me, so looking for best practices on how to add to my data science toolkit. Thanks!
submitted by /u/truryce
[link] [comments]
[D] Scanning books
Hello all,
Firmware engineer dipping their toes into the vast world of machine learning here. A friend works at our local library and was telling me about how the worst part of her job is when people put backs on the shelves themselves as they often do it wrong. So she has to scan each row going book by book and find books out of order. It’s time consuming and mentally draining to do for a long period of time. I wonder if it would be possible to make an app on her phone that would read the white dewey decimal system tags on the spines of the books and figure out if a book was out of order? I’ve taken some sample footage and noticed a few problems:
– Passing the camera over rows tends to induce some blur and while I think it could reduced or unblurred, it does make it hard.
– Some books are too thin for the whole tag and it’s impossible to read (I don’t know a way to handle that)
Here’s what I’m currently thinking, tell me if I’m totally off track.
- Process image and reduce blur and adjust to high constrast
- Cut out “labels” on the books and create small B&W images with the source location of where they came from.
- Rotate the label as needed (sometimes they are at a 90 degree angle)
- OCR the label and categorize it into the dewey
Is this feasible with some degree of accuracy? Ultimately, I’d just want to highlight the book that’s out of order in red. I don’t need to do anything more complicated.
submitted by /u/matttron3000
[link] [comments]
Senior Data Scientist – Fraud Analytics – BMO Financial Group – Toronto, ON
From BMO Financial Group – Tue, 10 Sep 2019 02:43:28 GMT – View all Toronto, ON jobs
[D] Worth Attending Conference Workshops?
I am a student that will be attending a conference for the first time, specifically EMNLP 2019. Currently debating between just going for the main conference or a couple days earlier to also attend the workshops. Not sure if it’s worth the extra costs though, the scholarship application only covers the costs for the main conference.
submitted by /u/AnonMLstudent
[link] [comments]
Analysis of Data Science Interview Questions
Breaking down data science interview questions by category
tl;dr: Unless the data science role is nuanced, most data science roles require fundamental knowledge about the basics of data science. (SQL, Coding, Probability and Stats, Data Analysis)
We analyzed hundreds of data science interview questions to find trends, patterns and topics that are the core of a data science interview.
At a high level, we divided these questions into different categories. We added a weight to each category. Weight of a category is simply the number of times we found a question occurring or repeating in the bucket from a random corpus of 100 questions.
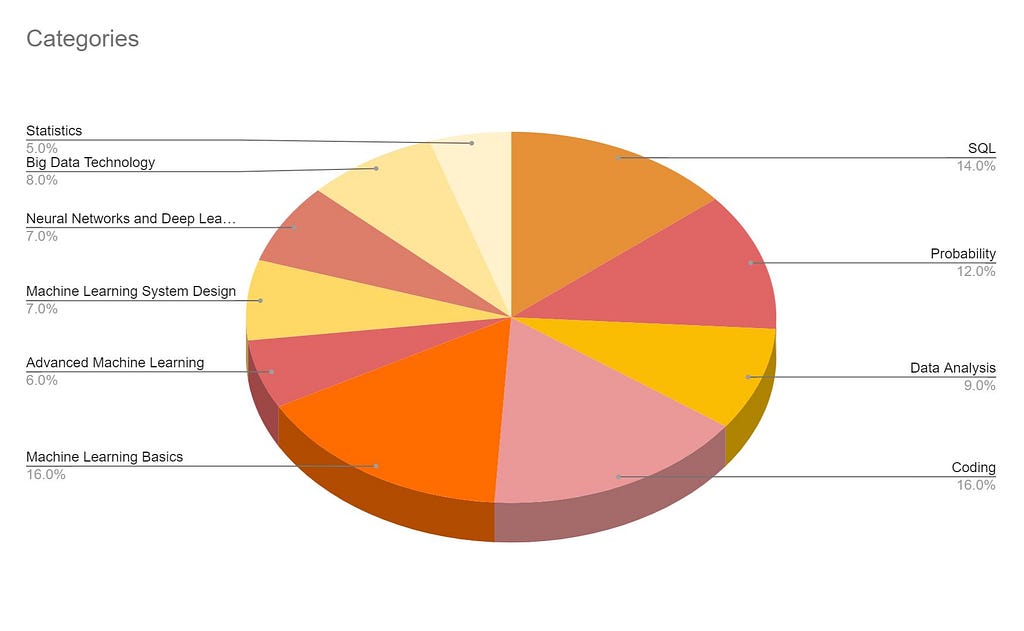
From the pie chart above, categories like SQL, coding are non ambiguous. Machine learning basics consists of Linear/Logistic regression and related ML algorithms. Advanced ML consists of comparisons between multiple approaches, algorithms and nuanced techniques. Big Data technology includes big data concepts such as Hadoop, Spark and may include the infrastructure side/data engineering/deployment side of data science models. In essence, data science fundamentals are asked 70% of the time in a data science interview.
While SQL and coding based questions might be part of the initial online assessment, data analysis questions tend to be a take-home assessment. The remaining categories are usually covered during the phone/in-person interview and vary based on the role, company, years of experience and team composition.
Considering all this data, we designed a data science interview course to help people Ace Data Science Interviews. All the categories mentioned above will be covered in this course. The current cohort starts September 16, 2019. It will be a small group of 15 people. Sign up here!
Subscribe to the Acing AI/Data Science Newsletter. It is FREE!
Analysis of Data Science Interview Questions was originally published in Acing AI on Medium, where people are continuing the conversation by highlighting and responding to this story.