BERT Does Europe: AI Language Model Learns German, Swedish
BERT is at work in Europe, tackling natural-language processing jobs in multiple industries and languages with help from NVIDIA’s products and partners.
The AI model formally known as Bidirectional Encoder Representations from Transformers debuted just last year as a state-of-the-art approach to machine learning for text. Though new, BERT is already finding use in avionics, finance, semiconductor and telecom companies on the continent, said developers optimizing it for German and Swedish.
“There are so many use cases for BERT because text is one of the most common data types companies have,” said Anders Arpteg, head of research for Peltarion, a Stockholm-based developer that aims to make the latest AI techniques such as BERT inexpensive and easy for companies to adopt.
Natural-language processing will outpace today’s AI work in computer vision because “text has way more apps than images — we started our company on that hypothesis,” said Milos Rusic, chief executive of deepset in Berlin. He called BERT “a revolution, a milestone we bet on.”
Deepset is working with PricewaterhouseCoopers to create a system that uses BERT to help strategists at a chip maker query piles of annual reports and market data for key insights. In another project, a manufacturing company is using NLP to search technical documents to speed maintenance of their products and predict needed repairs.
Peltarion, a member of NVIDIA’s Inception program that nurtures startups with access to its technology and ecosystem, packed support for BERT into its tools in November. It is already using NLP to help a large telecom company automate parts of its process for responding to product and service requests. And it’s using the technology to let a large market research company more easily query its database of surveys.
Work in Localization
Peltarion is collaborating with three other organizations on a three-year, government-backed project to optimize BERT for Swedish. Interestingly, a new model from Facebook called XLM-R suggests training on multiple languages at once could be more effective than optimizing for just one.
“In our initial results, XLM-R, which Facebook trained on 100 languages at once, outperformed a vanilla version of BERT trained for Swedish by a significant amount,” said Arpteg, whose team is preparing a paper on their analysis.
Nevertheless, the group hopes to have before summer a first version of a Swedish BERT model that performs really well, said Arpteg, who headed up an AI research group at Spotify before joining Peltarion three years ago.
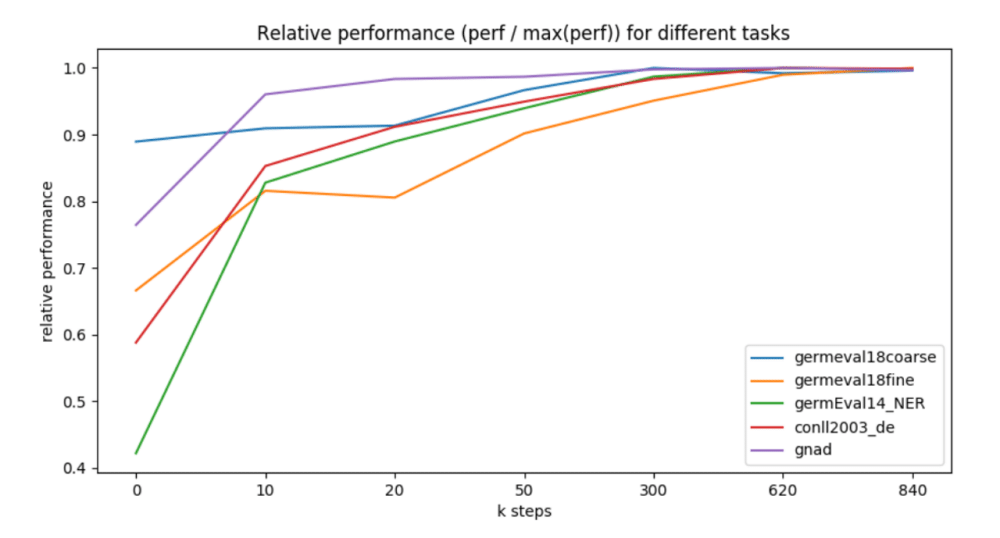
In June, deepset released as open source a version of BERT optimized for German. Although its performance is only a couple percentage points ahead of the original model, two winners in an annual NLP competition in Germany used the deepset model.
Right Tool for the Job
BERT also benefits from optimizations for specific tasks such as text classification, question answering and sentiment analysis, said Arpteg. Peltarion researchers plans to publish in 2020 results of an analysis of gains from tuning BERT for areas with their own vocabularies such as medicine and legal.
The question-answering task has become so strategic for deepset it created Haystack, a version of its FARM transfer-learning framework to handle the job.
In hardware, the latest NVIDIA GPUs are among the favorite tools both companies use to tame big NLP models. That’s not surprising given NVIDIA recently broke records lowering BERT training time.
“The vanilla BERT has 100 million parameters and XML-R has 270 million,” said Arpteg, whose team recently purchased systems using NVIDIA Quadro and TITAN GPUs with up to 48GB of memory. It also has access to NVIDIA DGX-1 servers because “for training language models from scratch, we need these super-fast systems,” he said.
More memory is better, said Rusic, whose German BERT models weigh in at 400MB. Deepset taps into NVIDIA V100 Tensor Core 100 GPUs on cloud services and uses another NVIDIA GPU locally.
The post BERT Does Europe: AI Language Model Learns German, Swedish appeared first on The Official NVIDIA Blog.