Exploring images on social media using Amazon Rekognition and Amazon Athena
If you’re like most companies, you wish to better understand your customers and your brand image. You’d like to track the success of your marketing campaigns, and the topics of interest—or frustration—for your customers. Social media promises to be a rich source of this kind of information, and many companies are beginning to collect, aggregate, and analyze the information from platforms like Twitter.
However, more and more social media conversations center around images and video; on one recent project, approximately 30% of all tweets collected included one or more images. These images contain relevant information that is not readily accessible without analysis.
| About this blog post | |
| Time to complete | 1 hour |
| Cost to complete | ~ $5 (at publication time, depending on terms used) |
| Learning level | Intermediate (200) |
| AWS services | Amazon Rekognition Amazon Athena Amazon Kinesis Data Firehose Amazon S3 AWS Lambda |
Overview of solution
The following diagram shows the solution components and how the images and extracted data flows through them.

These components are available through an AWS CloudFormation template.
- Twitter Search API collects Tweets.
- Amazon Kinesis Data Firehose dispatches the tweets to store in an Amazon S3
- The creation of an S3 object in the designated bucket folder triggers a Lambda function.
- The Lambda sends each tweet text to Amazon Comprehend to detect sentiment (positive or negative), entity (real-world objects such as people, places, and commercial items), and to precise references to measures such as dates and quantities. For more information, see DetectSentiment and DetectEntity in the Amazon Comprehend Developer Guide.
- The Lambda checks each tweet for media of type ‘
photo’ in the tweet’sextended_entitiesIf the photo has either a .JPG or .PNG extension, the Lambda calls the following Amazon Rekognition APIs for each image:Detect_labels, to identify objects such asPerson,Pedestrian,Vehicle, andCarin the image.Detect_moderation_labels, to determine if an image or stored video contains unsafe content, such as explicit adult content or violent content.- If the
detect_labelsAPI returns aTextlabel,detect_textextracts lines, words, or letters found in the image. - If the
detect_labelsAPI returns aPersonlabel, the Lambda calls the following:detect_faces, to detect faces and analyze them for features such as sunglasses, beards, and mustaches.recognize_celebrities, to detect as many celebrities as possible in different settings, cosmetic makeup, and other conditions.
The results from all calls for a single image are combined into a single JSON record. For more information about these APIs, see Actions in the Amazon Rekognition Developer Guide.
- The results of the Lambda go to Kinesis Data Firehose. Kinesis Data Firehose batches the records and writes them to a designated S3 bucket and folder.
- You can use Amazon Athena to build tables and views over the S3 datasets, then catalogue these definitions in the AWS Glue Data Catalog. The table and view definitions make it much easier to query the complex JSON objects contained in these S3 datasets.
- After the processed tweets land in S3, you can query the data with Athena.
- You can also use Amazon QuickSight to visualize the data, or Amazon SageMaker or Amazon EMR to process the data further. For more information, see Build a social media dashboard using machine learning and BI services. This post uses Athena.
Prerequisites
This walkthrough has the following prerequisites:
- An AWS account.
- An app on Twitter. To create an app, see the Apps section of the Twitter Development website.
- Create a consumer key (API key), consumer secret key (API secret), access token, and access token secret. The solution uses them as parameters in the AWS CloudFormation stack.
Walkthrough
This post walks you through the following steps:
- Launching the provided AWS CloudFormation template and collecting tweets.
- Checking that the stack created datasets on S3.
- Creating views over the datasets using Athena.
- Exploring the data.
S3 stores the raw tweets and the Amazon Comprehend and Amazon Rekognition outputs in JSON format. You can use Athena table and view definitions to flatten the complex JSON produced and extract your desired fields. This approach makes the data easier to access and understand.
Launching the AWS CloudFormation template
This post provides an AWS CloudFormation template that creates all the ingestion components that appear in the previous diagram, except for the S3 notification for Lambda (the dotted blue line in the diagram).
- In the AWS Management Console, launch the AWS CloudFormation Template.

This launches the AWS CloudFormation stack automatically into the
us-east-1Region. - In the post Build a social media dashboard using machine learning and BI services, in the section “Build this architecture yourself,” follow the steps outlined, with the following changes:
- Use the Launch Stack link from this post.
- If the AWS Glue database socialanalyticsblog already exists (for example, if you completed the walkthrough from the previous post), change the name of the database when launching the AWS CloudFormation stack, and use the new database name for the rest of this solution.
- For Twitter Languages, use ‘en’ (English) only. This post removed the Amazon Comprehend Translate capability for simplicity and to reduce cost.
- Skip the section “Setting up S3 Notification – Call Amazon Translate/Comprehend from new Tweets.” This occurs automatically when launching the AWS CloudFormation stack by the “Add Trigger” Lambda function.
- Stop at the section “Create the Athena Tables” and complete the following instructions in this post instead.
You can modify which terms to pull from the Twitter streaming API to be those relevant for your company and your customers. This post used several Amazon-related terms.
This implementation makes two Amazon Comprehend calls and up to five Amazon Rekognition calls per tweet. The cost of running this implementation is directly proportional to the number of tweets you collect. If you’d like to modify the terms to something that may retrieve tens or hundreds of tweets a second, for efficiency and for cost management, consider performing batch calls or using AWS Glue with triggers to perform batch processing versus stream processing.
Checking the S3 files
After the stack has been running for approximately five minutes, datasets start appearing in the S3 bucket (rTweetsBucket) that the AWS CloudFormation template created. Each dataset is represented as the following files sitting in a separate directory in S3:
- Raw – The raw tweets as received from Twitter.
- Media – The output from calling the Amazon Rekognition APIs.
- Entities – The results of Amazon Comprehend entity analysis.
- Sentiment – The results of Amazon Comprehend sentiment analysis.
See the following screenshot of the directory:
For the entity and sentiment tables, see Build a social media dashboard using machine learning and BI services.
When you have enough data to explore (which depends on how popular your selected terms are and how frequently they have images), you can stop the Twitter stream producer, and stop or terminate the Amazon EC2 instance. This stops your charges from Amazon Comprehend, Amazon Rekognition, and EC2.
Creating the Athena views
The next step is manually creating the Athena database and tables. For more information, see Getting Started in the Athena User Guide.
This is a great place to use AWS Glue crawling features in your data lake architectures. The crawlers automatically discover the data format and data types of your different datasets that live in S3 (as well as relational databases and data warehouses). For more information, see Defining Crawlers.
- In the Athena console, in Query Editor, access the file sql.The AWS CloudFormation stack created the database and tables for you automatically.
- Load the
view createstatements into the Athena query editor one by one, and execute.This step creates the views over the tables.
Compared to the prior post, the media_rekognition table and the views are new. The tweets table has a new extended_entities column for images and video metadata. The definitions of the other tables remain the same.
Your Athena database should look similar to the following screenshot. There are four tables, one for each of the datasets on S3. There are also three views, combining and exposing details from the media_rekognition table:
Celeb_viewfocuses on the results of therecognize_celebritiesAPIMedia_image_labels_queryfocuses on the results from thedetect_labelsAPIMedia_image_labels_face_queryfocuses on the results from thedetect_facesAPI

Explore the table and view definitions. The JSON objects are complex, and these definitions show a variety of uses for querying nested objects and arrays with complex types. Now many of the queries can be relatively simple, thanks to the underlying table and view definitions encapsulating the complexity of the underlying JSON. For more information, see Querying Arrays with Complex Types and Nested Structures.
Exploring the results
This section describes three use cases for this data and provides SQL to extract similar data. Because your search terms and timeframe are different from those in this post, your results will differ. This post used a set of Amazon-related terms. The tweet collector ran for approximately six weeks and collected approximately 9.5M tweets. From the tweets, there were approximately 0.5M photos, about 5% of the tweets. This number is low compared to some other sets of business-related search terms, where approximately 30% of tweets contained photos.
This post reviews for four image use cases:
- Buzz
- Labels and faces
- Suspect content
- Exploring celebrities
Buzz
Major topic areas represented by the links associated with the tweets often provide a good complement to the tweet language content topics surfaced via natural language processing. For more information, see Build a social media dashboard using machine learning and BI services.
The first query is which websites the tweets linked to. The following code shows the top domain names linked from the tweets:
The following screenshot shows the top 10 domains returned:

Links to Amazon websites are frequent, and several different properties are named, such as amazon.com, amazon.co.uk, and goodreads.com.
Further exploration shows that many of these links are to product pages on the Amazon website. It’s easy to recognize these links because they have /dp/ (for detail page) in the link. You can get a list of those links, the images they contain, and the first line of text in the image (if there is any), with the following query:
The following screenshot shows some of the records returned by this query. The first_line column shows the results returned by the detect_text API for the image URL in the media_url column.
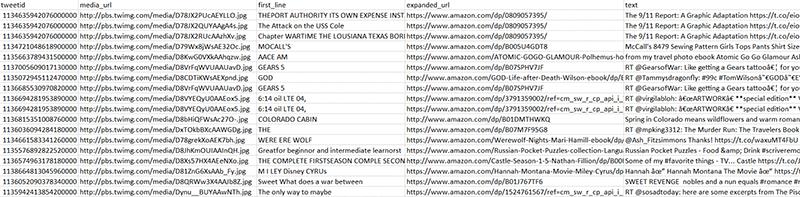
Many of the images do contain text. You can also identify the products the tweet linked to; many of the tweets are product advertisements by sellers, using images that relate directly to their product.
Labels and faces
You can also get a sense of the visual content of the images by looking at the results of calling the Amazon Rekognition detect_labels API. The following query finds the most common objects found in the photos:
The following screenshot shows the results of that request. The most popular label by far is Human or Person, with Text, Advertisement, and Poster coming soon after. Novel is further down the list. This result reflects the most popular product being tweeted about on the Amazon website—books.

You can explore the faces further by looking at the results of the detect_faces API. That API returns details for each face in the image, including the gender, age range, face position, whether the person is wearing sunglasses or has a mustache, and the expression(s) on their face. Each of these features also has a confidence level associated with it. For more information, see DetectFaces in the Amazon Rekognition Developer Guide.
The view media_image_labels_face_query unnests many of these features from the complex JSON object returned by the API call, making the fields easy to access.
You can explore the view definition for media_image_labels_face_query, including the use of the reduce operator on the array of (emotion,confidence) pairs that Amazon Rekognition returned to identify and return the expression category with the highest confidence score associated with it, and associate the name top_emotion with it. See the following code:
You can then use the exposed field, top_emotion. See the following code:
The following screenshot shows columns from the middle of this extensive query, including glasses, age range, and where the edges of this face are positioned. This last detail is useful when multiple faces are present in a single image, to distinguish between the faces.

You can look at the top expressions found on these faces with the following code:
The following screenshot of the query results shows that CALM is the clear winner, followed by HAPPY. Oddly, there are far fewer confused than disgusted expressions.

Suspect content
A topic of frequent concern is whether there is content in the tweets, or the associated images, that should be moderated. One of the Amazon Rekognition APIs called by the Lambda for each image is moderation_labels, which returns labels denoting the category of content found, if any. For more information, see Detecting Unsafe Content.
The following code finds tweets with suspect images. Twitter also provides a possibly_sensitive flag based solely on the tweet text.
The following screenshot shows the first few results. For many of these entries, the tweet text or the image may contain sensitive content, but not necessarily both. Including both criteria provides additional safety.

Note the use of the transform construct in the preceding query to map over the JSON array of moderation labels that Amazon Rekognition returned. This construct lets you transform the original content of the moderationlabels object (in the following array) into a list containing only the name field:
You can filter this query to focus on specific types of unsafe content by filtering on specific moderation labels. For more information, see Detecting Unsafe Content.
A lot of these tweets have product links embedded in the URL. URLs for the Amazon.com website have a pattern to them: any URL with /dp/ in it is a link to a product page. You could use that to identify the products that may have explicit content associated with them.
Exploring celebrities
One of the Amazon Rekognition APIs that the Lambda called for each image was recognize_celebrity. For more information, see Recognizing Celebrities in an Image.
The following code helps determine which celebrities appear most frequently in the dataset:
The result counts instances of celebrity recognitions, and counts an image with multiple celebrities multiple times.
For example, assume there is a celebrity with the label JohnDoe. To explore their images further, use the following query. This query finds the images associated with tweets in which JohnDoe appeared in the text or the image.
The recognize_celebrity API matches each image to the closest-appearing celebrity. It returns that celebrity’s name and related information, along with a confidence score. At times, the result can be misleading; for example, if a face is turned away, or when the person is wearing sunglasses, they can be difficult to identify correctly. In other instances, the API may choose an image model because of their similarity to a celebrity. It may be beneficial to combine this query with logic using the face_details response, to check for glasses or for face position.
Cleaning up
To avoid incurring future charges, delete the AWS CloudFormation stack, and the contents of the S3 bucket created.
Conclusion
This post showed how to start exploring what your customers are saying about you on social media using images. The queries in this post are just the beginning of what’s possible. To better understand the totality of the conversations your customers are having, you can combine the capabilities from this post with the results of running natural language processing against the tweets.
This entire processing, analytics, and machine learning pipeline—starting with Kinesis Data Firehose, using Amazon Comprehend to perform sentiment analysis, Amazon Rekognition to analyze photographs, and Athena to query the data—is possible without spinning up any servers.
This post added advanced machine learning (ML) services to the Twitter collection pipeline, through some simple calls within Lambda. The solution also saved all the data to S3 and demonstrated how to query the complex JSON objects using some elegant SQL constructs. You could do further analytics on the data using Amazon EMR, Amazon SageMaker, Amazon ES, or other AWS services. You are limited only by your imagination.
About the authors
 Dr. Veronika Megler is Principal Consultant, Data Science, Big Data & Analytics, for AWS Professional Services. She holds a PhD in Computer Science, with a focus on scientific data search. She specializes in technology adoption, helping companies use new technologies to solve new problems and to solve old problems more efficiently and effectively.
Dr. Veronika Megler is Principal Consultant, Data Science, Big Data & Analytics, for AWS Professional Services. She holds a PhD in Computer Science, with a focus on scientific data search. She specializes in technology adoption, helping companies use new technologies to solve new problems and to solve old problems more efficiently and effectively.
 Chris Ghyzel is a Data Engineer for AWS Professional Services. Currently, he is working with customers to integrate machine learning solutions on AWS into their production pipelines.
Chris Ghyzel is a Data Engineer for AWS Professional Services. Currently, he is working with customers to integrate machine learning solutions on AWS into their production pipelines.