End-to-End Deep Reinforcement Learning without Reward Engineering
Communicating the goal of a task to another person is easy: we can use language, show them an image of the desired outcome, point them to a how-to video, or use some combination of all of these. On the other hand, specifying a task to a robot for reinforcement learning requires substantial effort. Most prior work that has applied deep reinforcement learning to real robots makes uses of specialized sensors to obtain rewards or studies tasks where the robot’s internal sensors can be used to measure reward. For example, using thermal cameras for tracking fluids, or purpose-built computer vision systems for tracking objects. Since such instrumentation needs to be done for any new task that we may wish to learn, it poses a significant bottleneck to widespread adoption of reinforcement learning for robotics, and precludes the use of these methods directly in open-world environments that lack this instrumentation.
We have developed an end-to-end method that allows robots to learn from a modest number of images that depict successful completion of a task, without any manual reward engineering. The robot initiates learning from this information alone (around 80 images), and occasionally queries a user for additional labels. In these queries, the robot shows the user an image and asks for a label to determine whether that image represents successful completion of the task or not. We require a small number of such queries (around 25-75), and using these queries, the robot is able to learn directly in the real world in 1-4 hours of interaction time, resulting in one of the most efficient real-world image-based robotic RL methods. We have open-sourced our implementation.



Our method allows us to solve a host of real world robotics problems from pixels in an end-to-end fashion without any hand-engineered reward functions.
Classifier-based rewards
While most prior work uses purpose-built systems for obtaining rewards to solve the task at hand, a simple alternative has been previously explored. We can specify the task using a set of goal images, and then train a classifier to distinguish between goal and non-goal images. The success probabilities from this classifier can then be used as reward for training an RL agent to achieve the goal.



It’s often straightforward to specify a task via example images. For examples, in the images above, the task could be pour this much wine in the glass, fold clothes like this, and set the table like this.
Problem with classifiers
While classifiers are an intuitive and straightforward solution to specify tasks for RL agents in the real world, they also pose a number of issues when applied to real-world problems. A user that is specifying a task with goal classifiers must provide not only positive examples for the task, but also negative examples. Moreover, this set of negative examples must be exhaustive and cover all parts of the space that the robot can potentially visit. If the set of negative examples is not exhaustive, then the RL algorithm can easily fool the classifier by finding situations that the classifier did not see during training. An example of this classifier exploitation problem can be seen below.
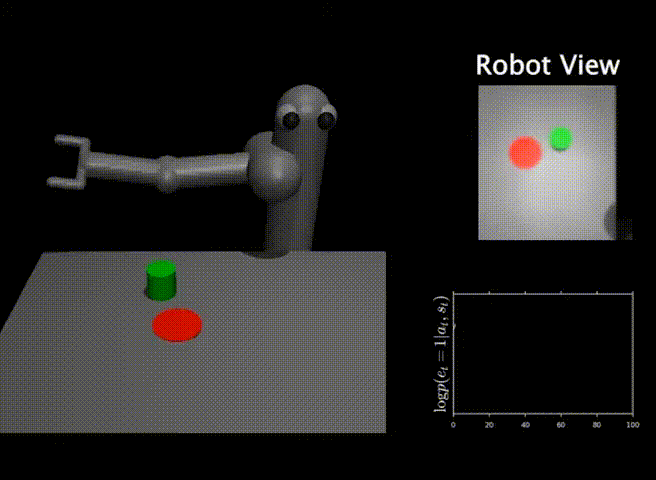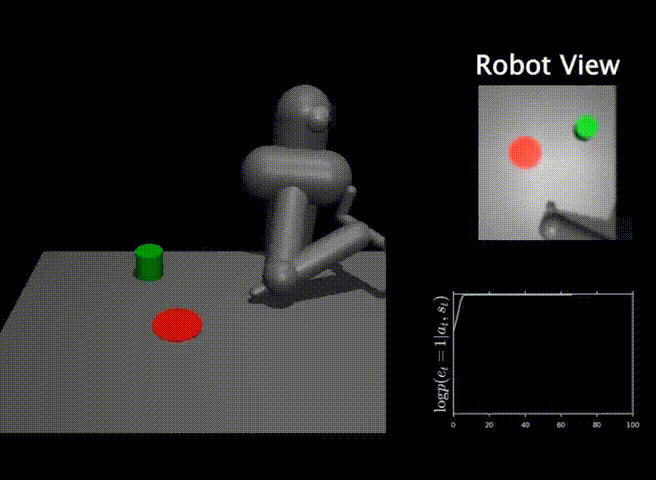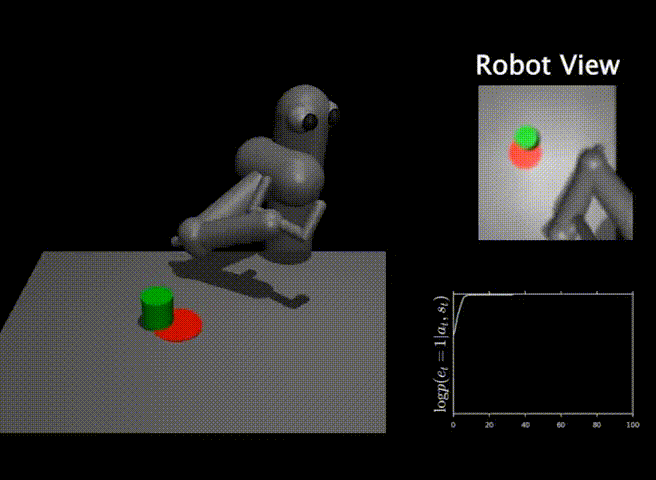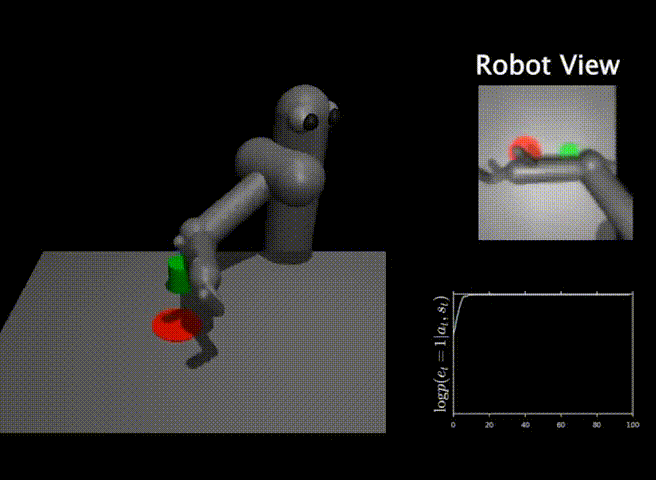
In this task, the goal is to push the green object onto the red marker. The robot is trained via RL using a classifier as a reward function. The success probability from the classifier is visualized with time in the lower right. As we see, while the classifier outputs a success probability of 1.0, the robot does not solve the task. The RL algorithm has managed to exploit the classifier by moving the robot arm in a peculiar way, since the classifier was not trained on this specific kind of negative examples.
Overcoming classifier exploitation
Our recent approach, which we call variational inverse control with events (VICE) seeks to solve this issue by instead mining the negative examples required by the classifier in an adversarial fashion. The method begins by randomly initializing the classifiers and the policy. It first fixes the classifier and updates the policy to maximize the reward. Then, it trains the classifier to distinguish between user-provided goal examples and samples collected by the policy. The RL algorithm then utilizes this updated classifier as reward for learning a policy to achieve the desired goal, and this alternating process continues until the samples collected by the policy are indistinguishable from the user-proved goal examples. This process resembles generative adversarial networks and is based on a form of inverse reinforcement learning, but in contrast to standard inverse reinforcement learning, it does not require example demonstrations – only example success images provided at the beginning of training for the classifier. VICE (as shown below) is effective at combating the exploitation problem faced by naive classifiers, and the user no longer needs to provide any negative examples at all.

We see that the success probabilities learned by the classifier correlate strongly with actual success, allowing the robot to learn a policy that successfully accomplishes the task.
Leveraging active learning
While VICE is capable of learning end-to-end policies for solving real world robotic tasks without any engineering for obtaining rewards, it does have a limitation: it needs thousands of positive examples provided upfront in order to learn, and this could be a burden on the human user. To combat this problem, we developed a new approach that enables the robot to query the user for labels, in addition to using a modest number of initially-provided goal examples. We refer to this approach as reinforcement learning with active goal queries (RAQ). In these active queries, the robot shows the user an image and asks for a label to determine whether the image represents successful completion of the task. While requesting labels for every single state would amount to asking the user to manually provide the reward signal, our method requires labels for only a tiny fraction of the images seen during training, making it an efficient and practical approach for learning skills without manually engineered rewards.

In this task, the goal is to place a book into any one of the empty slots in the bookshelf. This figure shows some example queries made by our algorithm. The algorithm has picked each of these images from the experience it collected while learning to solve the task (using probability estimates from the learned classifier), and the user provides a binary success/failure label for each of them.
The combined method, which we call VICE-RAQ, is able to solve real world robotics tasks with about 80 goal example images provided up front, followed by 25-75 active queries. We make use of the recently introduced soft actor-critic algorithm for policy optimization, and are able to solve tasks in about 1-4 hours of real world interaction time, which is much faster than prior work for a policy trained end-to-end on images.

Our method is able to learn the pushing task (where the goal is to push the mug onto the white coaster) in slightly over an hour of interaction time, and only requires for 25 queries. Even for the more complex bookshelf and draping tasks, our method requires under four hours of interaction time and less than 75 active queries.
Solving tasks involving deformable objects
Since we learn a reward function on pixels, we can solve tasks for which it would be difficult to manually specify a reward function. One of the tasks in our experiments is to drape a cloth over a box, which is essentially a miniaturized version of a tablecloth draping task. To succeed, the robot must drape the cloth smoothly, without crumpling it and without creating any wrinkles. We see that our method is able to successfully solve this task. To demonstrate the challenges associated with this task, we evaluate a method that only uses the robot’s end-effector position as observation and a hand-defined reward function on this observation (Euclidean distance to the goal). We observe that this baseline fails to achieve the objective of this task, as it simply moves the end effector in a straight line motion to the goal, while this task cannot be solved using any straight-line trajectory.

Left: resulting policy with a hand-defined reward on the gripper position. Right: resulting policy from a learned reward function on pixels.
Solving tasks with multiple goal conditions
Classifiers are more expressive than just goal images for describing a task, and this can best be seen in tasks for which there are multiple images that describe our goal. In the bookshelf task in our experiments, the goal is to insert a book into an empty slot on a bookshelf. The initial position of the arm holding the book is randomized, requiring the robot to succeed from any starting position. Crucially, the bookshelf has several open slots, which means that, from different starting positions, different slots may be preferred. Here, we see that our method learns a policy to insert the book in different slots in the bookshelf depending on where the book is at the start of a trajectory. The robot usually prefers to put the book in the nearest slot, since this maximizes the reward that it can obtain from the classifier.


Left: robot chooses to insert book in left slot. Right: robot chooses to insert book in the right slot.
Related Work
Several data-driven approaches have been proposed for the reward specification problem, and inverse reinforcement learning (IRL) is one of the more prominent frameworks in this setting. VICE is closely related to recent IRL methods like guided cost learning and adversarial inverse reinforcement learning. While these methods require trajectories of (state,action) pairs provided by a human expert, VICE only requires the final desired state, making it substantially easier to specify the task, and also making it possible for the reinforcement learning algorithm to discover novel ways to complete the task on its own (instead of simply mimicking the expert).
Our method is also related to generative adversarial networks. Techniques inspired by GANs have been applied to control problems, but these techniques also require expert trajectories similar to the IRL techniques mentioned before. Our method demonstrates that such adversarial learning frameworks can be extended to settings where we don’t have expert demonstrations, and only have examples of desired states that we would like to achieve.
End-to-end perception and control for robotics have gained prominence in the last few years, but initial approaches either required access to low-dimensional states (e.g. the positions of objects) at training time, or separately trained intermediate representations. More recent approaches are able to learn policies directly on pixels without using low-dimensional states during training, but still require instrumentation for obtaining rewards. Our method goes a step further – it learns both a policy as well as a reward function on pixels. This allows us to solve tasks for which rewards to would be otherwise hard to specify, such as the draping task.
Conclusion
By enabling robotic reinforcement learning without user-programmed reward functions or demonstrations, we believe that our approach represents a significant step towards making reinforcement learning a practical, automated, and readily usable tool for enabling versatile and capable robotic manipulation. By making it possible for robots to improve their skills directly in real-world environments, without any instrumentation or manual reward design, we believe that our method also represents a step toward enabling lifelong learning for robotic systems that learn directly “in the wild”. This capability can make it feasible in the future for robots to acquire broad and highly generalizable skill repertoires directly through interaction with the real world.
This post is based on the following papers:
- Avi Singh, Larry Yang, Kristian Hartikainen, Chelsea Finn, Sergey Levine
End-to-End Robotic Reinforcement Learning without Reward Engineering
Robotics: Science and Systems (RSS), 2019.
Project webpage
Open-source code - Justin Fu*, Avi Singh*, Dibya Ghosh, Larry Yang, Sergey Levine
Variational Inverse Control with Events: A General Framework for Data-Driven Reward Definition
Neural Information Processing Systems (NeurIPS), 2018.
Project webpage
Open-source code
I would like to thank Sergey Levine, Chelsea Finn and Kristian Hartikainen for their feedback while writing this blog post.