A Peek at Trends in Machine Learning
Have you looked at Google Trends? It’s pretty cool — you enter some keywords and see how Google Searches of that term vary through time. I thought — hey, I happen to have this arxiv-sanity database of 28,303 (arxiv) Machine Learning papers over the last 5 years, so why not do something similar and take a look at how Machine Learning research has evolved over the last 5 years? The results are fairly fun, so I thought I’d post.
(Edit: machine learning is a large area. A good chunk of this post is about deep learning specifically, which is the subarea I am most familiar with.)
The arxiv singularity
Let’s first look at the total number of submitted papers across the arxiv-sanity categories (cs.AI,cs.LG,cs.CV,cs.CL,cs.NE,stat.ML), over time. We get the following:
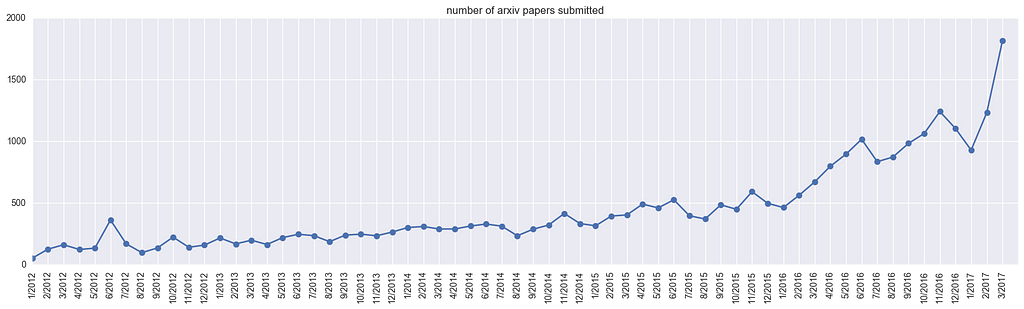
Yes, March of 2017 saw almost 2,000 submissions in these areas. The peaks are likely due to conference deadlines (e.g. NIPS/ICML). Note that this is not directly a statement about the size of the area itself, since not everyone submits their paper to arxiv, and the fraction of people who do likely changes over time. But the point remains — that’s a lot of papers to be aware of, skim, or (gasp) read.
This total number of papers will serve as the denominator. We can now look at what fraction of papers contain certain keywords of interest.
Deep Learning Frameworks
To warm up let’s look at the Deep Learning frameworks that are in use. To compute this, we record the fraction of papers that mention the framework somewhere in the full text (anywhere — including bibliography etc). For papers uploaded on March 2017, we get the following:
% of papers framework has been around for (months)
------------------------------------------------------------
9.1 tensorflow 16
7.1 caffe 37
4.6 theano 54
3.3 torch 37
2.5 keras 19
1.7 matconvnet 26
1.2 lasagne 23
0.5 chainer 16
0.3 mxnet 17
0.3 cntk 13
0.2 pytorch 1
0.1 deeplearning4j 14
That is, 10% of all papers submitted in March 2017 mention TensorFlow. Of course, not every paper declares the framework used, but if we assume that papers declare the framework with some fixed random probability independent of the framework, then it looks like about 40% of the community is currently using TensorFlow (or a bit more, if you count Keras with the TF backend). And here is the plot of how some of the more popular frameworks evolved over time:
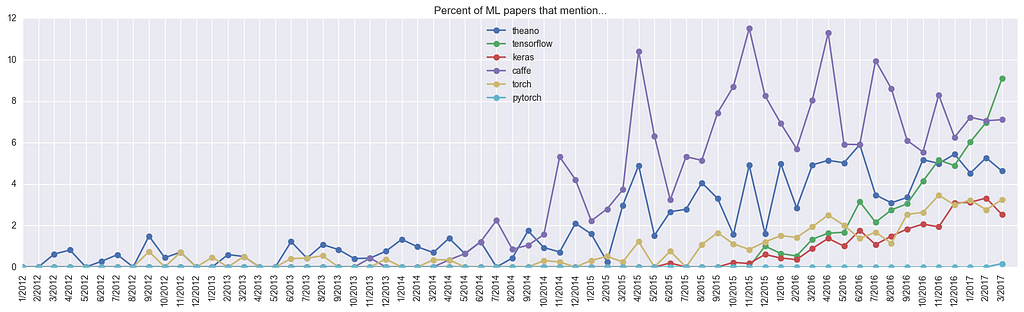
We can see that Theano has been around for a while but its growth has somewhat stalled. Caffe shot up quickly in 2014, but was overtaken by the TensorFlow singularity in the last few months. Torch (and the very recent PyTorch) are also climbing up, slow and steady. It will be fun to watch this develop in the next few months — my own guess is that Caffe/Theano will go on a slow decline and TF growth will become a bit slower due to PyTorch.
ConvNet Models
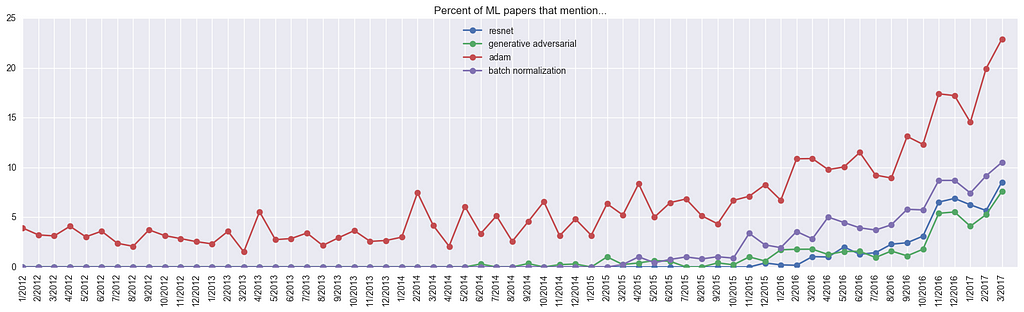
For fun, how about if we look at common ConvNet models? Here, we can clearly see a huge spike up for ResNets, to the point that they occur in 9% of all papers last March:
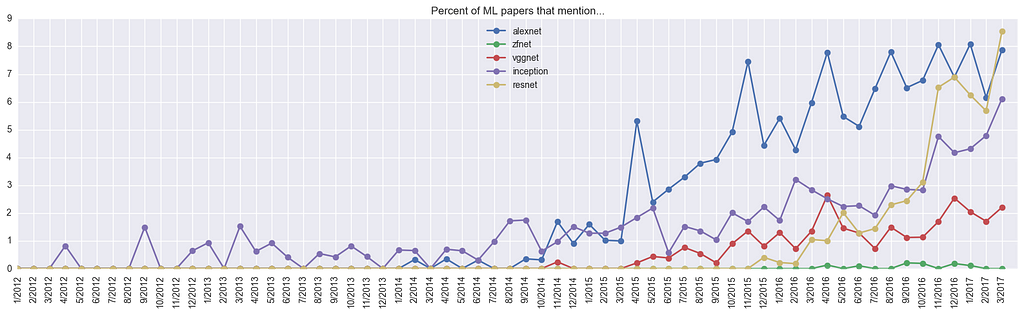
Also, who was talking about “inception” before the InceptionNet? Curious.
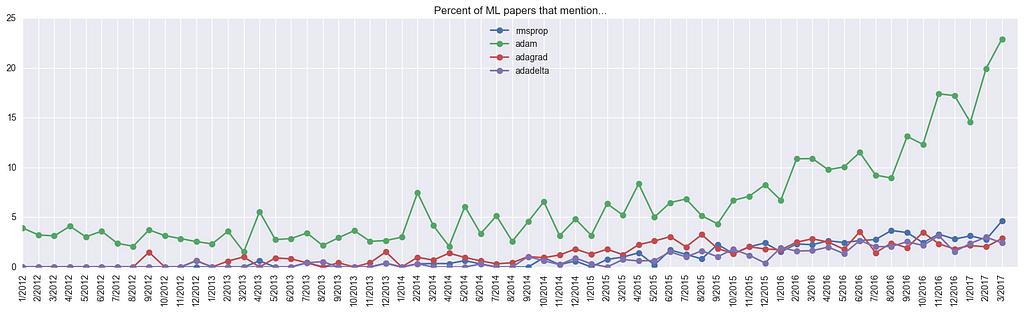
Optimization algorithms
In terms of optimization algorithms, it looks like Adam is on a roll, found in about 23% of papers! The actual fraction of use is hard to estimate; it’s likely higher than 23% because some papers don’t declare the optimization algorithm, and a good chunk of papers might not even be optimizing any neural network at all. It’s then likely lower by about 5%, which is the “background activity” of “Adam”, likely a collision with author names, as the Adam optimization algorithm was only released on Dec 2014.
Researchers
I was also curious to plot the mentions of some of the most senior PIs in Deep Learning (this gives something similar to citation count, but 1) it is more robust across population of papers with a “0/1” count, and 2) it is normalized by the total size of the pie):
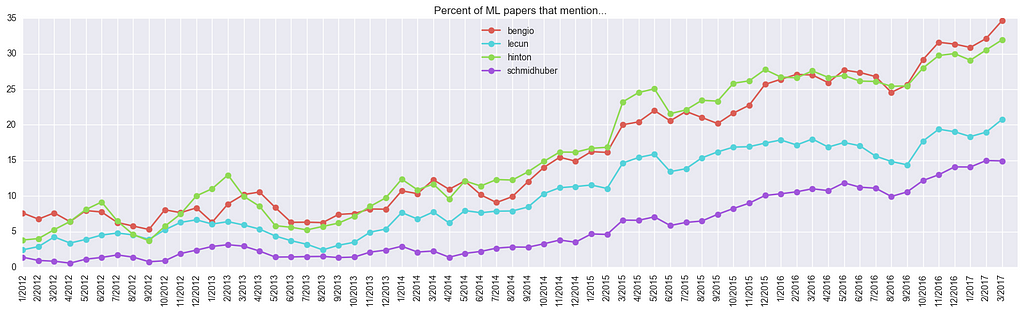
A few things to note: “bengio” is mentioned in 35% of all submissions, but there are two Bengios: Samy and Yoshua, who add up on this plot. In particular, Geoff Hinton is mentioned in more than 30% of all new papers! That seems like a lot.
Hot or Not Keywords
Finally, instead of manually going by categories of keywords, let’s actively look at the keywords that are “hot” (or not).
Top hot keywords
There are many ways to define this, but for this experiment I look at each unigram or bigram in all the papers and record the ratio of its max use last year compared to its max use up to last year. The papers that excel at this metric are those that one year ago were niche, but this year appear with a much higher relative frequency. The top list (slightly edited out some duplicates) comes out as follows:
8.17394726486 resnet
6.76767676768 tensorflow
5.21818181818 gans
5.0098386462 residual networks
4.34787878788 adam
2.95181818182 batch normalization
2.61663993305 fcn
2.47812783318 vgg16
2.03636363636 style transfer
1.99958217686 gated
1.99057177616 deep reinforcement
1.98428686543 lstm
1.93700787402 nmt
1.90606060606 inception
1.8962962963 siamese
1.88976377953 character level
1.87533998187 region proposal
1.81670721817 distillation
1.81400378481 tree search
1.78578069795 torch
1.77685950413 policy gradient
1.77370153867 encoder decoder
1.74685427385 gru
1.72430399325 word2vec
1.71884293052 relu activation
1.71459655485 visual question
1.70471560525 image generation
For example, ResNet’s ratio of 8.17 is because until 1 year ago it appeared in up to only 1.044% of all submissions (in Mar 2016), but last last month (Mar 2017) it appeared in 8.53% of submissions, so 8.53 / 1.044 ~= 8.17. So there you have it — the core innovations that became all the rage over the last year are 1) ResNets, 2) GANs, 3) Adam, 4) BatchNorm. Use more of these to fit in with your friends. In terms of research interests, we see 1) style transfer, 2) deep RL, 3) Neural Machine Translation (“nmt”), and perhaps 4) image generation. And architecturally, it is hot to use 1) Fully Convolutional Nets (FCN), 2) LSTMs/GRUs, 3) Siamese nets, and 4) Encoder decoder nets.
Top not hot
How about the reverse? What has seen many fewer submissions over the last year than has historically had a higher “mind share”? Here are a few:
0.0462375339982 fractal
0.112222705524 learning bayesian
0.123531424661 ibp
0.138351983723 texture analysis
0.152810895084 bayesian network
0.170535340862 differential evolution
0.227932960894 wavelet transform
0.24482875551 dirichlet process
I’m not sure what “fractal” is referring to, but more generally it looks like bayesian nonparametrics are under attack.
Conclusion
Now is the time to submit paper on Fully Convolutional Encoder Decoder BatchNorm ResNet GAN applied to Style Transfer, optimized with Adam. Hey, that doesn’t even sound too far-fetched.
🙂