Simulated Policy Learning in Video Models
Deep reinforcement learning (RL) techniques can be used to learn policies for complex tasks from visual inputs, and have been applied with great success to classic Atari 2600 games. Recent work in this field has shown that it is possible to get super-human performance in many of them, even in challenging exploration regimes such as that exhibited by Montezuma’s Revenge. However, one of the limitations of many state-of-the-art approaches is that they require a very large number of interactions with the game environment, often much larger than what people would need to learn to play well. One plausible hypothesis explaining why people learn these tasks so much more efficiently is that they are able to predict the effect of their own actions, and thus implicitly learn a model of which action sequences will lead to desirable outcomes. This general idea—building a so-called model of the game and using it to learn a good policy for selecting actions—is the main premise of model-based reinforcement learning (MBRL).
In “Model-Based Reinforcement Learning for Atari“, we introduce the Simulated Policy Learning (SimPLe) algorithm, an MBRL framework to train agents for Atari gameplay that is significantly more efficient than current state-of-the-art techniques, and shows competitive results using only ~100K interactions with the game environment (equivalent to roughly two hours of real-time play by a person). In addition, we have open sourced our code as part of the tensor2tensor open source library. The release contains a pretrained world model that can be run with a simple command line and that can be played using an Atari-like interface.
Learning a SimPLe World Model
At a high-level, the idea behind SimPLe is to alternate between learning a world model of how the game behaves and using that model to optimize a policy (with model-free reinforcement learning) within the simulated game environment. The basic principles behind this algorithm are well established and have been employed in numerous recent model-based reinforcement learning methods.
 |
| Main loop of SimPLe. 1) The agent starts interacting with the real environment. 2) The collected observations are used to update the current world model. 3) The agent updates the policy by learning inside the world model. |
To train an Atari game playing model we first need to generate plausible versions of the future in pixel space. In other words, we seek to predict what the next frame will look like, by taking as input a sequence of already observed frames and the commands given to the game, such as “left”, “right”, etc. One of the important reasons for training a world model in observation space is that it is, in effect, a form of self-supervision, where the observations—pixels, in our case—form a dense and rich supervision signal.
If successful in training such a model (e.g. a video predictor), one essentially has a learned simulator of the game environment that can be used to generate trajectories for training a good policy for a gaming agent, i.e. choosing a sequence of actions such that long-term reward of the agent is maximized. In other words, instead of having the policy be trained on sequences from the real game, which is prohibitively intensive in both time and computation, we train the policy on sequences coming from the world model / learned simulator.
Our world model is a feedforward convolutional network that takes in four frames and predicts the next frame as well as the reward (see figure above). However, in the case of Atari, the future is non-deterministic given only a horizon of the previous four frames. For example, a pause in the game longer than four frames, such as when the ball falls out of the frame in Pong, can lead to a failure of the model to predict subsequent frames successfully. We handle stochasticity problems such as these with a new video model architecture that does much better in this setting, inspired by previous work.
At each iteration, after the world model is trained, we use this learned simulator to generate rollouts (i.e. sample sequences of actions, observations and outcomes) that are used to improve the game playing policy using the Proximal Policy Optimization (PPO) algorithm. One important detail for making SimPLe work is that the sampling of rollouts starts from the real dataset frames. Because prediction errors typically compound over time and make long-term predictions very difficult, SimPLe only uses medium-length rollouts. Luckily, the PPO algorithm can learn long-term effects between actions and rewards from its internal value function too, so rollouts of limited length are sufficient even for games with sparse rewards like Freeway.
SimPLe Efficiency
One measure of success is to demonstrate that the model is highly efficient. For this, we evaluated the output of our policies after 100K interactions with the environment, which corresponds to roughly two hours of real-time game play by a person. We compare our SimPLe method with two state of the art model-free RL methods, Rainbow and PPO, applied to 26 different games. In most cases, the SimPLe approach has a sample efficiency more than 2x better than the other methods.
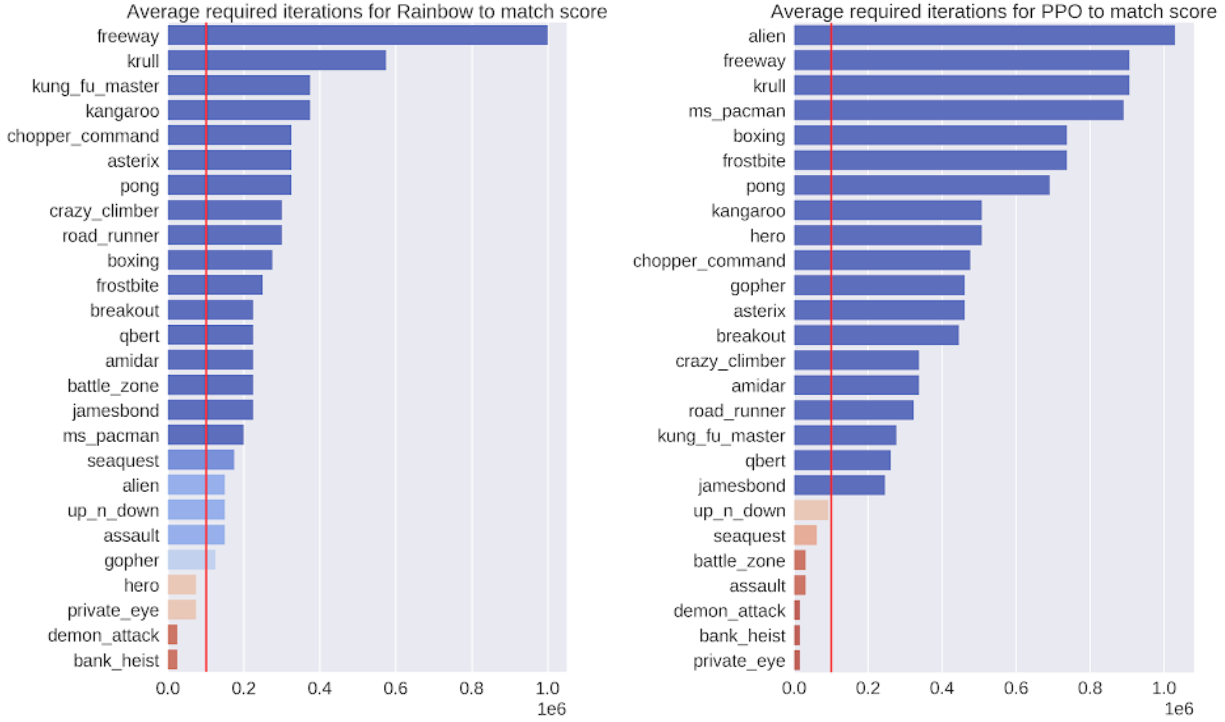 |
| The number of interactions needed by the respective model-free algorithms (left – Rainbow; right – PPO) to match the score achieved using our SimPLe training method. The red line indicates the number of interactions used by our method. |
SimPLe Success
An exciting result of the SimPLe approach is that for two of the games, Pong and Freeway, an agent trained in the simulated environment is able to achieve the maximum score. Here is a video of our agent playing the game using the game model that we learned for Pong:
For Freeway, Pong and Breakout, SimPLe can generate nearly pixel-perfect predictions up to 50 steps into the future, as shown below.
SimPLe Surprises
SimPLe does not always make correct predictions, however. The most common failure is due to the world model not accurately capturing or predicting small but highly relevant objects. Some examples are: (1) in Atlantis and Battlezone bullets are so small that they tend to disappear, and (2) Private Eye, in which the agent traverses different scenes, teleporting from one to the other. We found that our model generally struggled to capture such large global changes.
Conclusion
The main promise of model-based reinforcement learning methods is in environments where interactions are either costly, slow or require human labeling, such as many robotics tasks. In such environments, a learned simulator would enable a better understanding of the agent’s environment and could lead to new, better and faster ways for doing multi-task reinforcement learning. While SimPLe does not yet match the performance of standard model-free RL methods, it is substantially more efficient, and we expect future work to further improve the performance of model-based techniques.
If you’d like to develop your own models and experiments, head to our repository and colab where you’ll find instructions on how to reproduce our work along with pre-trained world models.
Acknowledgements
This work was done in collaboration with the University of Illinois at Urbana-Champaign, the University of Warsaw and deepsense.ai. We would like to give special recognition to paper co-authors Mohammad Babaeizadeh, Piotr Miłos, Błażej Osiński, Roy H Campbell, Konrad Czechowski, Chelsea Finn, Piotr Kozakowski, Sergey Levine, Ryan Sepassi, George Tucker and Henryk Michalewski.
