AWS DeepLens is a deep-learning-enabled video camera for developers. It enables you to expand your deep learning skillsets through the use of a fully programmable video camera, tutorials, code, and pre-trained models.
The goal with this blog post is to show you how to get started with the AWS DeepLens and how this device facilitates the introduction of IoT and Deep Learning, putting it the hands of developers. In this blog post, we’ll show you how to build a simple face detection application that counts the number of cups of coffee that people drink and displays the tally on a leaderboard.
We will go through the following steps:
- Step 1: Deploy a sample project
- Step 2: Change the inference AWS Lambda function
- Step 3: Create a coffee detection backend
- Step 4: Deploy the app to AWS Elastic Beanstalk
Project Overview
Let’s review the following architectural diagram for the project. The AWS DeepLens device enables you to run deep learning on the edge. It detects a scene and runs it against a face detection model.
When the model detects a face, it uploads a frame to Amazon S3. An AWS Lambda function then runs the frame against AWS Rekognition to detect a mug in the scene and check if a face has been detected before or if is it a new face. After a face is registered or recognized, it’s stored in Amazon DynamoDB, which is used as an incremental counter for a web application.

Following this post, you’ll be able to replicate the architecture and get the necessary information to build an application like this.

Step 1: Deploy a sample project
To deploy the project you first need to register the AWS DeepLens device, if you haven’t already. See Register Your AWS DeepLens Device for more information.
For the project type, make sure Use a project template is highlighted and select Face detection from the project templates.

From there you can specify the project name and add a description, leave everything else at the default, and choose Create.
2) After the project is created, we need to deploy it to the AWS DeepLens device. On the Projects page, select your project name, and then choose Deploy to device. On the target device page, select your registered AWS DeepLens device.
Choose Review.

After you have reviewed, finalize by choosing Deploy.
3) Navigate to the IAM console. Add permissions for AmazonS3FullAccess to AWSDeepLensGreengrassGroupRole.

Next you need to make sure that the project was successfully deployed. Connect the AWS DeepLens device to a monitor, mouse, and keyboard. Sign in to the device using the password that you set when you registered the device.
Start your terminal and run the following command:
mplayer —demuxer lavf -lavfdopts format=mjpeg:probesize=32 /tmp/results.mjpeg
This command shows the project stream. You will now see each frame being run against the model as the inference Lambda function is processed.
Step 2: Change the inference Lambda function
After you deploy the sample project, you need to change the inference Lambda function running on the device to upload images to Amazon S3. For this use case, we also added some messages on the screen to make the process more intuitive.
1) Create an Amazon S3 bucket where the images will be uploaded. Use the default settings when setting up the bucket and choose the same AWS Region as the rest of your infrastructure.
2) Go to the AWS Lambda console and open the deeplens-face-detection function. Remove the function code and replace it with the lambda_inference code here. (Replace the bucket_name variable with your bucket name.)
With this step, we are changing the code to upload images to Amazon S3 when a face is detected. Plus we are adding features such as a cooldown period between uploads and a countdown before taking a picture.
3) Save the AWS Lambda function and publish a new version of the code. This allows you to go to your AWS DeepLens project and update the function on the device.

Access your project in the AWS DeepLens console and edit the project updating the version of your AWS Lambda function and the timeout to 600 seconds:

4) Redeploy the project to the device by selecting the project and choosing Deploy.

You should also install botocore to the AWS DeepLens by using this command:
sudo -H pip install botocore
This allows the frame to be uploaded to S3.
Step 3: Create a coffee detection backend
To recognize faces, we will use Amazon Rekognition collections. A collection is a container for persisting faces detected by the IndexFaces API action. Amazon Rekognition doesn’t store copies of the analyzed images. Instead, it stores face feature vectors as the mathematic representation of a face within the collection.
You can use the facial information in a collection to search for known faces in images, stored videos, and streaming videos.
To create a collection you will first need to configure the AWS CLI:
- Install the AWS CLI.
- Configure the AWS CLI.
1) Create an empty Amazon Rekognition collection using this CLI command:
aws rekognition create-collection --collection-id "Faces" --region us-east-1
2) Now, we are going to create an Amazon DynamoDB table for storing unique face feature vectors generated by Amazon Rekognition and the number of coffees each person had.
DynamoDB works well for this use case. As a fully managed service, you don’t need to worry about the elasticity and scalability of the database because there is no limit to the amount of data that can be stored in a DynamoDB table. As the size of the data set grows, DynamoDB automatically spreads the data over sufficient machine resources to meet storage requirements. If you weren’t using DynamoDB, the incremental count added to the table would require you to scale accordingly. As for pricing, with DynamoDB you only pay for the resources you provision. For this use case, though, it is quite possible to remain within the AWS Free Tier pricing model or have the project running at a low DynamoDB price point.
To create the table in DynamoDB, in the AWS Management Console, navigate to the DynamoDB console and create a table. Use Faces as the table name and faceID as the primary key, and leave the other settings as defaults.
We’ll also create a table named logs for storing the logs of your Lambda function. For this table use unixtime as the primary key.
3) Create an AWS Lambda function that calls Amazon Rekognition. First, go to the IAM console and create a role for AWS Lambda function. Apply the following managed policies to this role:
- AmazonRekognitionFullAccess
- AmazonDynamoDBFullAccess
- AmazonS3FullAccess
- AWSLambdaExecute
You should follow AWS IAM best practices for production implementations.
4) Finally, navigate to the Lambda console. Create a Lambda function with Python 3.6 as a runtime. Set the name of the S3 bucket that you configured before as your Lambda trigger. Configure the Event type, Prefix, and Suffix as shown in the following screenshot. This ensures that your Lambda function is triggered only when new .jpg objects that start with a key matching the images/ pattern are created within the bucket.

Replace the template Lambda code with the code you downloaded from GitHub. Modify the Lambda timeout to 1 minute.
Copy the code from the GitHub repository and paste in in the code box. Let’s inspect the Lambda code to understand what it’s doing:
response = rekognition.detect_labels(Image=image, MaxLabels=123, MinConfidence=50)
for object in response["Labels"]:
if object["Name"] == "Coffee Cup" or object["Name"] == "Cup":
coffee_cup_detected = True
break
::
message = detect_faces(image, bucket, key)
This part of code uses AWS Rekognition to detect the labels in the image. It checks if “Cup” or “Coffee Cup” is found in a response. If it finds any of these labels, it calls a face detection function, which searches the face collection to find if there is a matching face:
faces = rekognition.search_faces_by_image(CollectionId=face_collection, Image=image,
FaceMatchThreshold=face_match_threshold, MaxFaces=1)
If no matching faces are found in the collection, the face is indexed and added to the collection:
faces = rekognition.index_faces(Image=image, CollectionId=face_collection)
To test the function, you can upload an image to your S3 bucket and check your DynamoDB table to see the result.
Step 4: Deploy the app to AWS Elastic Beanstalk
Now it’s time to deploy the leaderboard application using AWS Elastic Beanstalk. Elastic Beanstalk automatically orchestrates the required resources needed to deploy the web application. All you have to do is upload the code.
1) Go to the IAM console, and on the IAM roles page, attach the AmazonS3FullAccess and DynamoDBFullAccess managed policies to the aws-elasticbeanstalk-ec2-role. This allows Amazon EC2 instances provisioned by Elastic Beanstalk to access Amazon S3 and Amazon DynamoDB.
2) Go to the AWS Elastic Beanstalk console, and create a new application. Create a new web server environment. Enter a domain name, select Python as a platform, and upload a ZIP file from GitHub that includes the Flask application and requirements.txt file. Wait until Elastic Beanstalk provisions your environment.

The URL of your application should be visible on the top of your screen. Click the URL to view your coffee leaderboard!
Important: Deploying a project incurs costs for the various AWS services that are used.
Conclusion
You are now able to track the number of coffees each individual person drinks. While this project focuses on a simple coffee leaderboard, the backbone of this architecture can be used for any application.
This project showcases the power of the AWS DeepLens device in introducing developers to machine learning and IoT. Using a combination of AWS services, we were able to build this app in a short amount of time, and so can you!
About the Authors
 João Coelho is a Solutions Architect at Amazon Web Services in London. He helps customers leverage the AWS platform to build scalable and resilient architectures on the cloud and is especially interested in serverless technologies. Outside of work, he enjoys playing tennis and traveling.
João Coelho is a Solutions Architect at Amazon Web Services in London. He helps customers leverage the AWS platform to build scalable and resilient architectures on the cloud and is especially interested in serverless technologies. Outside of work, he enjoys playing tennis and traveling.
 Laurynas Tumosa is a Technical Researcher at AWS in London. He enjoys building on the platform using AWS Machine Learning Services. He is passionate about making AI technologies accessible for everyone. Outside of work, Laurynas enjoys finding new interesting podcasts, playing guitar, and reading.
Laurynas Tumosa is a Technical Researcher at AWS in London. He enjoys building on the platform using AWS Machine Learning Services. He is passionate about making AI technologies accessible for everyone. Outside of work, Laurynas enjoys finding new interesting podcasts, playing guitar, and reading.
 Lalit Dayalani is a Solution Architect at Amazon Web Services based in London. He helps AWS customers to provide guidance and technical assistance helping them understand and improve the value of their solutions on AWS. In his spare time, he loves spending time with family, going on hikes and spends way too much time indulging in too much television.
Lalit Dayalani is a Solution Architect at Amazon Web Services based in London. He helps AWS customers to provide guidance and technical assistance helping them understand and improve the value of their solutions on AWS. In his spare time, he loves spending time with family, going on hikes and spends way too much time indulging in too much television.
 Can Balioglu is a Software Development Engineer on the AWS AI Algorithms team where he is specialized in high-performance computing. In his spare time he loves to play with his homemade GPU cluster.
Can Balioglu is a Software Development Engineer on the AWS AI Algorithms team where he is specialized in high-performance computing. In his spare time he loves to play with his homemade GPU cluster. Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.
Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.


 Denis Davydenko is an Engineering Manager with AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys spending time with his family, playing poker and video games.
Denis Davydenko is an Engineering Manager with AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys spending time with his family, playing poker and video games. Frank Liu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking with friends and family.
Frank Liu is a Software Engineer for AWS Deep Learning. He focuses on building innovative deep learning tools for software engineers and scientists. In his spare time, he enjoys hiking with friends and family. Vamshidhar Dantu is a Software Developer with AWS Deep Learning. He focuses on building scalable and easily deployable deep learning systems. In his spare time, he enjoy spending time with family and playing badminton.
Vamshidhar Dantu is a Software Developer with AWS Deep Learning. He focuses on building scalable and easily deployable deep learning systems. In his spare time, he enjoy spending time with family and playing badminton. Rakesh Vasudevan is a Software Development Engineer with AWS Deep Learning. He is passionate about building scalable deep learning systems. In spare time, he enjoys gaming, cricket and hanging out with friends and family.
Rakesh Vasudevan is a Software Development Engineer with AWS Deep Learning. He is passionate about building scalable deep learning systems. In spare time, he enjoys gaming, cricket and hanging out with friends and family.
 Chander Matrubhutam is a principal product marketing manager at AWS, helping customers understand and adopt deep learning.
Chander Matrubhutam is a principal product marketing manager at AWS, helping customers understand and adopt deep learning. Yoni Friedman is a Sr. Technical Product Manager in the AWS Artificial Intelligence team where he leads product management for Amazon Translate. He spends his free time reading, running, playing ball, and doing other stuff his two toddlers ask him to.
Yoni Friedman is a Sr. Technical Product Manager in the AWS Artificial Intelligence team where he leads product management for Amazon Translate. He spends his free time reading, running, playing ball, and doing other stuff his two toddlers ask him to.








 Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS.
Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS. Urvashi Chowdhary is a Senior Product Manager for Amazon SageMaker. She is passionate about working with customers and making machine learning more accessible. In her spare time, she loves sailing, paddle boarding, and kayaking.
Urvashi Chowdhary is a Senior Product Manager for Amazon SageMaker. She is passionate about working with customers and making machine learning more accessible. In her spare time, she loves sailing, paddle boarding, and kayaking. Jeffrey Geevarghese is a Senior Engineer in Amazon AI where he’s passionate about building scalable infrastructure for deep learning. Prior to this he was working on machine learning algorithms and platforms and was part of the launch teams for both Amazon SageMaker and Amazon Machine Learning.
Jeffrey Geevarghese is a Senior Engineer in Amazon AI where he’s passionate about building scalable infrastructure for deep learning. Prior to this he was working on machine learning algorithms and platforms and was part of the launch teams for both Amazon SageMaker and Amazon Machine Learning.

















 Tristan Li is a Solutions Architect with Amazon Web Services. He works with enterprise customers in the US, helping them adopt cloud technology to build scalable and secure solutions on AWS.
Tristan Li is a Solutions Architect with Amazon Web Services. He works with enterprise customers in the US, helping them adopt cloud technology to build scalable and secure solutions on AWS. Grant McCarthy is an Enterprise Solutions Architect with Amazon Web Services, based in Charlotte, NC. His primary role is assisting his customers move workloads to the cloud securely and ensuring that the workloads are architected in way that aligns with AWS best practices.
Grant McCarthy is an Enterprise Solutions Architect with Amazon Web Services, based in Charlotte, NC. His primary role is assisting his customers move workloads to the cloud securely and ensuring that the workloads are architected in way that aligns with AWS best practices.

 Woo Kim is a Product Marketing Manager for AWS machine learning services. He spent his childhood in South Korea and now lives in Seattle, WA. In his spare time, he enjoys playing volleyball and tennis.
Woo Kim is a Product Marketing Manager for AWS machine learning services. He spent his childhood in South Korea and now lives in Seattle, WA. In his spare time, he enjoys playing volleyball and tennis.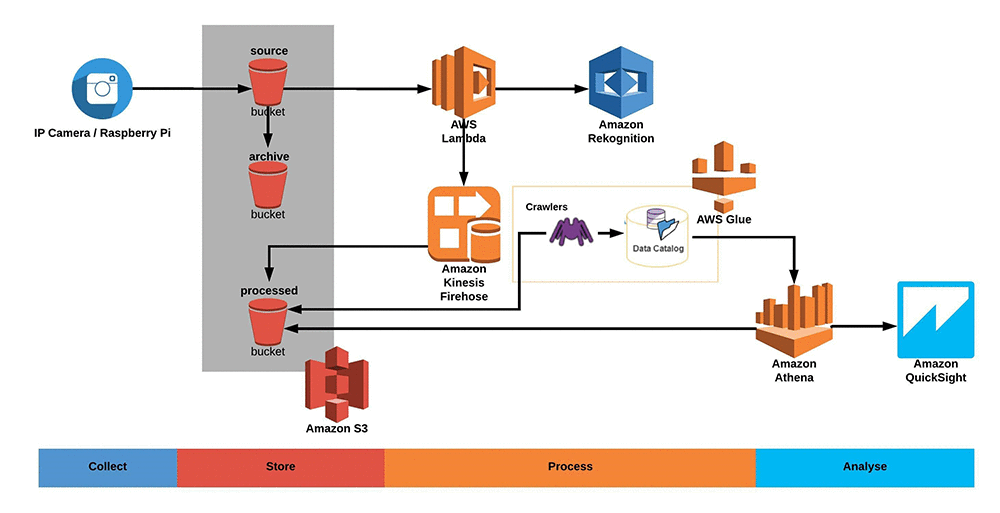













 Bastien Leblanc is a Solutions Architect with AWS. He helps Retail customers adopt the AWS Platform, focusing on Data & Analytics workloads, he likes to work with customers helping to solve retail problems and drive innovation.
Bastien Leblanc is a Solutions Architect with AWS. He helps Retail customers adopt the AWS Platform, focusing on Data & Analytics workloads, he likes to work with customers helping to solve retail problems and drive innovation. Imran Dawood is a Solutions Architect with AWS. He works with Retail customers helping them build solutions on AWS with architectural guidance to achieve success in the AWS cloud. In his spare time, Imran enjoys playing table tennis and spending time with family.
Imran Dawood is a Solutions Architect with AWS. He works with Retail customers helping them build solutions on AWS with architectural guidance to achieve success in the AWS cloud. In his spare time, Imran enjoys playing table tennis and spending time with family.